LLM Pruner
1.0.0
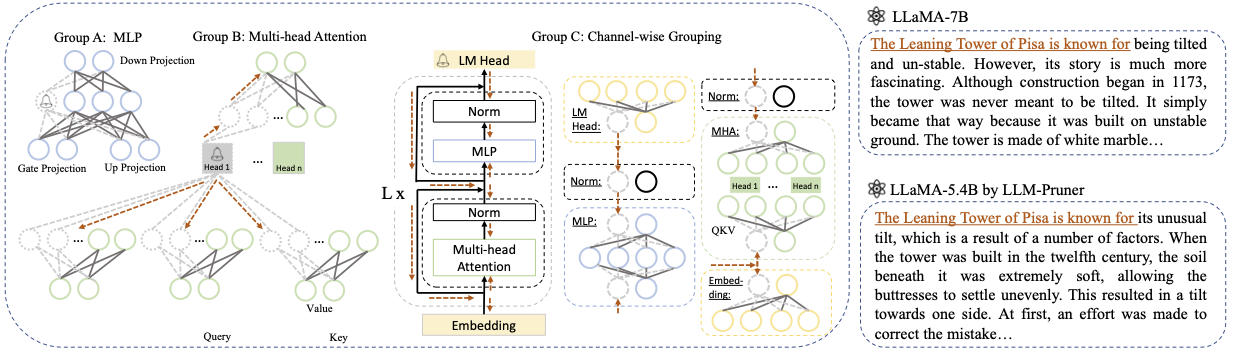
LLM-Pruner:大規模な言語モデルの構造的剪定について[arxiv]
Xinyin MA、Gongfan Fang、Xinchao Wang
シンガポール国立大学
.from_pretrained() 。 チャットのためにWeChatグループに参加してください:
pip install -r requirement.txt
bash script/llama_prune.sh
このスクリプトは、剪定された20%のパラメーターでllama-7bモデルを圧縮します。事前に訓練されたすべてのモデルとデータセットが自動的にダウンロードされるため、リソースを手動でダウンロードする必要はありません。このスクリプトを初めて実行するとき、モデルとデータセットをダウンロードするのに時間がかかります。
LLMを剪定するには3つのステップが必要です。
剪定と訓練後の後、評価のためにLM評価ハーネスに従って進みます。
? llama/llama-2剪定〜20%パラメーターを剪定:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
議論:
Base model :LlamaまたはLlama-2からベースモデルを選択し、 pretrained_model_name_or_pathを--base_modelに渡します。モデル名は、 AutoModel.from_pretrainedに使用され、事前に訓練されたLLMをロードします。たとえば、130億個のパラメーターでllama-2を使用する場合は、 meta-llama/Llama-2-13b-hf --base_modelに渡します。Pruning Strategy :それぞれのコマンドオプションを使用して、ブロックごとの、チャネルごとの、またはレイヤーごとの剪定を選択します:{--block_wise}、{--channel_wise}、{ - layer_wise - layer number_of_layers}。ブロックごとの剪定の場合は、剪定する開始層と端の層を指定します。チャネルごとの剪定には、追加の引数は必要ありません。レイヤープルーニングの場合、-layer number_of_layersを使用して、剪定後に保持する必要のあるレイヤー数を指定します。Importance Criterion :-pruner_type引数を使用して、L1、L2、ランダム、またはTaylorから選択します。 Taylor Prunerの場合、次のオプションのいずれかを選択します:Vectorize、param_second、param_first、param_mix。デフォルトでは、PARAM_MIXが使用されます。これは、近似された2次ヘシアンと1次勾配を組み合わせたものです。 L1、L2、またはランダムを使用している場合、追加の引数は必要ありません。Pruning Ratio :グループの剪定比を指定します。グループは最小単位として削除されるため、パラメーターの剪定速度とは異なります。DeviceとEval_device :剪定と評価は、さまざまなデバイスで実行できます。テイラーベースの方法では、剪定中に逆方向計算が必要であり、重要なGPU RAMが必要になる場合があります。私たちの実装では、重要度の推定にCPUを使用します(GPUもサポートし、単純に-device cudaを使用します)。 eval_deviceは、プルーニングモデルのテストに使用されます。 Vicunaを試してみたい場合は、Vicuna Weightへのパスへの引数--base_modelを指定してください。 https://github.com/lm-sys/fastchatをフォローして、Vicunaの重量を得てください。
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
詳細については、例/baichuanを参照してください
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
PATH_TO_PRUNE_MODELをステップ1の剪定モデルへのパスに置き換え、 PATH_TO_SAVE_TUNE_MODELチューニングモデルを保存する目的の場所に置き換えてください。
ヒント:float16でのトレーニングラマ2は推奨されず、NANを生成することが知られています。そのため、モデルはBFLOAT16でトレーニングする必要があります。
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
剪定されたモデルの場合、次のコマンドを使用してモデルをロードしてください。
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
特定のレイヤーが幅が大きくなる可能性があるが、他のレイヤーがより多くのプルーニングを受けた可能性がある剪定モデルのモジュール間の構成が異なるため、顔を抱きしめることで提供されているように.from_pretrained()を使用してモデルをロードすることは非現実的になります。現在、剪定モデルを保存するためにtorch.saveを使用しています。
いくつかのレイヤーが広くなっているように、プルーニングモデルは各レイヤーに異なる構成を持っているため、一部のレイヤーはさらに剪定されているため、モデルにはhugging顔の.from_pretrained()をロードすることはできません。現在、 torch.saveを使用して剪定されたモデルを保存し、 torch.loadて剪定モデルをロードします。
トレーニング後の事前に訓練された /プルーニングモデル /プルーニングモデルを使用して、テキストをジェネートする簡単なスクリプトを提供します。
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
上記の指示は、LLMをローカルに展開します。
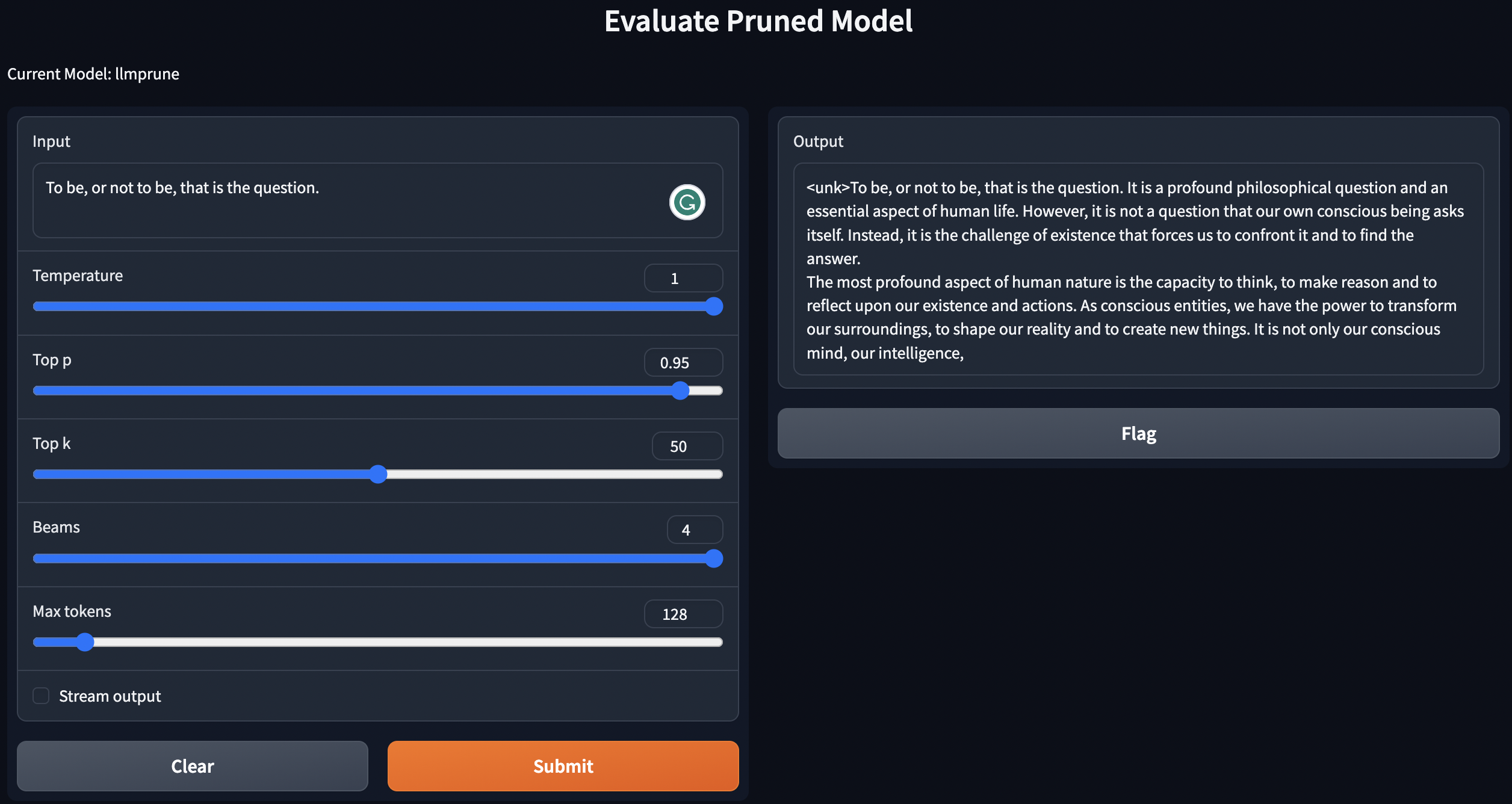
剪定モデルのパフォーマンスを評価するために、LM評価ハーネスに従ってモデルを評価します。
lm-evaluation-harnessの入力要件を満たすためにファイルをアレンジすることです。トレーニング後のステップからの調整されたチェックポイントは、次の形式で保存されます。 - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
次のコマンドでファイルを配置します。
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
checkpoint-200評価する場合は、 export epoch=200でエポック等量を200に設定します。
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
ここでは、 PATH_TO_PRUNE_MODELとPATH_TO_SAVE_TUNE_MODELをPATH_OR_NAME_TO_BASE_MODELを保存するパスに置き換えます。
[更新]:調整されたチェックポイントを使用して剪定されたモデルを評価する場合は、スクリプトを単純に評価プロセスにアップロードします。次のコマンドを使用するだけです。
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
コマンド内のモデルの必要な情報を置き換えます。最後の1つは、1つのコマンドでいくつかのチェックポイントを評価する場合、異なるエポックを反復するために使用されます。例えば:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
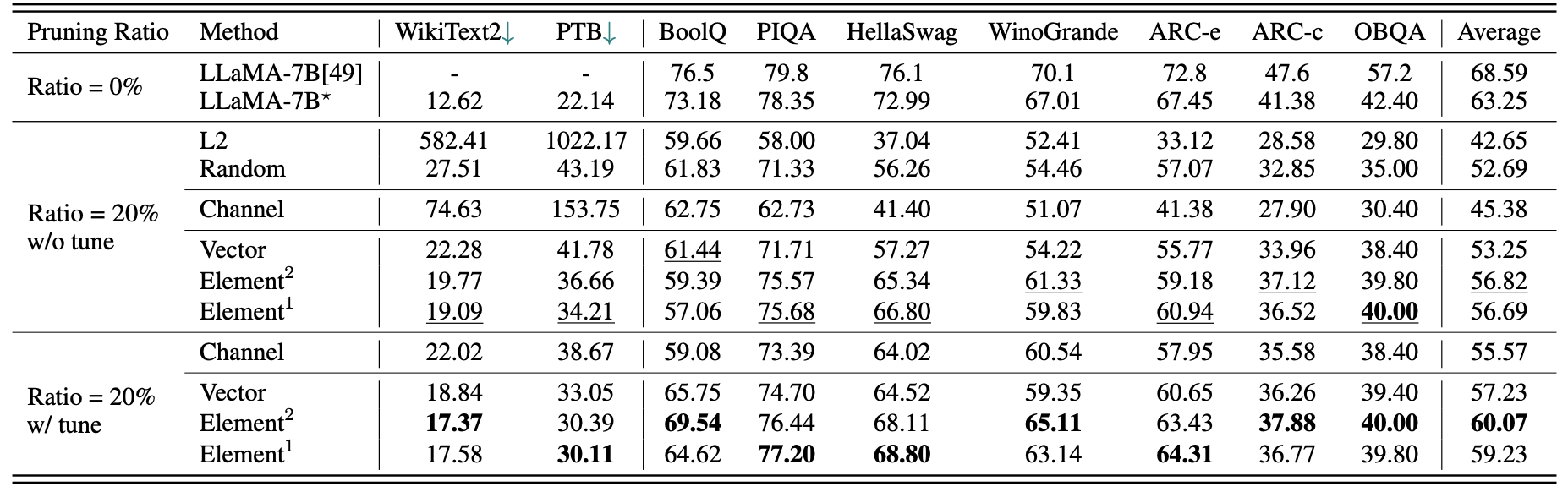
llama-7bの簡単な定量的結果:
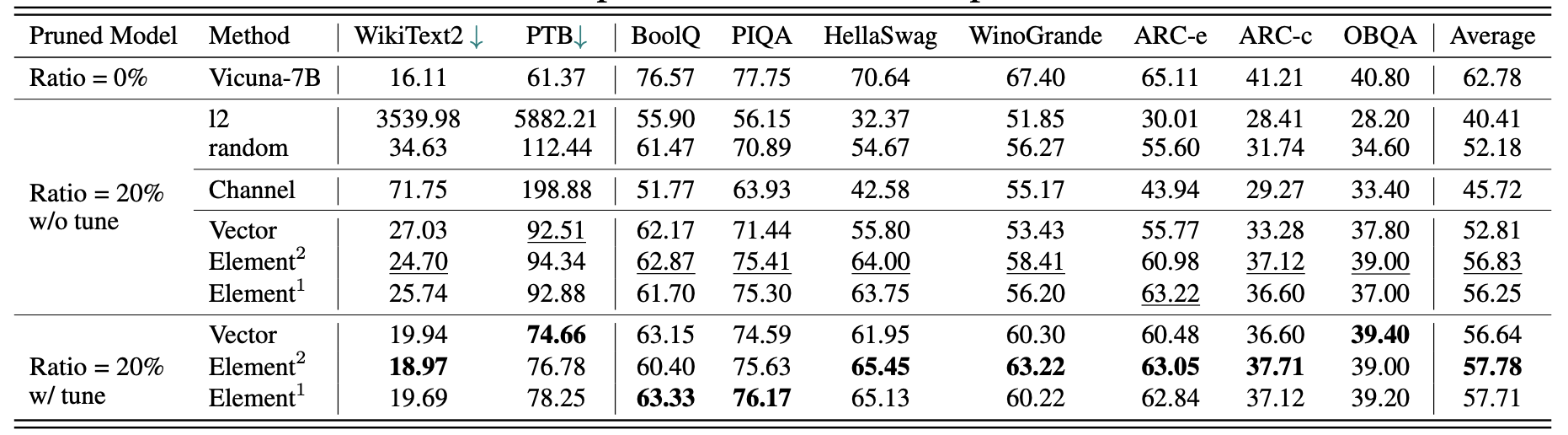
Vicuna-7Bの結果:
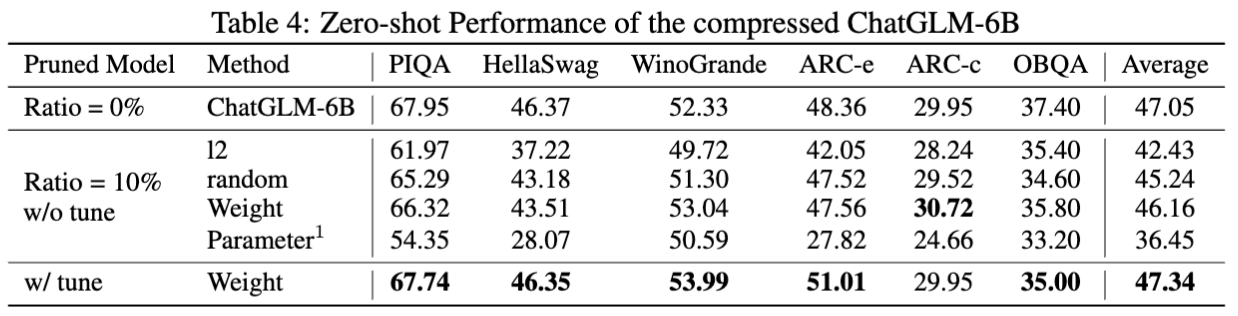
chatglm-6bの結果:
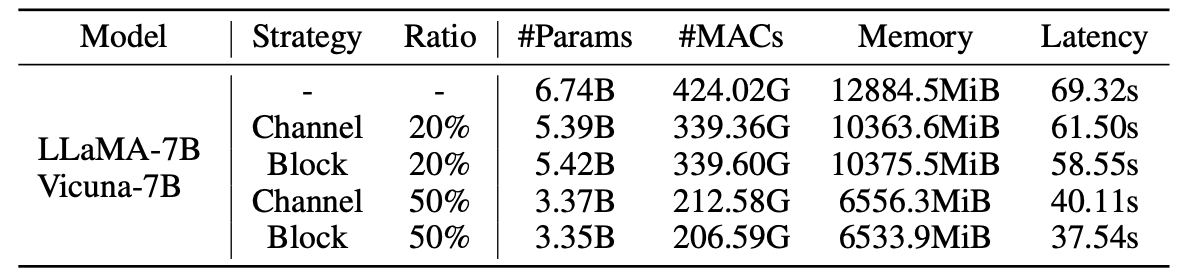
剪定モデルの統計:
2.59mのサンプルを備えたLLM-Prunerの結果:
| 剪定比 | #param | メモリ | 遅延 | スピードアップ | ブールク | ピカ | Hellaswag | ウィノグランデ | arc-e | ARC-C | obqa | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| llama-7b | 6.74b | 12884.5mib | 69.32s | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| llama-5.4bとアルパカ(50k) | 5.47b | 10488.4mib | 58.55S | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| ラミニ付きllama-5.4b(2.59m) | 5.47b | 10488.4mib | 58.55S | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40.70 | 38.80 | 62.36 |
より多くの結果が論文にあります。
| オリジナルモデル | 出力 | 剪定モデル | 出力 |
|---|---|---|---|
| llama-7b | 宇宙は、存在する空間、時間、物質、エネルギーの全体です。目に見えるかどうかにかかわらず、すべての物質とエネルギーが含まれ、実際には宇宙全体が見えません。その起源と究極の運命に関する多くの理論があります... | llama-5.4b | 宇宙は、存在する空間、時間、物質、エネルギーの全体です。物理学を構成する法則 - 原子を周回する電子、他の物体を引き付ける磁石、太陽を周回する惑星 - は一貫しています... |
| Vicuna-7b | iOSアプリを構築するための10のステップ:1。アイデアを調査して開発します。 2。使用するプラットフォーム(iOS、Android、またはその両方)を決定します。 3.計画と予算を作成します。 4。開発者チームを雇います。 5.ユーザーインターフェイス(UI)を設計します。 6.ユーザーインターフェイス(UI)を開発します。 7.アプリでテストして反復します。 8。アプリをApp Storeに送信します。 9。パフォーマンスとユーザーエクスペリエンス(UX)のためにアプリを最適化します。 10。アプリを市場と宣伝します。 | Vicuna-5.4b | iOSアプリを構築するための10のステップ:1。アプリを計画します:それが何をすべきか、それがどのように見えるか、それがそれを構築するのにかかるものを決定します。 2。開発者を雇う:優れたiOS開発者は、ユーザーインターフェイスを設計し、アプリを作成し、バグがないことを確認するのに役立ちます。 3。ユーザーインターフェイスを作成します:これが魔法が発生する場所です。アプリのユーザーインターフェイスは、この時点で設計およびock笑されます... |
| chatglm-6b | 愛と平和について詩を書いてください。人生のh騒の中で、私はあなたの愛がなだめるような平和だと思います。それは伝えられない感覚であり、距離を置くことができない接続です。あなたの笑顔、あなたの目、あなたの抱擁で、私はあなただけが与えることができる帰属意識を感じます。それは永遠に続く愛であり、敗北することはできない愛です... | chatglm-5.6b | 愛と平和について詩を書いてください。愛と平和、2つのそのような素晴らしいもの私の心の純粋で無限の欲望とその両方で、私は長い間、長い時間を求めなければなりません。 |
このプロジェクトで使用されているモデルとレポのバージョンの変更により、いくつかの既知のバージョンの問題と、メソッドを再現するために必要な特定のバージョンをリストしました。
このプロジェクトが役立つ場合は、引用してください
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


