LLM Pruner
1.0.0
LLM-Pruner : 대형 언어 모델의 구조적 가지 치기 [ARXIV]
Xinyin MA, Gongfan Fang, Xinchao Wang
싱가포르 국립 대학교
.from_pretrained() 지원합니다. 채팅을 위해 WeChat 그룹에 가입하십시오.
pip install -r requirement.txt
bash script/llama_prune.sh
이 스크립트는 LLAMA-7B 모델을 ~ 20% 매개 변수로 잘라냅니다. 미리 훈련 된 모든 모델과 데이터 세트는 자동으로 다운로드되므로 리소스를 수동으로 다운로드 할 필요가 없습니다. 이 스크립트를 처음으로 실행할 때는 모델과 데이터 세트를 다운로드하는 데 약간의 시간이 필요합니다.
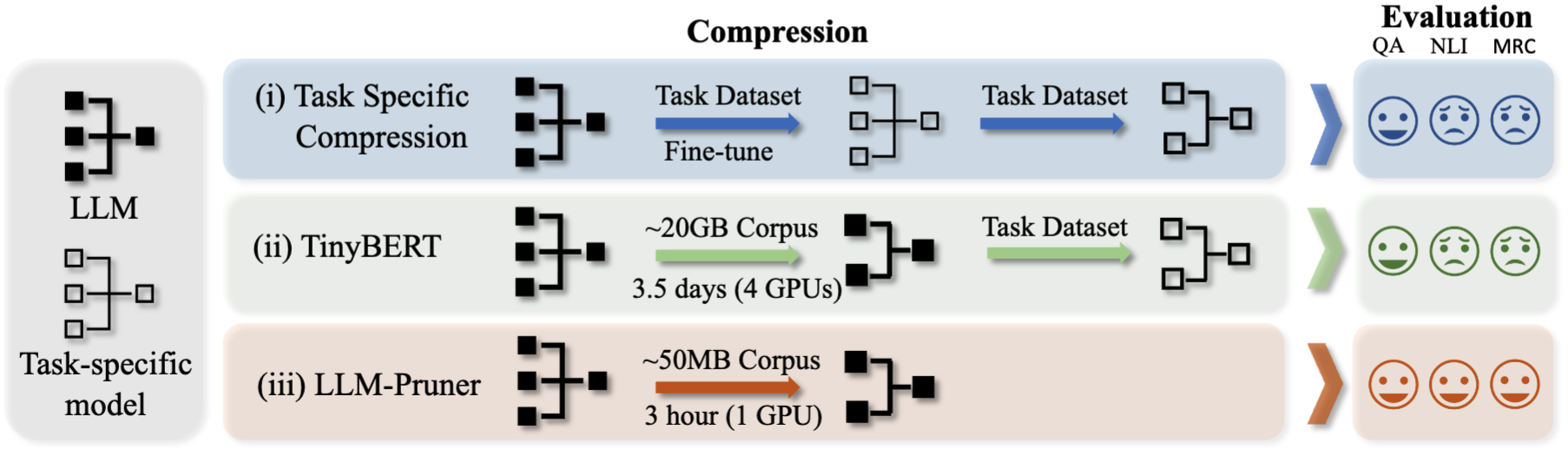
LLM을 정리하는 데 세 가지 단계가 필요합니다.
가지 치기 및 훈련 후, 우리는 평가를 위해 LM-evaluation-harness를 따릅니다.
? Llama/llama-2 ~ 20% 매개 변수를 갖춘 가지 치기 정리 :
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
논쟁 :
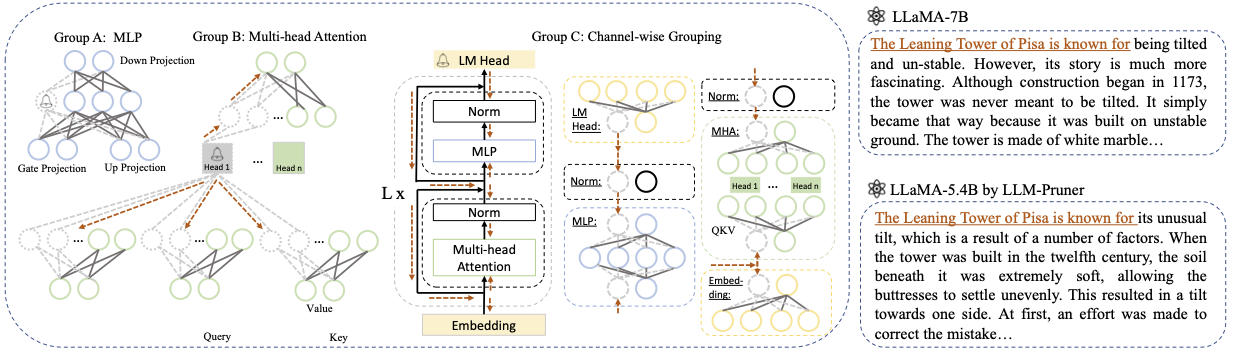
Base model : llama 또는 llama-2에서 기본 모델을 선택하고 pretrained_model_name_or_path 를 --base_model 로 전달하십시오. 모델 이름은 AutoModel.from_pretrained 에 사용됩니다. 예를 들어, 130 억 파라미터와 함께 LLAMA-2를 사용하려면 meta-llama/Llama-2-13b-hf --base_model 로 통과하십시오.Pruning Strategy : 각 명령 옵션을 사용하여 블록, 채널별 또는 계층 별 가지 치기 중에서 선택하십시오. 블록 현상 가지 치기의 경우 가지 치기 할 시작 및 엔드 레이어를 지정하십시오. 채널별 가지 치기에는 추가 논쟁이 필요하지 않습니다. 레이어 가지 치기의 경우, -레이어 번호_of_layers를 사용하여 가지 치기 후에 보관할 원하는 층 수를 지정하십시오.Importance Criterion : -pruner_type 인수를 사용하여 L1, L2, Random 또는 Taylor 중에서 선택하십시오. Taylor Pruner의 경우 다음 옵션 중 하나를 선택하십시오. Vectorize, Param_second, Param_first, Param_mix. 기본적으로 Param_mix가 사용되며 근사한 2 차 Hessian 및 1 차 그라디언트를 결합합니다. L1, L2 또는 Random을 사용하는 경우 추가 인수가 필요하지 않습니다.Pruning Ratio : 그룹의 가지 치기 비율을 지정합니다. 그룹이 최소 단위로 제거되므로 가지 치기 속도와 다릅니다.Device 및 Eval_device : 가지 치기 및 평가는 다른 장치에서 수행 할 수 있습니다. Taylor 기반 방법은 가지 치기 중에 후진 계산이 필요하며, 이는 상당한 GPU RAM이 필요할 수 있습니다. 우리의 구현은 중요성 추정을 위해 CPU를 사용합니다 (또한 GPU를 지원하고 단순히 사용 -부전 CUDA). Eval_Device는 가지 치기 모델을 테스트하는 데 사용됩니다. Vicuna를 시도하려면 Vicuna Weight 로의 경로에 인수 --base_model 지정하십시오. vicuna weights를 얻으려면 https://github.com/lm-sys/fastchat를 따르십시오.
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
자세한 내용은 예제/Baichuan을 참조하십시오
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
1 단계에서 PATH_TO_PRUNE_MODEL 가지 치기 모델로의 경로로 바꾸고 튜닝 PATH_TO_SAVE_TUNE_MODEL 모델을 저장하려는 원하는 위치로 교체하십시오.
팁 : Float16의 LLAMA-2 훈련은 권장되지 않으며 NAN을 생산하는 것으로 알려져 있습니다. 따라서 모델은 Bfloat16에서 훈련되어야합니다.
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
가지 치기 모델의 경우 다음 명령을 사용하여 모델을로드하십시오.
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
가지 치기 모델의 모듈 간의 구성이 다르기 때문에 특정 레이어가 더 큰 폭을 가질 수 있고 다른 레이어가 더 많이 가지지 않을 수 있지만, 포옹으로 제공되는 .from_pretrained() 사용하여 모델을로드하는 것은 실용적이지 않습니다. 현재 우리는 가지 치기 모델을 저장하기 위해 torch.save 를 사용합니다.
가지 치기 모델은 각 레이어마다 다른 구성을 가지므로 일부 레이어가 더 넓지 만 일부 레이어가 더 잘 정리되었을 수 있으므로, 포옹에서 .from_pretrained() 로 모델을로드 할 수 없습니다. 현재 우리는 단순히 torch.save 를 사용하여 가지 치기 모델과 torch.load 저장하여 가지 치기 모델을로드합니다.
우리는 사후 훈련 / 잘린 모델 / 가지 치기 모델을 사후 훈련과 함께 사용하여 간단한 스크립트를 제공합니다.
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
위의 지침은 LLMS를 로컬로 배포합니다.
가지 치기 모델의 성능을 평가하기 위해 LM-Evaluation-Harness를 따라 모델을 평가합니다.
lm-evaluation-harness 대한 입력 요구 사항을 충족시키기위한 파일을 정리하는 것입니다. 교육 후 단계에서 조정 된 체크 포인트는 다음 형식으로 저장됩니다. - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
다음 명령으로 파일을 정렬합니다.
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
checkpoint-200 평가하려면 export epoch=200 으로 설정하십시오.
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
여기서, PATH_TO_PRUNE_MODEL 및 PATH_TO_SAVE_TUNE_MODEL 가지 치기 모델과 튜닝 된 모델을 저장하는 경로로 바꾸고 PATH_OR_NAME_TO_BASE_MODEL 은 기본 모델의 구성 파일을로드하기위한 것입니다.
[업데이트] : 조정 된 체크 포인트로 잘리지 않은 모델을 평가하려면 스크립트를 평가 프로세스에 단순히 업로드합니다. 다음 명령을 사용하기 만하면됩니다.
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
명령에서 모델의 필요한 정보를 교체하십시오. 마지막은 하나의 명령으로 여러 검문소를 평가하려면 다른 시대를 반복하는 데 사용됩니다. 예를 들어:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
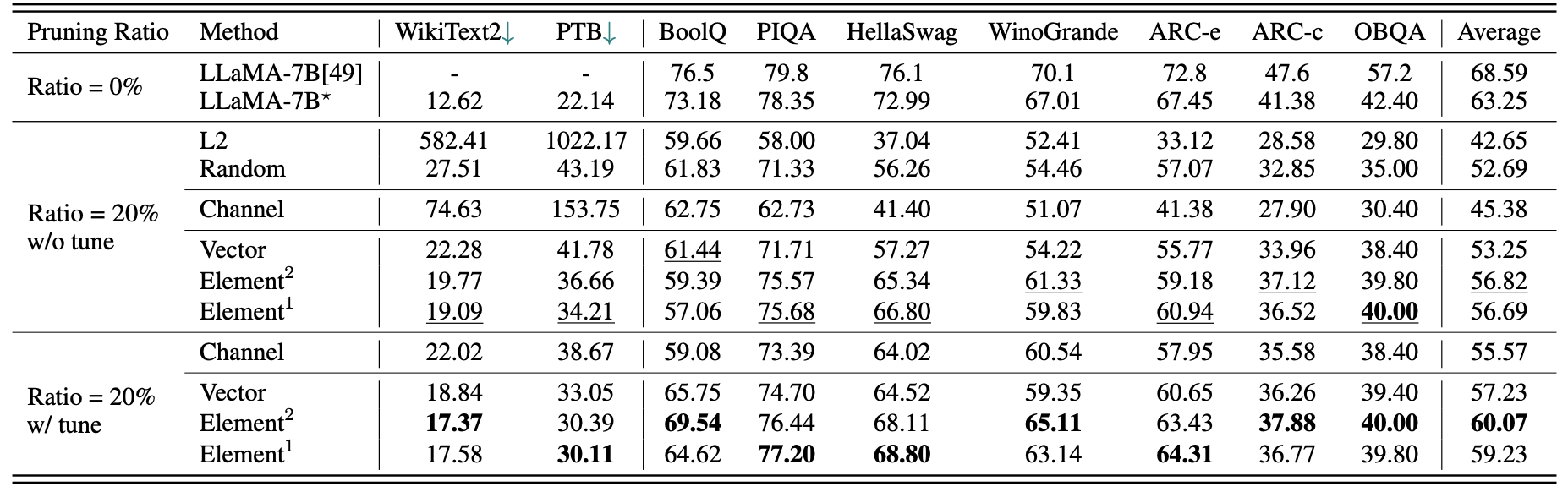
llama-7b에 대한 간단한 정량적 결과 :
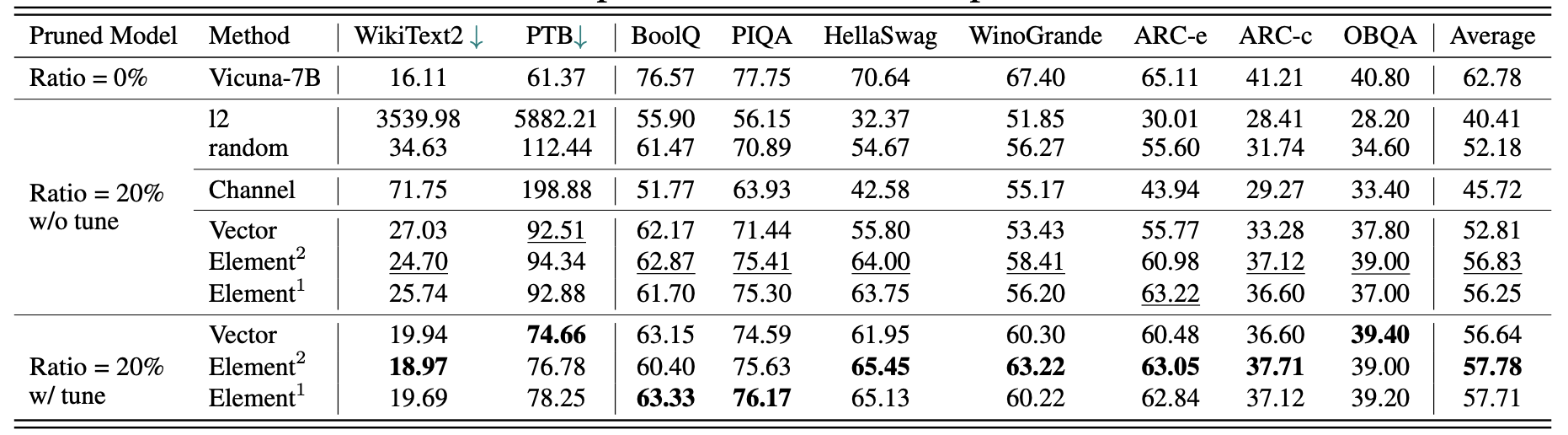
Vicuna-7b의 결과 :
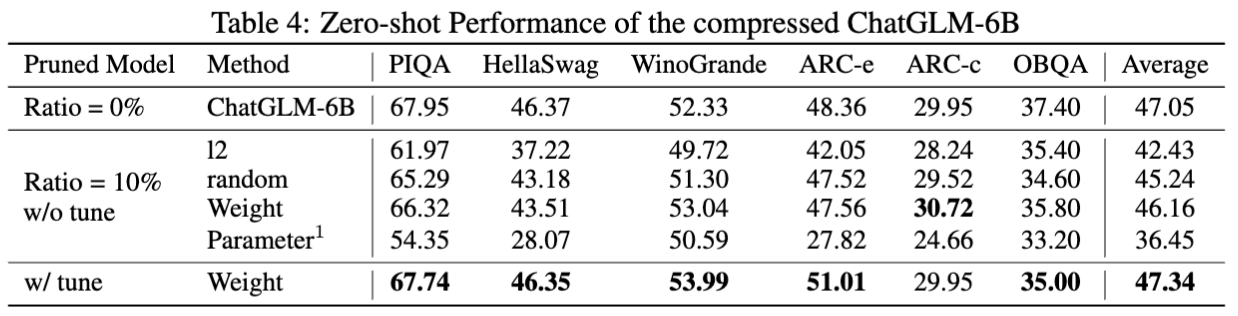
chatglm-6b의 결과 :
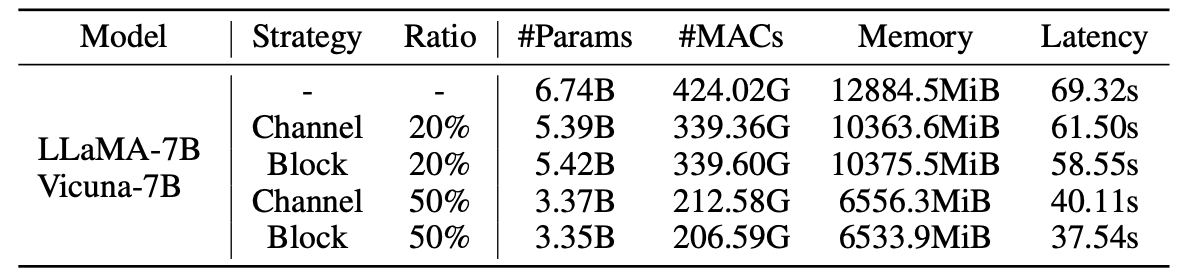
치기 모델에 대한 통계 :
2.59m 샘플을 가진 LLM-Pruner의 결과 :
| 가지 치기 비율 | #Param | 메모리 | 숨어 있음 | 속도를 높이십시오 | 부울 | piqa | Hellaswag | Winogrande | 아크 -E | 아크 -C | OBQA | 평균 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| llama-7b | 6.74b | 12884.5mib | 69.32S | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| 알파카 (50K)와 LLAMA-5.4B | 5.47b | 10488.4mib | 58.55s | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| lamini (2.59m)와 LLAMA-5.4B | 5.47b | 10488.4mib | 58.55s | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40.70 | 38.80 | 62.36 |
더 많은 결과가 논문에서 찾을 수 있습니다.
| 원본 모델 | 산출 | 가지 치기 모델 | 산출 |
|---|---|---|---|
| llama-7b | 우주는 존재하는 공간, 시간, 물질 및 에너지의 전체입니다. 그것은 눈에 보이 든 아니든 모든 물질과 에너지를 포함하며, 실제로 전체 우주는 보이지 않습니다. 기원과 궁극적 인 운명에 관한 많은 이론이 있습니다 ... | llama-5.4b | 우주는 존재하는 공간, 시간, 물질 및 에너지의 전체입니다. 물리학을 구성하는 법률 - 전자 공전 원자, 자석, 다른 물체를 끌어들이는 자석, 태양을 공전하는 행성 - 일관되었다 ... |
| 비쿠나 -7b | iOS 앱을 구축하는 10 단계 : 1. 아이디어를 연구하고 개발하십시오. 2. 사용하려는 플랫폼 (iOS, Android 또는 둘 다)을 결정하십시오. 3. 계획과 예산을 만듭니다. 4. 개발자 팀을 고용하십시오. 5. 사용자 인터페이스 (UI)를 설계하십시오. 6. 사용자 인터페이스 (UI)를 개발하십시오. 7. 앱에서 테스트하고 반복합니다. 8. 앱을 앱 스토어에 제출하십시오. 9. 성능 및 사용자 경험 (UX)을 위해 앱을 최적화하십시오. 10. 앱을 시장에 홍보하고 홍보하십시오. | 비쿠나 -5.4b | iOS 앱을 구축하기위한 10 단계 : 1. 앱 계획 :해야 할 일, 어떻게 보일지, 그리고 구축하는 데 드는 비용을 결정하십시오. 2. 개발자 고용 : 좋은 iOS 개발자는 사용자 인터페이스를 설계하고 앱을 만들고 버그가 없는지 확인하는 데 도움이됩니다. 3. 사용자 인터페이스 만들기 : 마법이 일어나는 곳입니다. 이 시점에서 앱의 사용자 인터페이스가 설계되고 조롱됩니다 ... |
| chatglm-6b | 사랑과 평화에 관한시를 쓰십시오. 인생의 번잡함이 가득한 중간에, 나는 당신의 사랑이 진정 평화라고 생각합니다. 전달할 수없는 느낌, 거리가 멀지 않은 연결입니다. 당신의 미소, 눈, 당신의 포옹으로, 나는 당신만이 줄 수있는 소속감을 느낍니다. 영원히 지속되는 사랑, 패배 할 수없는 사랑 ... | chatglm-5.6b | 사랑과 평화에 관한시를 쓰십시오. 사랑과 평화, 두 가지 놀라운 것들 내 마음에 순수하고 끝없는 욕망 그리고 둘 다 오랫동안 오랫동안, 나는 알고 있습니다. |
이 프로젝트에 사용 된 모델 및 저장소 버전의 변경으로 인해 알려진 몇 가지 버전 문제와 방법을 재현하는 데 필요한 특정 버전을 나열했습니다.
이 프로젝트가 유용하다고 생각되면 인용하십시오
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


