LLM Pruner
1.0.0
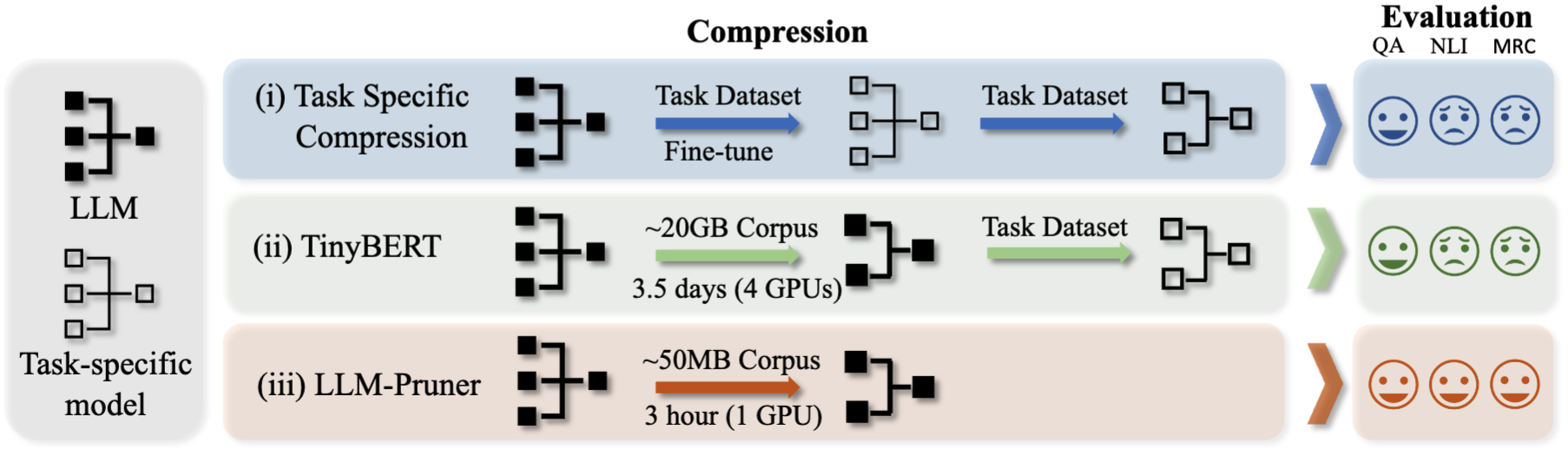
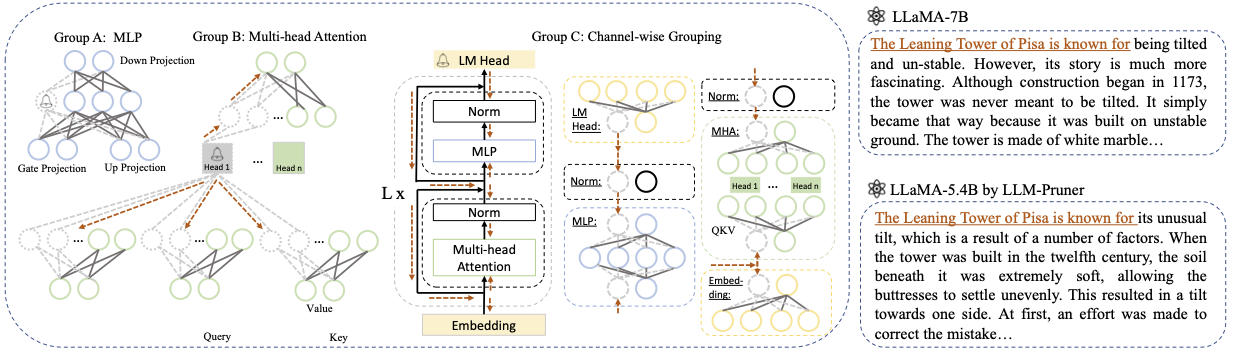
LLM-Pruner: على التقليم الهيكلي لنماذج اللغة الكبيرة [Arxiv]
Xinyin MA ، Gongfan Fang ، Xinchao Wang
الجامعة الوطنية في سنغافورة
.from_pretrained() لتحميل النموذج. انضم إلى مجموعة WeChat للدردشة:
pip install -r requirement.txt
bash script/llama_prune.sh
هذا البرنامج النصي سوف يضغط نموذج LLAMA-7B مع ~ 20 ٪ معلمات تقليم. سيتم تنزيل جميع النماذج المدربة مسبقًا ومجموعة البيانات تلقائيًا ، لذلك لا تحتاج إلى تنزيل المورد يدويًا. عند تشغيل هذا البرنامج النصي لأول مرة ، سيتطلب الأمر بعض الوقت لتنزيل النموذج ومجموعة البيانات.
يستغرق الأمر ثلاث خطوات لتقليم LLM:
بعد التقليم وما بعد التدريب ، نتبع تقييم التقييم LM للتقييم.
؟ LLAMA/LLAMA-2 التقليم مع حوالي 20 ٪ من المعلمات التقليم:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
الحجج:
Base model : اختر النموذج الأساسي من Llama أو Llama-2 وقم بتمرير pretrained_model_name_or_path إلى- --base_model . يستخدم اسم النموذج لـ AutoModel.from_pretrained لتحميل LLM المدربة مسبقًا. على سبيل المثال ، إذا كنت ترغب في استخدام LLAMA-2 مع 13 مليار معلمة ، فقم بتمرير meta-llama/Llama-2-13b-hf إلى- --base_model .Pruning Strategy : اختر بين التقليم بين الكتلة أو القنوات أو الطبقات باستخدام خيارات الأوامر المعنية: {-block_wise} ، {-channel_wise} ، {-layer_wise-layer number_of_layers}. من أجل التقليم الحكيمة ، حدد طبقات البدء والنهاية المراد تشذيبها. لا يتطلب تقليم القنوات الحكيمة حججًا إضافية. بالنسبة إلى التقليم للطبقة ، استخدم -layer number_of_layers لتحديد العدد المطلوب من الطبقات المراد الاحتفاظ بها بعد التقليم.Importance Criterion : حدد من L1 أو L2 أو عشوائي أو تايلور باستخدام وسيطة -pruner_type. بالنسبة إلى Taylor Pruner ، اختر أحد الخيارات التالية: vectorize ، param_second ، param_first ، param_mix. بشكل افتراضي ، يتم استخدام param_mix ، والذي يجمع بين التدرج الهسري من الدرجة الثانية تقريبًا والتدرج من الدرجة الأولى. إذا كنت تستخدم L1 أو L2 أو عشوائيًا ، فلا يلزم وجود وسيطات إضافية.Pruning Ratio : تحدد نسبة التقليم للمجموعات. إنه يختلف عن معدل التقليم للمعلمات ، حيث تتم إزالة المجموعات كوحدات الحد الأدنى.Device و Eval_device : يمكن إجراء التقليم والتقييم على أجهزة مختلفة. تتطلب الطرق المستندة إلى تايلور حسابًا متخلفًا أثناء التقليم ، مما قد يتطلب ذاكرة الوصول العشوائي الكبيرة من GPU. يستخدم تنفيذنا وحدة المعالجة المركزية لتقدير الأهمية (يدعم أيضًا GPU ، ببساطة استخدام -DEGER CUDA). يتم استخدام eval_device لاختبار النموذج المشذب. إذا كنت ترغب في تجربة Vicuna ، فيرجى تحديد الوسيطة --base_model إلى المسار إلى Vicuna Weight. يرجى متابعة https://github.com/lm-sys/fastchat للحصول على أوزان Vicuna.
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
يرجى الرجوع إلى المثال/baichuan لمزيد من التفاصيل
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
تأكد من استبدال PATH_TO_PRUNE_MODEL بالمسار إلى النموذج المشذب في الخطوة 1 ، واستبدال PATH_TO_SAVE_TUNE_MODEL مع الموقع المطلوب حيث تريد حفظ النموذج المضبوط.
نصيحة : لا ينصح بتدريب llama-2 في Float16 ومن المعروف أنه ينتج NAN ؛ على هذا النحو ، يجب تدريب النموذج في Bfloat16.
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
بالنسبة للنموذج المشذب ، ما عليك سوى استخدام الأمر التالي لتحميل النموذج الخاص بك.
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
نظرًا للتكوينات المختلفة بين الوحدات النمطية في النموذج المشذب ، حيث قد يكون لبعض الطبقات عرض أكبر بينما خضع آخرون لمزيد من التقليم ، يصبح من غير العملي تحميل النموذج باستخدام .from_pretrained() كما هو منصوص عليه في وجه المعانقة. حاليًا ، نستخدم torch.save لتخزين النموذج المشذب.
نظرًا لأن النموذج المشذب له تكوين مختلف في كل طبقة ، مثل بعض الطبقات قد تكون أوسع ولكن تم تقليم بعض الطبقات أكثر ، لا يمكن تحميل النموذج باستخدام .from_pretrained() في وجه المعانقة. حاليًا ، نستخدم ببساطة torch.save لحفظ النموذج المشذب و torch.load لتحميل النموذج المشذب.
نحن نقدم نصًا بسيطًا لنصوص Genate باستخدام النماذج التي تم تدريبها / تم تقليمها مسبقًا / نماذج تقليدية مع ما بعد التدريب.
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
ستنشر التعليمات أعلاه LLMS محليًا.
لتقييم أداء النموذج المشذب ، نتبع عملية التقييم LM لتقييم النموذج:
lm-evaluation-harness . ستكون نقطة التفتيش المضبوطة من خطوة ما بعد التدريب في التنسيق التالي: - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
ترتيب الملفات بالأوامر التالية:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
إذا كنت ترغب في تقييم checkpoint-200 ، فقم بتعيين العصر الذي يساوي 200 من قبل export epoch=200 .
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
هنا ، استبدل PATH_TO_PRUNE_MODEL و PATH_TO_SAVE_TUNE_MODEL بالمسار الذي تحفظه في النموذج المشذب والنموذج المضبط ، و PATH_OR_NAME_TO_BASE_MODEL لتحميل ملف التكوين للنموذج الأساسي.
[تحديث]: نقوم بتحميل برنامج نصي ببساطة إلى عملية التقييم إذا كنت ترغب في تقييم النموذج المشذب بنقطة التفتيش المضبوطة. ببساطة استخدم الأمر التالي:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
استبدل المعلومات اللازمة لنموذجك في الأمر. يتم استخدام النهائي للتكرار عبر عصر مختلف إذا كنت ترغب في تقييم عدة نقاط تفتيش في أمر واحد. على سبيل المثال:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
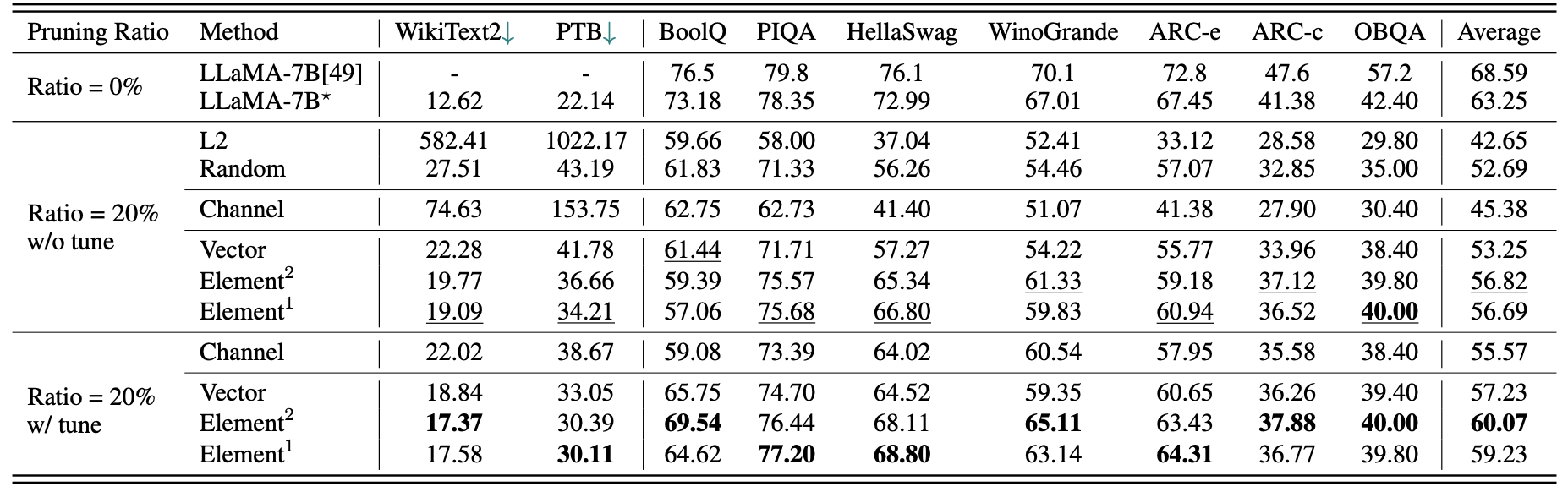
نتائج كمية موجزة ل LAMA-7B:
نتائج Vicuna-7B:
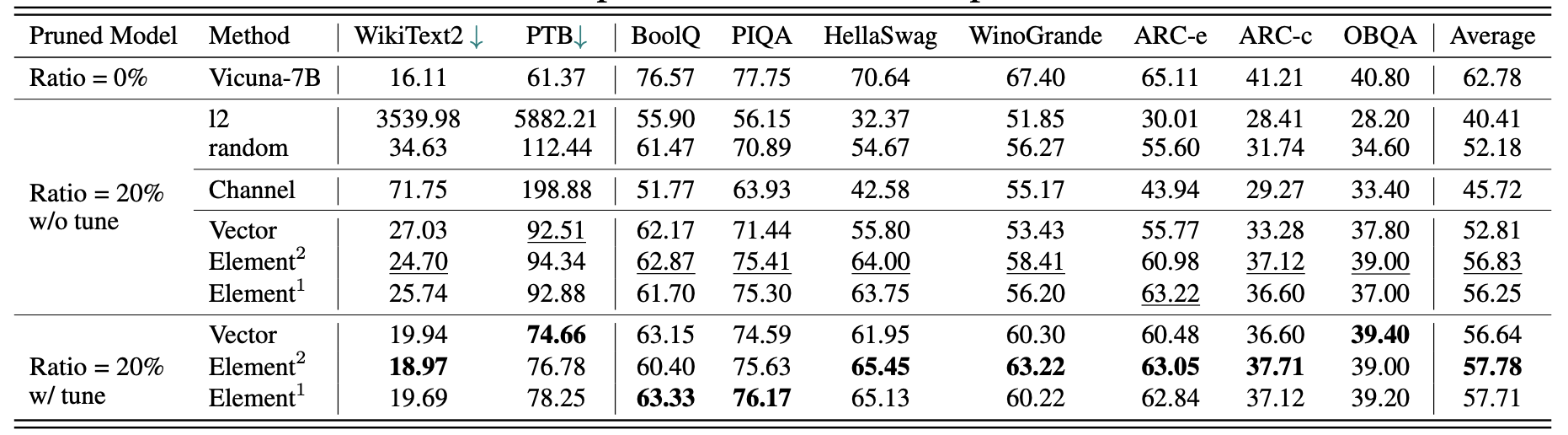
نتائج chatglm-6b:
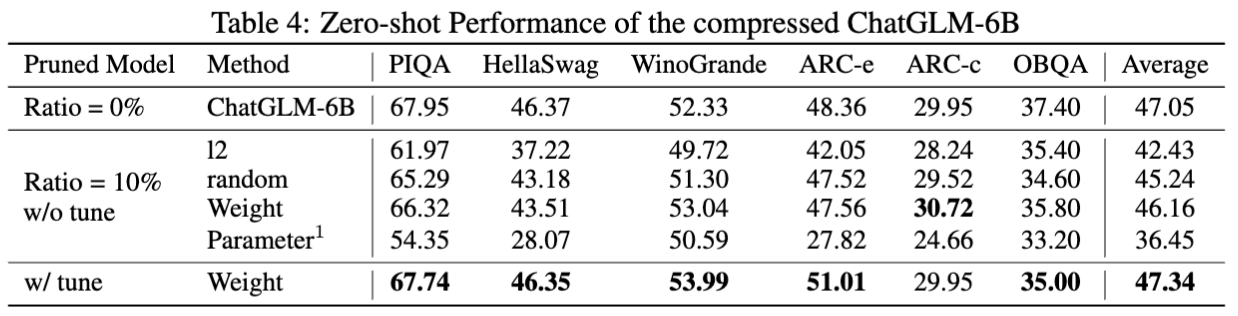
إحصائيات النماذج المشبعة:
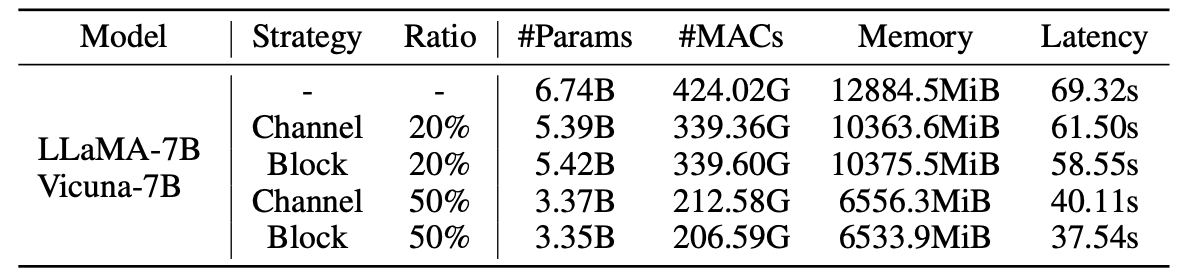
نتائج LLM-pruner مع عينات 2.59m:
| نسبة التقليم | #Param | ذاكرة | كمون | تسريع | Boolq | PIQA | Hellaswag | Winogrande | قوس | arc-c | أوبكا | متوسط |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| لاما -7 ب | 6.74b | 12884.5MIB | 69.32s | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| llama-5.4b مع الألبكة (50 ك) | 5.47b | 10488.4MIB | 58.55S | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| Llama-5.4b مع Lamini (2.59m) | 5.47b | 10488.4MIB | 58.55S | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40.70 | 38.80 | 62.36 |
يمكن العثور على المزيد من النتائج في الورقة.
| النموذج الأصلي | الإخراج | نموذج تشذيب | الإخراج |
|---|---|---|---|
| لاما -7 ب | الكون هو مجمل المساحة والوقت والمادة والطاقة الموجودة. ويشمل كل المادة والطاقة ، سواء كانت مرئية أم لا ، وفي الواقع الكون كله غير مرئي. هناك العديد من النظريات المتعلقة بأصلها ومصيرها النهائي ... | لاما -5.4 ب | الكون هو مجمل المساحة والوقت والمادة والطاقة الموجودة. كانت القوانين التي تشكل الفيزياء - الذرات التي تدور حولها الإلكترونات ، والمغناطيس التي تجذب الأشياء الأخرى ، والكواكب التي تدور حول الشمس - متسقة أكثر من ... |
| Vicuna-7b | 10 خطوات لبناء تطبيق iOS: 1. البحث وتطوير الفكرة. 2. حدد النظام الأساسي الذي تريد استخدامه (iOS ، Android ، أو كليهما). 3. إنشاء خطة وميزانية. 4. استئجار فريق من المطورين. 5. تصميم واجهة المستخدم (UI). 6. تطوير واجهة المستخدم (UI). 7. اختبار وتكرار على التطبيق. 8. إرسال التطبيق إلى متجر التطبيقات. 9. تحسين التطبيق للأداء وتجربة المستخدم (UX). 10. السوق وتعزيز التطبيق. | Vicuna-5.4b | 10 خطوات لإنشاء تطبيق iOS: 1. خطط لتطبيقك: حدد ما الذي يجب أن يفعله ، وما الذي سيبدو عليه ، وما سيكلفه بناءه. 2. استئجار مطور: سيساعدك مطور iOS الجيد في تصميم واجهة المستخدم ، وإنشاء التطبيق ، والتأكد من أنه خالي من الأخطاء. 3. إنشاء واجهة مستخدم: هذا هو المكان الذي يحدث فيه السحر. سيتم تصميم واجهة مستخدم التطبيق الخاصة بك والسخرية في هذه المرحلة ... |
| ChatGlm-6b | اكتب شعرًا عن الحب والسلام. في خضم صخب الحياة وصخب ، أجد حبك سلامًا مهدئًا. إنه شعور لا يمكن نقله ، وهو اتصال لا يمكن أن يكون بعيدًا. بابتسامتك ، عينيك ، احتضانك ، أشعر بشعور من الانتماء الذي يمكنك تقديمه فقط. إنه حب يدوم إلى الأبد ، وهو حب لا يمكن أن يهزم ... | ChatGlm-5.6b | اكتب شعرًا عن الحب والسلام. الحب والسلام ، وهما شيئان رائعان رغبة خالصة لا نهاية لها في قلبي وكلاهما ، يجب أن أسعى إلى منذ فترة طويلة ، وأنا أعلم .. الحب ، وأنا أعلم ، هو شعور بأنني شريك مثالي ، بكل معنى الكلمة ، وسلام ، أحتاجه كثيرًا ، في يوم من الأيام ، في طريق طويل ، سوف يسير قلبي .. |
نظرًا للتغيرات في إصدارات النماذج والإعادة المستخدمة في هذا المشروع ، فقد أدرجنا بعض مشكلات الإصدار المعروفة والإصدارات المحددة اللازمة لإعادة إنتاج طريقتنا:
إذا وجدت هذا المشروع مفيدًا ، يرجى الاستشهاد
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


