LLM Pruner
1.0.0
LLM-PRUNER: Pada pemangkasan struktural model bahasa besar [Arxiv]
Xinyin MA, Gongfan Fang, Xinchao Wang
Universitas Nasional Singapura
.from_pretrained() untuk memuat model. Bergabunglah dengan grup WeChat kami untuk mengobrol:
pip install -r requirement.txt
bash script/llama_prune.sh
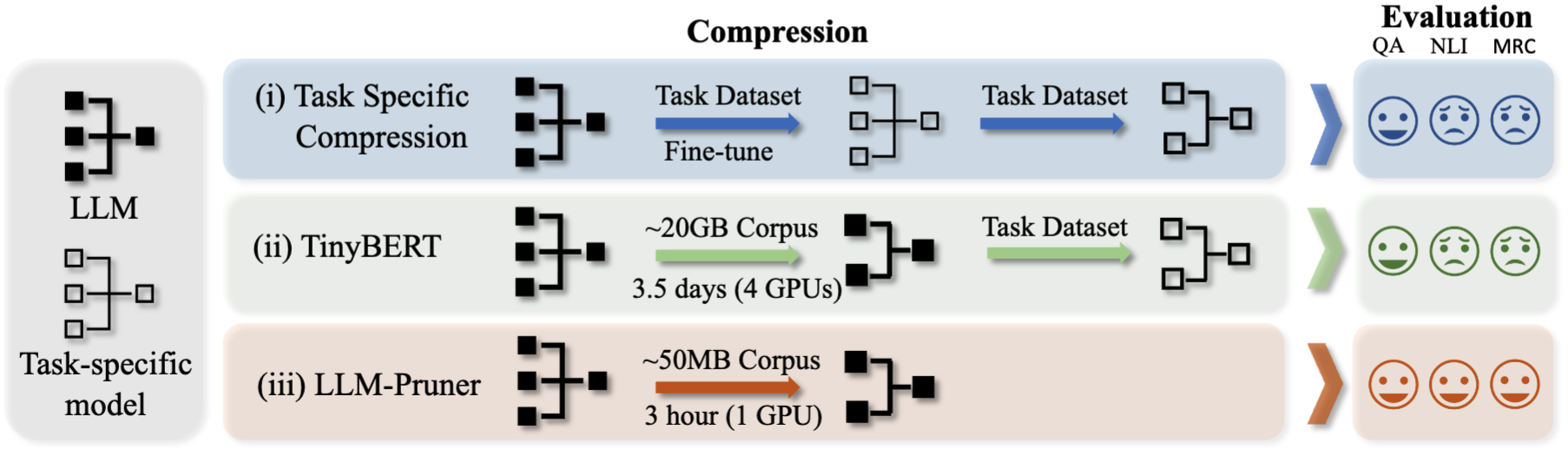
Skrip ini akan memampatkan model LLAMA-7B dengan ~ 20% parameter yang dipangkas. Semua model pra-terlatih dan dataset akan diunduh secara otomatis, sehingga Anda tidak perlu mengunduh sumber daya secara manual. Saat menjalankan skrip ini untuk pertama kalinya, itu akan membutuhkan waktu untuk mengunduh model dan dataset.
Dibutuhkan tiga langkah untuk memangkas llm:
Setelah pemangkasan dan pasca-pelatihan, kami mengikuti LM-Evaluasi-Harness untuk evaluasi.
? Llama/llama-2 pemangkasan dengan ~ 20% parameter dipangkas:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
Argumen:
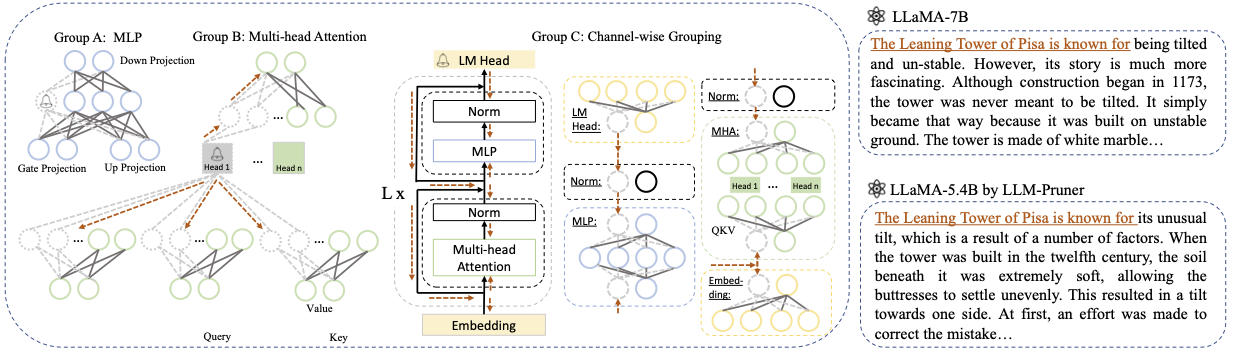
Base model : Pilih model dasar dari llama atau llama-2 dan lewati pretrained_model_name_or_path ke --base_model . Nama model digunakan untuk AutoModel.from_pretrained untuk memuat LLM yang sudah terlatih. Misalnya, jika Anda ingin menggunakan LLAMA-2 dengan 13 miliar parameter, maka lulus meta-llama/Llama-2-13b-hf ke --base_model .Pruning Strategy : Pilih antara blok-bijaksana, saluran-bijaksana, atau pemangkasan lapisan-bijaksana menggunakan opsi perintah masing-masing: {--block_wise}, {--channel_wise}, {--layer_wise--layer number_of_layers}. Untuk pemangkasan blok-bijaksana, tentukan lapisan awal dan akhir yang akan dipangkas. Pemangkasan saluran-bijaksana tidak memerlukan argumen tambahan. Untuk pemangkasan layer, gunakan - -layer number_of_layers untuk menentukan jumlah lapisan yang diinginkan untuk disimpan setelah pemangkasan.Importance Criterion : Pilih dari L1, L2, Random, atau Taylor menggunakan argumen --pruner_type. Untuk Taylor Pruner, pilih salah satu opsi berikut: Vectorize, Param_Second, Param_First, Param_Mix. Secara default, Param_Mix digunakan, yang menggabungkan gradien Hessian dan orde pertama yang diperkirakan. Jika menggunakan L1, L2, atau acak, tidak diperlukan argumen tambahan.Pruning Ratio : Menentukan rasio pemangkasan kelompok. Ini berbeda dari laju pemangkasan parameter, karena kelompok dihapus sebagai unit minimal.Device dan Eval_device : Pemangkasan dan evaluasi dapat dilakukan pada perangkat yang berbeda. Metode berbasis Taylor memerlukan perhitungan mundur selama pemangkasan, yang mungkin memerlukan RAM GPU yang signifikan. Implementasi kami menggunakan CPU untuk estimasi penting (juga mendukung GPU, cukup gunakan --Device CUDA). Eval_Device digunakan untuk menguji model yang dipangkas. Jika Anda ingin mencoba Vicuna, tentukan argumennya --base_model ke jalan menuju berat vicuna. Silakan ikuti https://github.com/lm-sys/fastchat untuk mendapatkan bobot vicuna.
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
Silakan merujuk ke contoh/Baichuan untuk lebih jelasnya
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
Pastikan untuk mengganti PATH_TO_PRUNE_MODEL dengan path ke model yang dipangkas pada Langkah 1, dan ganti PATH_TO_SAVE_TUNE_MODEL dengan lokasi yang diinginkan di mana Anda ingin menyimpan model yang disetel.
Kiat : Pelatihan Llama-2 di float16 tidak dianjurkan dan diketahui menghasilkan NAN; Dengan demikian, model harus dilatih di bfloat16.
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
Untuk model yang dipangkas, cukup gunakan perintah berikut untuk memuat model Anda.
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
Karena konfigurasi yang berbeda antara modul dalam model yang dipangkas, di mana lapisan tertentu mungkin memiliki lebar yang lebih besar sementara yang lain telah mengalami lebih banyak pemangkasan, menjadi tidak praktis untuk memuat model menggunakan .from_pretrained() sebagaimana disediakan oleh memeluk wajah. Saat ini, kami menggunakan torch.save untuk menyimpan model yang dipangkas.
Karena model yang dipangkas memiliki konfigurasi yang berbeda di setiap lapisan, seperti beberapa lapisan mungkin lebih lebar tetapi beberapa lapisan telah dipangkas lebih banyak, model tidak dapat dimuat dengan .from_pretrained() di wajah pelukan. Saat ini, kami cukup menggunakan torch.save untuk menyimpan model yang dipangkas dan torch.load untuk memuat model yang dipangkas.
Kami memberikan skrip sederhana untuk teks geneate menggunakan model pra-terlatih / dipangkas / model pruned dengan pasca-pelatihan.
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
Instruksi di atas akan menggunakan LLM Anda secara lokal.
Untuk mengevaluasi kinerja model yang dipangkas, kami mengikuti LM-evaluasi-Harness untuk mengevaluasi model:
lm-evaluation-harness . Pos pemeriksaan yang disetel dari langkah pasca-pelatihan akan disimpan dalam format berikut: - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
Atur file dengan perintah berikut:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
Jika Anda ingin mengevaluasi checkpoint-200 , maka atur Epoch Equalts ke 200 dengan export epoch=200 .
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
Di sini, ganti PATH_TO_PRUNE_MODEL dan PATH_TO_SAVE_TUNE_MODEL dengan path yang Anda simpan model yang dipangkas dan model yang disetel, dan PATH_OR_NAME_TO_BASE_MODEL adalah untuk memuat file konfigurasi model dasar.
[UPDATE]: Kami mengunggah skrip hanya untuk proses evaluasi jika Anda ingin mengevaluasi model yang dipangkas dengan pos pemeriksaan yang disetel. Cukup gunakan perintah berikut:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
Ganti informasi yang diperlukan dari model Anda dalam perintah. Yang terakhir digunakan untuk mengulangi zaman yang berbeda jika Anda ingin mengevaluasi beberapa pos pemeriksaan dalam satu perintah. Misalnya:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
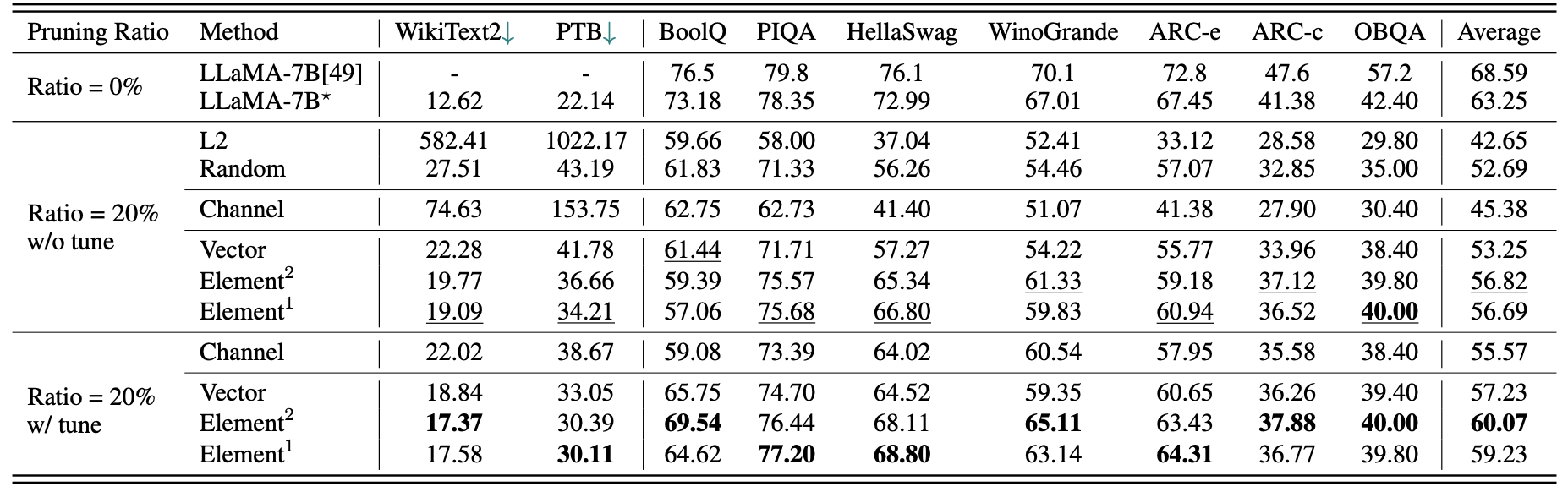
Hasil kuantitatif singkat untuk LLAMA-7B:
Hasil untuk Vicuna-7b:
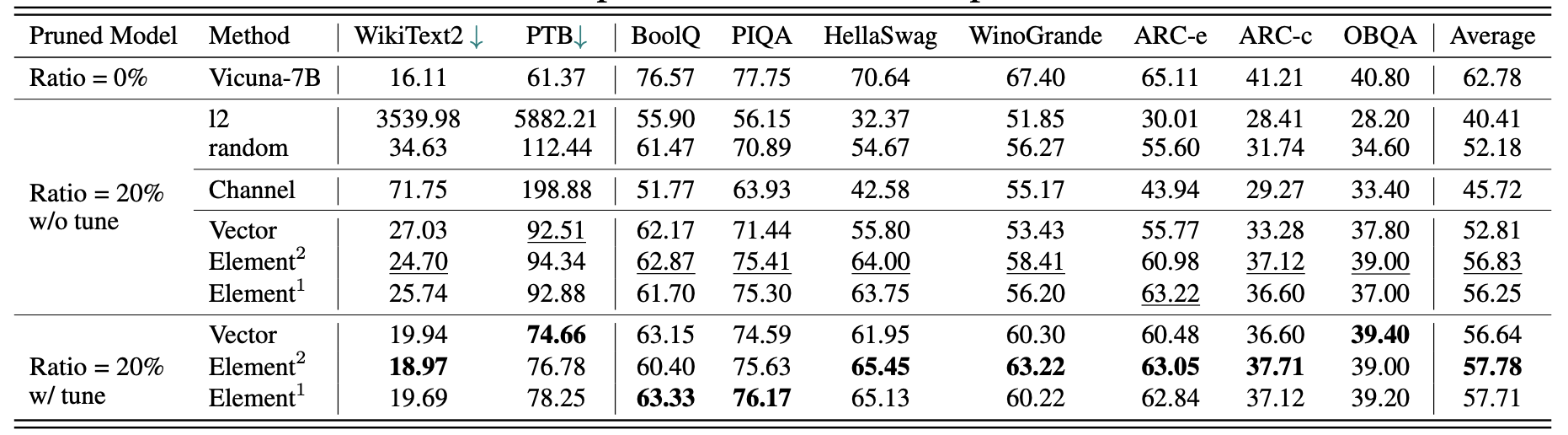
Hasil untuk chatglm-6b:
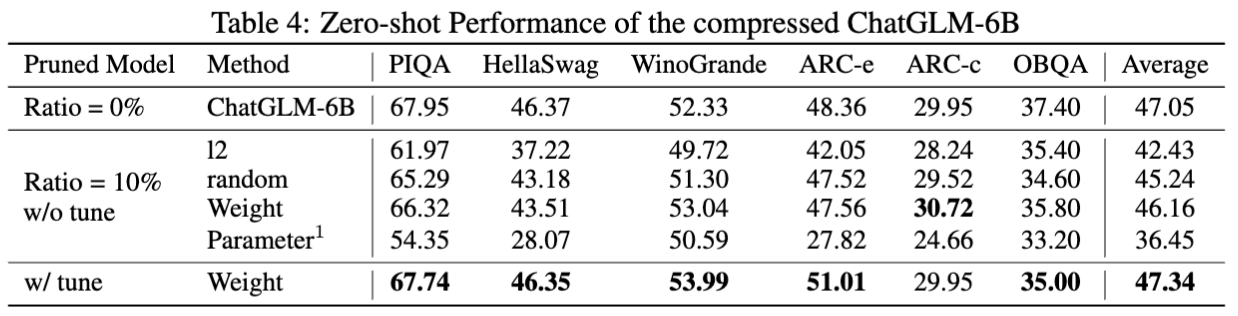
Statistik untuk model yang dipangkas:
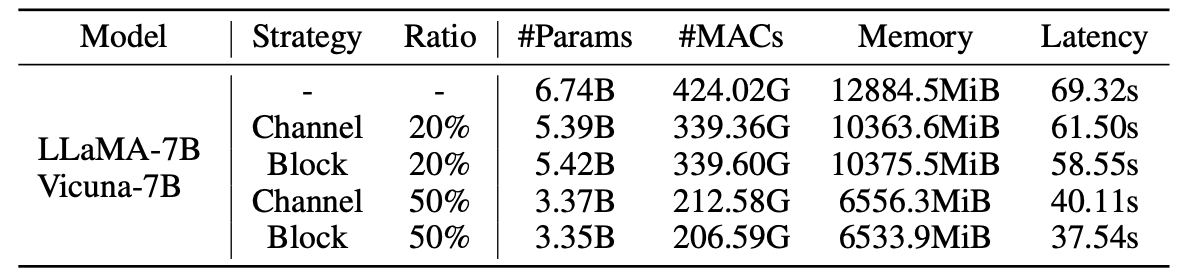
Hasil LLM-Pruner dengan 2,59m sampel:
| Rasio pemangkasan | #Param | Ingatan | Latensi | Percepatan | Boolq | Piqa | Hellaswag | Winogrande | Arc-e | Arc-C | OBQA | Rata-rata |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama-7b | 6.74b | 12884.5mib | 69.32S | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| Llama-5.4b dengan alpaca (50k) | 5.47b | 10488.4MIB | 58.55S | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| Llama-5.4b dengan lamini (2,59m) | 5.47b | 10488.4MIB | 58.55S | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40.70 | 38.80 | 62.36 |
Lebih banyak hasil dapat ditemukan di koran.
| Model asli | Keluaran | Model yang dipangkas | Keluaran |
|---|---|---|---|
| Llama-7b | Alam semesta adalah keseluruhan ruang, waktu, materi, dan energi yang ada. Ini mencakup semua materi dan energi, baik terlihat atau tidak, dan pada kenyataannya seluruh alam semesta tidak terlihat. Ada banyak teori tentang asal dan takdirnya ... | Llama-5.4b | Alam semesta adalah keseluruhan ruang, waktu, materi, dan energi yang ada. Undang -undang yang membentuk fisika - elektron yang mengorbit atom, magnet yang menarik benda lain, planet yang mengorbit matahari - telah konsisten ... |
| Vicuna-7b | 10 Langkah untuk Membangun Aplikasi iOS: 1. Meneliti dan mengembangkan ide. 2. Tentukan platform yang ingin Anda gunakan (iOS, Android, atau keduanya). 3. Buat rencana dan anggaran. 4. Pekerjakan tim pengembang. 5. Desain Antarmuka Pengguna (UI). 6. Kembangkan Antarmuka Pengguna (UI). 7. Uji dan Iterasi pada Aplikasi. 8. Kirimkan aplikasi ke App Store. 9. Optimalkan aplikasi untuk kinerja dan pengalaman pengguna (UX). 10. Pasar dan promosikan aplikasi. | Vicuna-5.4b | 10 Langkah untuk Membangun Aplikasi iOS: 1. Rencanakan aplikasi Anda: Tentukan apa yang harus dilakukan, seperti apa nantinya, dan berapa biaya untuk membangunnya. 2. Pekerjakan pengembang: Pengembang iOS yang baik akan membantu Anda merancang antarmuka pengguna, membuat aplikasi, dan pastikan itu bebas bug. 3. Buat Antarmuka Pengguna: Di sinilah keajaiban terjadi. Antarmuka pengguna aplikasi Anda akan dirancang dan diejek pada saat ini ... |
| Chatglm-6b | Tulis puisi tentang cinta dan kedamaian. Di tengah -tengah keramaian dan kesibukan hidup, saya menemukan cinta Anda kedamaian yang menenangkan. Ini adalah perasaan yang tidak dapat disampaikan, koneksi yang tidak dapat jauh. Dengan senyum Anda, mata Anda, pelukan Anda, saya merasa memiliki rasa memiliki yang hanya bisa Anda berikan. Itu adalah cinta yang bertahan selamanya, cinta yang tidak bisa dikalahkan ... | Chatglm-5.6b | Tulis puisi tentang cinta dan kedamaian. Cinta dan kedamaian, dua hal yang begitu indah keinginan yang murni dan tak ada habisnya di hati saya dan keduanya, saya harus mencari untuk waktu yang sangat lama, saya tahu .. cinta, saya tahu, adalah perasaan menjadi pasangan yang sempurna, dalam segala hal dan kedamaian, saya membutuhkannya, sangat banyak, suatu hari nanti, hati saya akan pergi .. dan damai, saya membutuhkannya .. |
Karena perubahan dalam versi model dan repo yang digunakan dalam proyek ini, kami mencantumkan beberapa masalah versi yang diketahui dan versi spesifik yang diperlukan untuk mereproduksi metode kami:
Jika Anda menemukan proyek ini bermanfaat, silakan mengutip
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


