LLM Pruner
1.0.0
LLM-PRUNER: Sobre a poda estrutural de grandes modelos de linguagem [arxiv]
Xinyin ma, gongfan fang, xinchao wang
Universidade Nacional de Cingapura
.from_pretrained() para carregar o modelo. Junte -se ao nosso grupo WeChat para um bate -papo:
pip install -r requirement.txt
bash script/llama_prune.sh
Esse script comprimiria o modelo LLAMA-7B com ~ 20% de parâmetros podados. Todos os modelos pré-treinados e o conjunto de dados seriam baixados automaticamente, para que você não precise baixar manualmente o recurso. Ao executar este script pela primeira vez, será necessário algum tempo para baixar o modelo e o conjunto de dados.
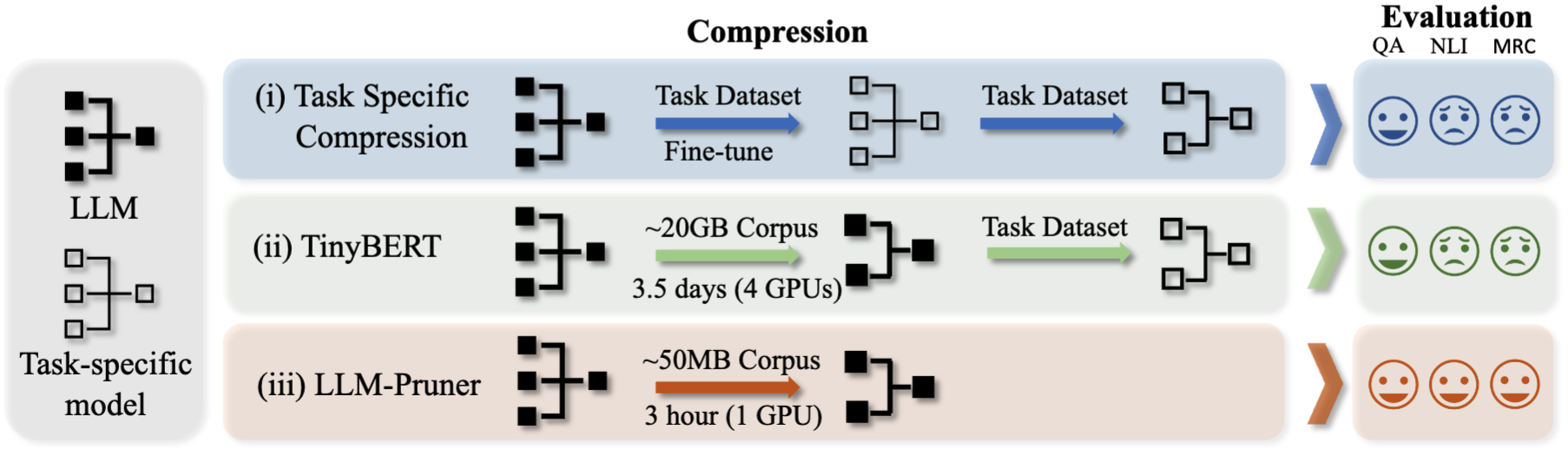
São necessários três passos para podar um LLM:
Após a poda e pós-treinamento, seguimos o LM-Evaluation-Harness para avaliação.
? LLAMA/LLAMA-2 PUNING COM ~ 20% Parâmetros podados:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
Argumentos:
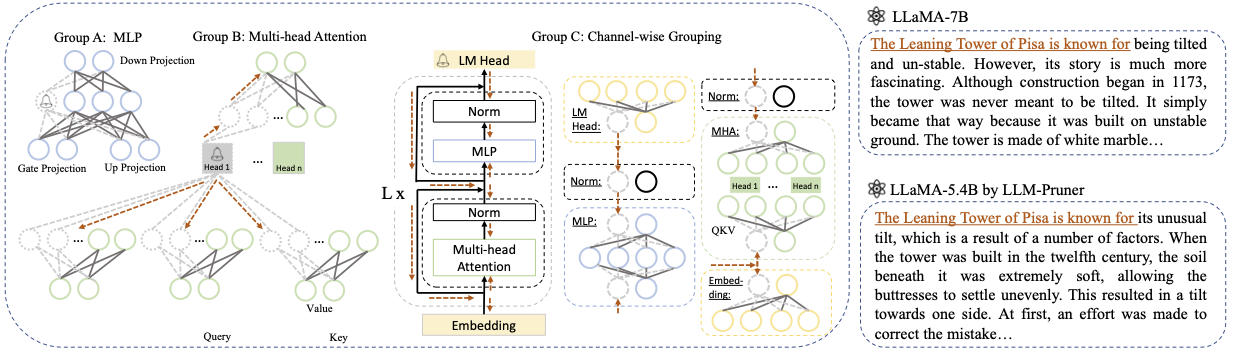
Base model : escolha o modelo básico de llama ou llama-2 e passe o pretrained_model_name_or_path para --base_model . O nome do modelo é usado para AutoModel.from_pretrained para carregar o LLM pré-treinado. Por exemplo, se você deseja usar o LLAMA-2 com 13 bilhões de parâmetros, passe meta-llama/Llama-2-13b-hf para --base_model .Pruning Strategy : Escolha entre poda de bloco, em termos de canal ou em camada, usando as respectivas opções de comando: {--BLOCK_Wise}, {--channel_wise}, {--layer_wise-camada número_of_layers}. Para poda em bloco, especifique as camadas de início e final a serem podadas. A poda de canal não requer argumentos extras. Para poda de camada, use -Número da camada_of_layers para especificar o número desejado de camadas a serem mantidas após a poda.Importance Criterion : Selecione em L1, L2, Random ou Taylor usando o argumento --pruner_type. Para o Taylor Pruner, escolha uma das seguintes opções: vetorize, param_second, param_first, param_mix. Por padrão, o param_mix é usado, que combina o gradiente Hessiano e de primeira ordem aproximado. Se estiver usando L1, L2 ou aleatório, não são necessários argumentos extras.Pruning Ratio : especifica a taxa de poda dos grupos. Difere da taxa de poda dos parâmetros, à medida que os grupos são removidos como as unidades mínimas.Device e Eval_device : A poda e avaliação podem ser realizadas em diferentes dispositivos. Os métodos baseados em Taylor requerem computação para trás durante a poda, o que pode exigir RAM de GPU significativa. Nossa implementação usa a CPU para estimativa de importância (também suporta GPU, basta usar -comvice CUDA). Eval_Device é usado para testar o modelo podado. Se você quiser experimentar Vicuna, especifique o argumento --base_model no caminho para o peso de Vicuna. Siga https://github.com/lm-sys/fastchat para obter pesos de Vicuna.
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
Consulte o exemplo/baichuan para obter mais detalhes
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
Certifique -se de substituir PATH_TO_PRUNE_MODEL pelo caminho para o modelo podado na Etapa 1 e substitua PATH_TO_SAVE_TUNE_MODEL pelo local desejado, onde deseja salvar o modelo sintonizado.
Dica : o treinamento LLAMA-2 em Float16 não é recomendado e é conhecido por produzir NAN; Como tal, o modelo deve ser treinado no BFLOAT16.
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
Para o modelo podado, basta usar o seguinte comando para carregar seu modelo.
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
Devido às diferentes configurações entre os módulos no modelo podado, onde certas camadas podem ter uma largura maior, enquanto outras foram submetidas a mais poda, torna -se impraticável carregar o modelo usando o .from_pretrained() , conforme previsto, abraçando a face. Atualmente, empregamos a torch.save para armazenar o modelo podado.
Como o modelo podado possui configuração diferente em cada camada, como algumas camadas podem ser mais largas, mas algumas camadas foram mais podadas, o modelo não pode ser carregado com o .from_pretrained() na face abraçada. Atualmente, simplesmente usamos torch.load torch.save .
Fornecemos um script simples para geração de textos usando modelos pré-treinados / podados / podadas com pós-treinamento.
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
As instruções acima implantarão seus LLMs localmente.
Para avaliar o desempenho do modelo podado, seguimos o LM-Avaluation-Harness para avaliar o modelo:
lm-evaluation-harness . O ponto de verificação sintonizado da etapa pós-treinamento seria salvo no seguinte formato: - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
Organize os arquivos pelos seguintes comandos:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
Se você deseja avaliar o checkpoint-200 , defina a época igual a 200 por export epoch=200 .
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
Aqui, substitua PATH_TO_PRUNE_MODEL e PATH_TO_SAVE_TUNE_MODEL pelo caminho que você salva o modelo podado e o modelo sintonizado, e PATH_OR_NAME_TO_BASE_MODEL é para carregar o arquivo de configuração do modelo básico.
[ATUALIZAÇÃO]: Enviamos um script para simplesmente o processo de avaliação se você deseja avaliar o modelo podado com o ponto de verificação ajustado. Basta usar o seguinte comando:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
Substitua as informações necessárias do seu modelo no comando. O último é usado para iterar em diferentes épocas, se você deseja avaliar vários pontos de verificação em um comando. Por exemplo:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
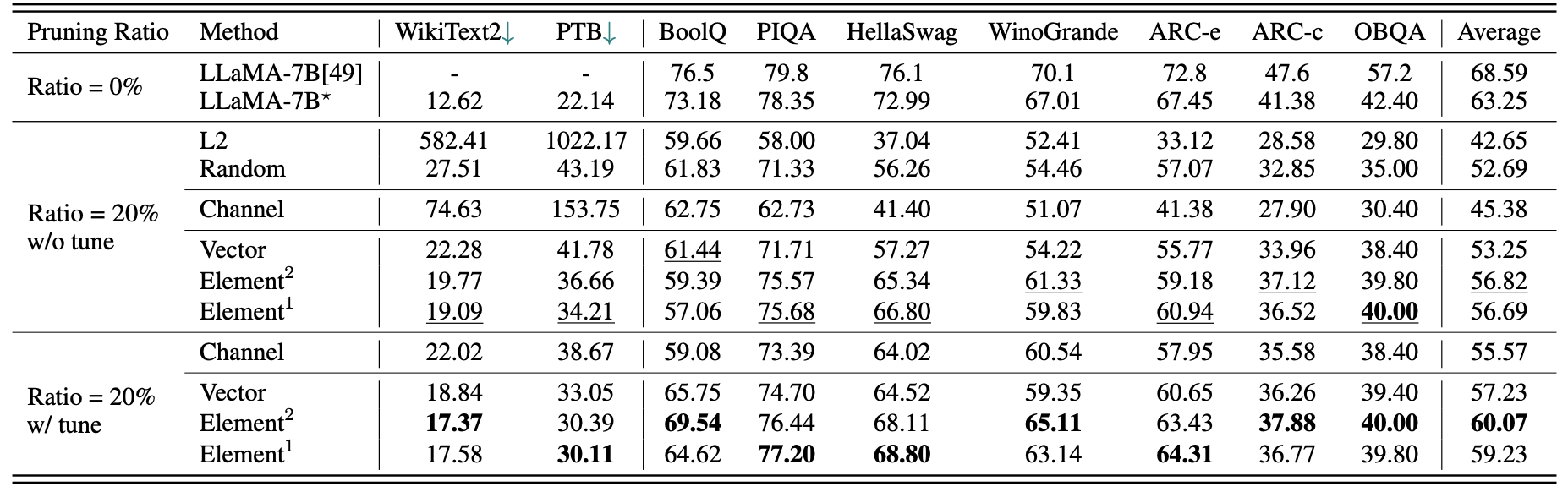
Um breve resultado quantitativo para a llama-7b:
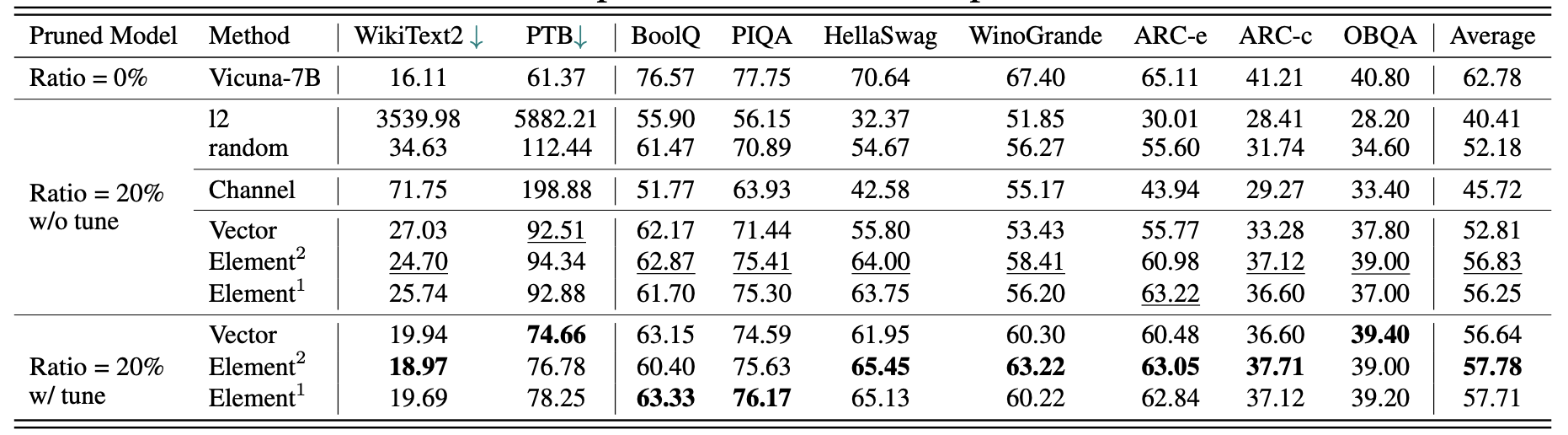
Os resultados para Vicuna-7b:
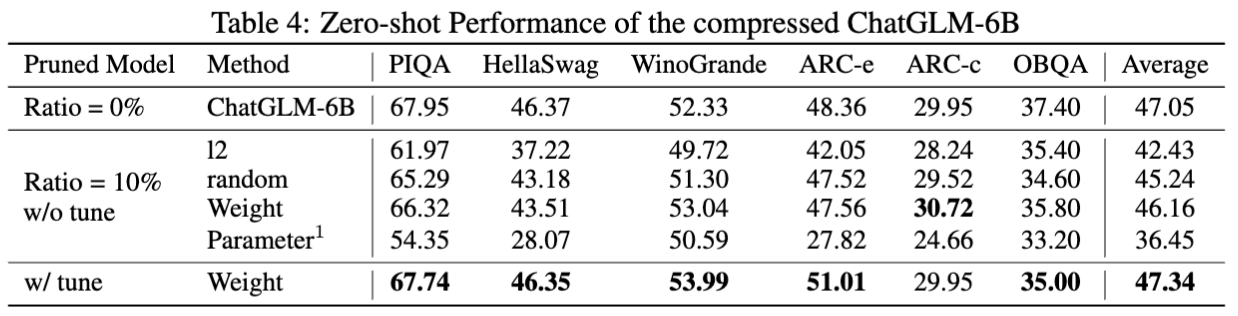
Os resultados do ChatGlm-6b:
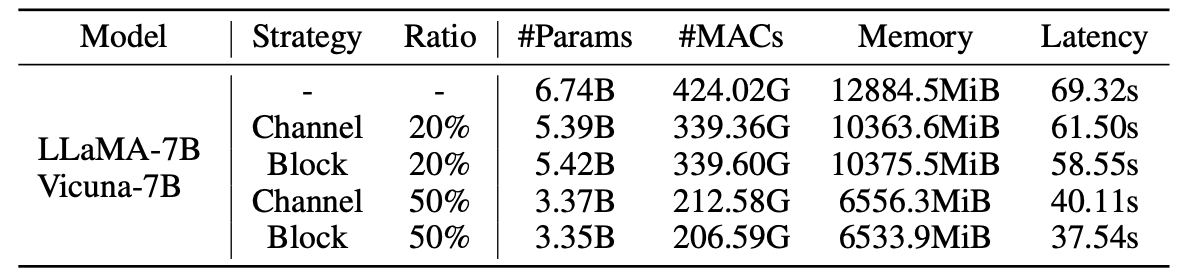
Estatísticas para modelos podados:
Resultados do LLM-PRUNER com 2,59M Amostras:
| Taxa de poda | #Param | Memória | Latência | Aceleração | Boolq | Piqa | Hellaswag | Winogrande | Arc-e | Arc-c | Obqa | Média |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama-7b | 6.74b | 12884.5mib | 69.32s | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| Llama-5.4b com alpaca (50k) | 5.47b | 10488.4mib | 58,55s | 1.18x | 64.62 | 77.20 | 68,80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| Llama-5.4b com lamini (2,59m) | 5.47b | 10488.4mib | 58,55s | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40,70 | 38.80 | 62.36 |
Mais resultados podem ser encontrados no artigo.
| Modelo original | Saída | Modelo podado | Saída |
|---|---|---|---|
| Llama-7b | O universo é a totalidade do espaço, tempo, matéria e energia que existe. Inclui toda matéria e energia, visíveis ou não, e de fato todo o universo é invisível. Existem muitas teorias sobre sua origem e destino final ... | LLAMA-5.4B | O universo é a totalidade do espaço, tempo, matéria e energia que existe. As leis que compõem a física - elétrons orbitando átomos, ímãs atraindo outros objetos, planetas que orbitam o sol - foram consistentes sobre ... |
| Vicuna-7b | 10 etapas para construir um aplicativo iOS: 1. Pesquise e desenvolva a ideia. 2. Decida a plataforma que você deseja usar (iOS, Android ou ambos). 3. Crie um plano e um orçamento. 4. Contrate uma equipe de desenvolvedores. 5. Projete a interface do usuário (UI). 6. Desenvolva a interface do usuário (UI). 7. Teste e iterar no aplicativo. 8. Envie o aplicativo para a App Store. 9. Otimize o aplicativo para desempenho e experiência do usuário (UX). 10. Mercado e promova o aplicativo. | Vicuna-5.4b | 10 etapas para criar um aplicativo iOS: 1. Planeje seu aplicativo: decida o que deve fazer, como será e quanto custará construí -lo. 2. Contrate um desenvolvedor: um bom desenvolvedor iOS o ajudará a projetar a interface do usuário, criar o aplicativo e garantir que ele seja livre de bugs. 3. Crie uma interface do usuário: é aqui que a mágica acontece. A interface do usuário do seu aplicativo será projetada e ridicularizada neste momento ... |
| Chatglm-6b | Escreva uma poesia sobre amor e paz. No meio da agitação da vida, acho seu amor uma paz suave. É um sentimento que não pode ser transmitido, uma conexão que não pode ser distanciada. Com seu sorriso, seus olhos, seu abraço, sinto uma sensação de pertencer que somente você pode dar. É um amor que dura para sempre, um amor que não pode ser derrotado ... | Chatglm-5.6b | Escreva uma poesia sobre amor e paz. Amor e paz, duas coisas maravilhosas - um desejo puro e sem fim em meu coração e os dois, devo procurar por um longo, muito tempo, eu sei. |
Devido a mudanças nas versões dos modelos e repositórios usados neste projeto, listamos alguns problemas de versão conhecidos e as versões específicas necessárias para reproduzir nosso método:
Se você achar este projeto útil, cite
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


