LLM Pruner
1.0.0
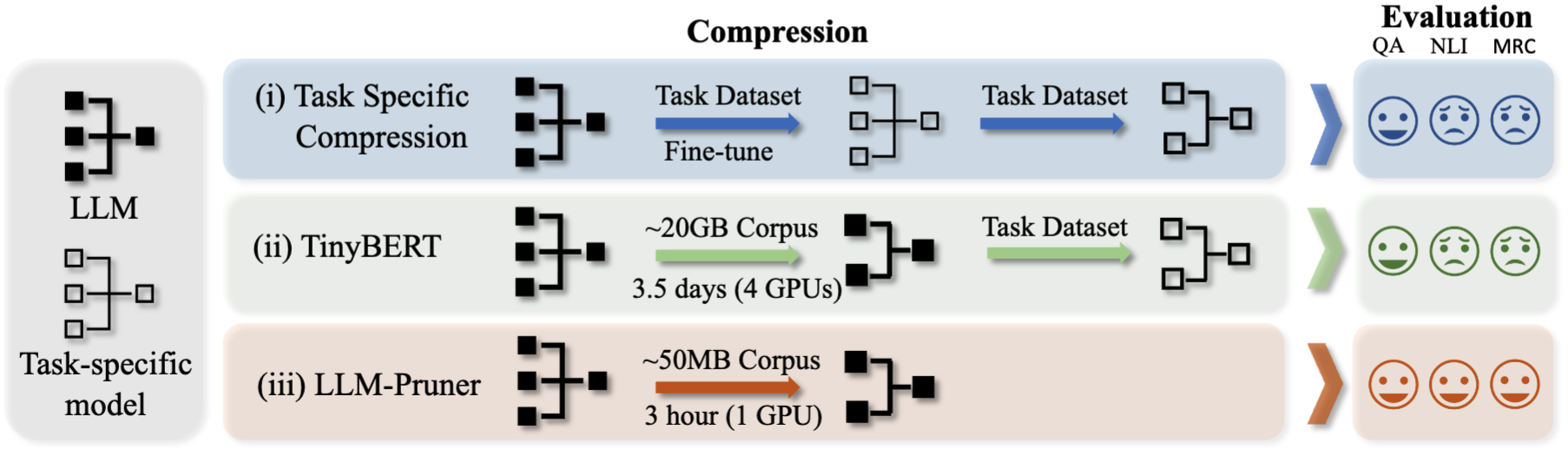
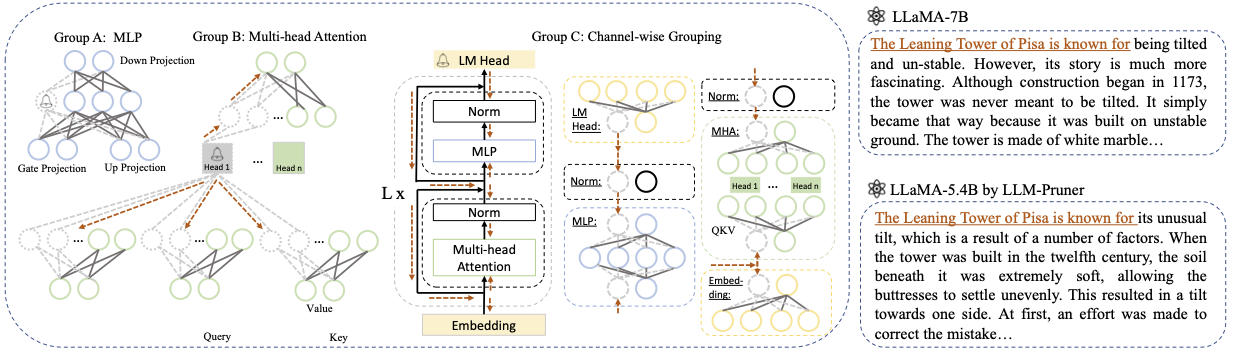
LLM-Pruner: ในการตัดแต่งโครงสร้างของแบบจำลองภาษาขนาดใหญ่ [arxiv]
Xinyin Ma, Gongfan Fang, Xinchao Wang
มหาวิทยาลัยแห่งชาติสิงคโปร์
.from_pretrained() สำหรับการโหลดโมเดล เข้าร่วมกลุ่ม WeChat ของเราเพื่อแชท:
pip install -r requirement.txt
bash script/llama_prune.sh
สคริปต์นี้จะบีบอัดโมเดล LLAMA-7B ด้วยพารามิเตอร์ ~ 20% ตัดแต่ง ทุกรุ่นที่ผ่านการฝึกอบรมมาก่อนและชุดข้อมูลจะถูกดาวน์โหลดโดยอัตโนมัติดังนั้นคุณไม่จำเป็นต้องดาวน์โหลดทรัพยากรด้วยตนเอง เมื่อเรียกใช้สคริปต์นี้เป็นครั้งแรกมันจะต้องใช้เวลาสักครู่ในการดาวน์โหลดโมเดลและชุดข้อมูล
ใช้เวลาสามขั้นตอนในการตัด LLM:
หลังจากการตัดแต่งกิ่งและการฝึกอบรมหลังการฝึกอบรมเราติดตาม LM-Evaluation-Harness เพื่อการประเมินผล
- การตัดแต่งกิ่ง llama/llama-2 ด้วยพารามิเตอร์ ~ 20% ถูกตัดแต่ง:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
ข้อโต้แย้ง:
Base model : เลือกโมเดลพื้นฐานจาก llama หรือ llama-2 และผ่าน pretrained_model_name_or_path ไปที่ --base_model ชื่อรุ่นใช้สำหรับ AutoModel.from_pretrained เพื่อโหลด LLM ที่ผ่านการฝึกอบรมมาก่อน ตัวอย่างเช่นหากคุณต้องการใช้ LLAMA-2 ที่มีพารามิเตอร์ 13 พันล้านพารามิเตอร์ให้ผ่าน meta-llama/Llama-2-13b-hf ไปที่ --base_modelPruning Strategy กิ่ง: เลือกระหว่างการตัดแต่งกิ่งบล็อกที่ฉลาดช่องทางหรือเลเยอร์โดยใช้ตัวเลือกคำสั่งที่เกี่ยวข้อง: {-block_wise}, {-Channel_wise}, {-layer_wise-layer number_of_layers} สำหรับการตัดแต่งกิ่งบล็อกให้ระบุเลเยอร์เริ่มต้นและจุดสิ้นสุดที่จะตัดแต่ง การตัดแต่งกิ่งที่ชาญฉลาดไม่จำเป็นต้องมีข้อโต้แย้งเพิ่มเติม สำหรับเลเยอร์การตัดแต่งกิ่งให้ใช้ -เลเยอร์ number_of_layers เพื่อระบุจำนวนเลเยอร์ที่ต้องการที่จะเก็บไว้หลังจากการตัดแต่งกิ่งImportance Criterion : เลือกจาก L1, L2, Random หรือ Taylor โดยใช้อาร์กิวเมนต์ -PRUNER_TYPE สำหรับ Taylor Pruner ให้เลือกหนึ่งในตัวเลือกต่อไปนี้: Vectorize, Param_Second, Param_first, Param_Mix โดยค่าเริ่มต้น Param_mix จะใช้ซึ่งรวม Hessian ลำดับที่สองและการไล่ระดับสีอันดับแรกโดยประมาณ หากใช้ L1, L2 หรือแบบสุ่มไม่จำเป็นต้องมีข้อโต้แย้งเพิ่มเติมPruning Ratio : ระบุอัตราส่วนการตัดแต่งกิ่งของกลุ่ม มันแตกต่างจากอัตราการตัดแต่งพารามิเตอร์เนื่องจากกลุ่มจะถูกลบออกเป็นหน่วยที่น้อยที่สุดDevice และ Eval_device : การตัดแต่งกิ่งและการประเมินผลสามารถทำได้บนอุปกรณ์ต่าง ๆ วิธีการที่ใช้เทย์เลอร์ต้องการการคำนวณย้อนหลังในระหว่างการตัดแต่งซึ่งอาจต้องใช้ RAM GPU ที่สำคัญ การใช้งานของเราใช้ CPU สำหรับการประมาณความสำคัญ (ยังรองรับ GPU เพียงแค่ใช้ -อุปกรณ์ CUDA) eval_device ใช้เพื่อทดสอบโมเดลตัดแต่ง หากคุณต้องการลอง Vicuna โปรดระบุอาร์กิวเมนต์ --base_model ไปยังเส้นทางสู่น้ำหนัก Vicuna โปรดติดตาม https://github.com/lm-sys/fastchat เพื่อรับน้ำหนัก Vicuna
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
โปรดดูตัวอย่าง/Baichuan สำหรับรายละเอียดเพิ่มเติม
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
ตรวจสอบให้แน่ใจว่าได้แทนที่ PATH_TO_PRUNE_MODEL ด้วยเส้นทางไปยังรุ่นตัดแต่งในขั้นตอนที่ 1 และแทนที่ PATH_TO_SAVE_TUNE_MODEL ด้วยตำแหน่งที่ต้องการซึ่งคุณต้องการบันทึกโมเดลที่ปรับแต่ง
เคล็ดลับ : ไม่แนะนำให้ฝึกอบรม LLAMA-2 ใน Float16 และเป็นที่รู้จักกันในการผลิต NAN; ดังนั้นรูปแบบควรได้รับการฝึกฝนใน Bfloat16
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
สำหรับรุ่นตัดแต่งเพียงใช้คำสั่งต่อไปนี้เพื่อโหลดโมเดลของคุณ
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
เนื่องจากการกำหนดค่าที่แตกต่างกันระหว่างโมดูลในโมเดลตัดแต่งซึ่งเลเยอร์บางชั้นอาจมีความกว้างมากขึ้นในขณะที่คนอื่น ๆ ได้รับการตัดแต่งมากขึ้นจึงไม่สามารถโหลดแบบจำลองได้โดยใช้. .from_pretrained() ตามที่ได้รับจากการกอดใบหน้า ปัจจุบันเราใช้ torch.save เพื่อเก็บโมเดลตัดแต่ง
เนื่องจากโมเดลตัดแต่งมีการกำหนดค่าที่แตกต่างกันในแต่ละเลเยอร์เช่นบางเลเยอร์อาจกว้างขึ้น แต่บางเลเยอร์ได้รับการตัดแต่งมากขึ้นโมเดลจึงไม่สามารถโหลดได้ด้วย .from_pretrained() ในการกอดใบหน้า ขณะนี้เราใช้ torch.save เพื่อบันทึกรุ่นตัดแต่งและ torch.load เพื่อโหลดรุ่นตัดแต่ง
เราให้บริการสคริปต์อย่างง่ายสำหรับข้อความ geneate โดยใช้โมเดลที่ผ่านการฝึกอบรมมาก่อน / ตัดแต่ง / ตัดแต่งด้วยการฝึกอบรมหลังการฝึกอบรม
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
คำแนะนำข้างต้นจะปรับใช้ LLM ของคุณในเครื่อง
สำหรับการประเมินประสิทธิภาพของแบบจำลองการตัดแต่งเราติดตาม LM-Evaluation-Harness เพื่อประเมินรูปแบบ:
lm-evaluation-harness จุดตรวจสอบที่ปรับจากขั้นตอนการฝึกอบรมจะถูกบันทึกในรูปแบบต่อไปนี้: - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
จัดเรียงไฟล์ด้วยคำสั่งต่อไปนี้:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
หากคุณต้องการประเมิน checkpoint-200 ให้ตั้งค่า Epoch Equalts เป็น 200 โดย export epoch=200
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
ที่นี่แทนที่ PATH_TO_PRUNE_MODEL และ PATH_TO_SAVE_TUNE_MODEL ด้วยเส้นทางที่คุณบันทึกโมเดลตัดแต่งและโมเดลที่ปรับแล้วและ PATH_OR_NAME_TO_BASE_MODEL สำหรับการโหลดไฟล์การกำหนดค่าของรุ่นฐาน
[อัปเดต]: เราอัปโหลดสคริปต์ไปยังกระบวนการประเมินผลหากคุณต้องการประเมินโมเดลตัดแต่งด้วยจุดตรวจสอบที่ปรับแต่ง เพียงใช้คำสั่งต่อไปนี้:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
แทนที่ข้อมูลที่จำเป็นของโมเดลของคุณในคำสั่ง อันสุดท้ายจะใช้ซ้ำมากกว่ายุคที่แตกต่างกันหากคุณต้องการประเมินจุดตรวจหลายแห่งในคำสั่งเดียว ตัวอย่างเช่น:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
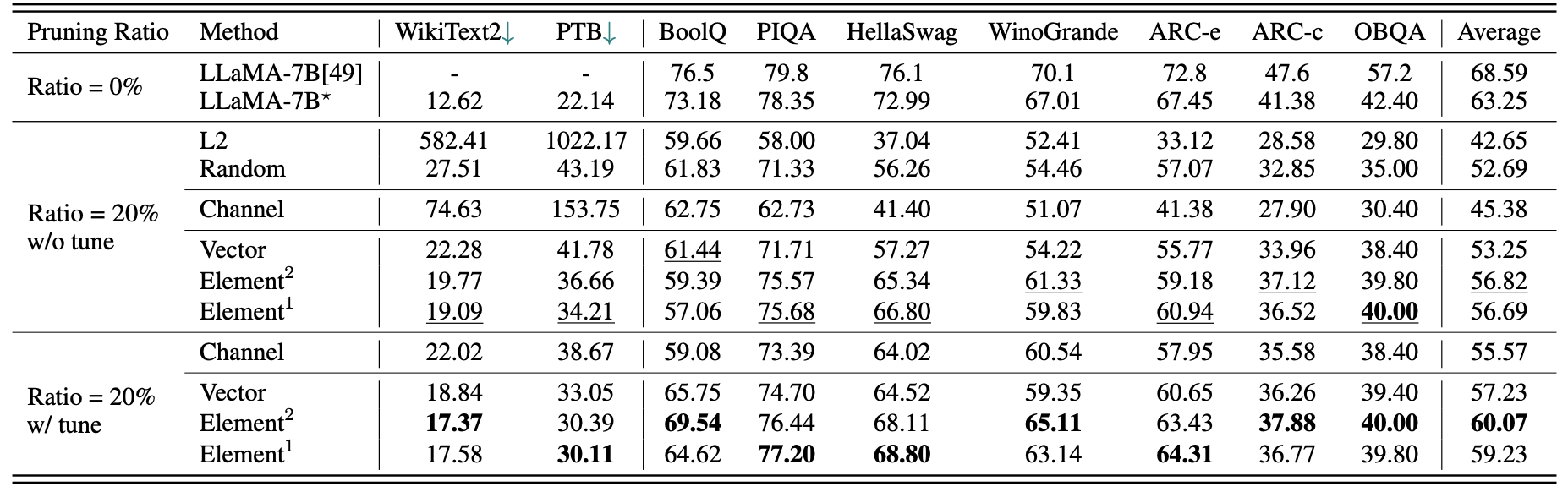
ผลลัพธ์เชิงปริมาณสั้น ๆ สำหรับ LLAMA-7B:
ผลลัพธ์สำหรับ Vicuna-7b:
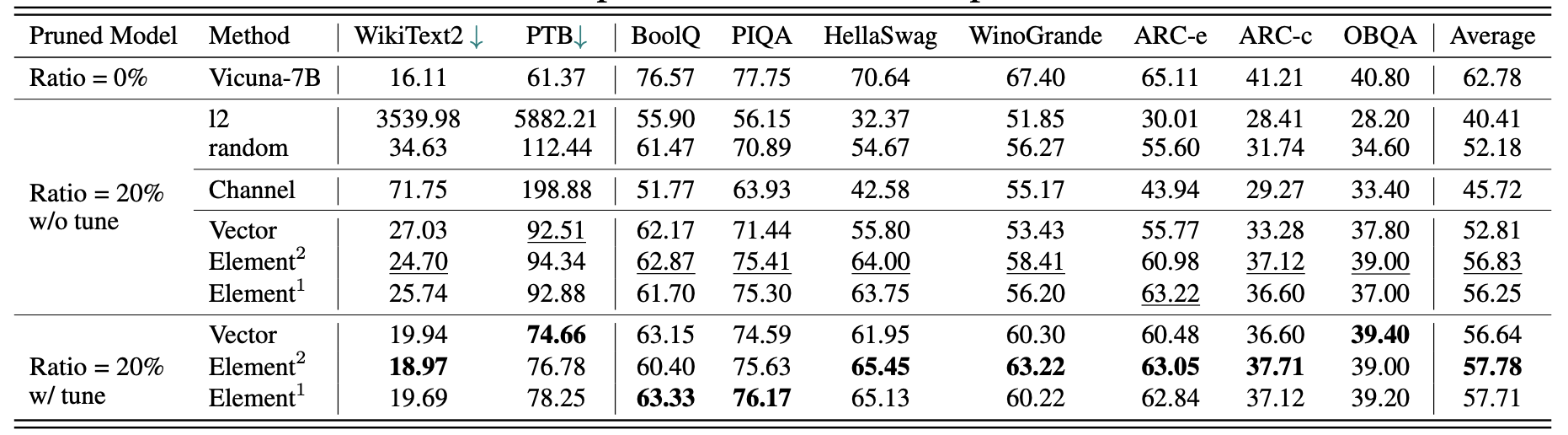
ผลลัพธ์สำหรับ chatglm-6b:
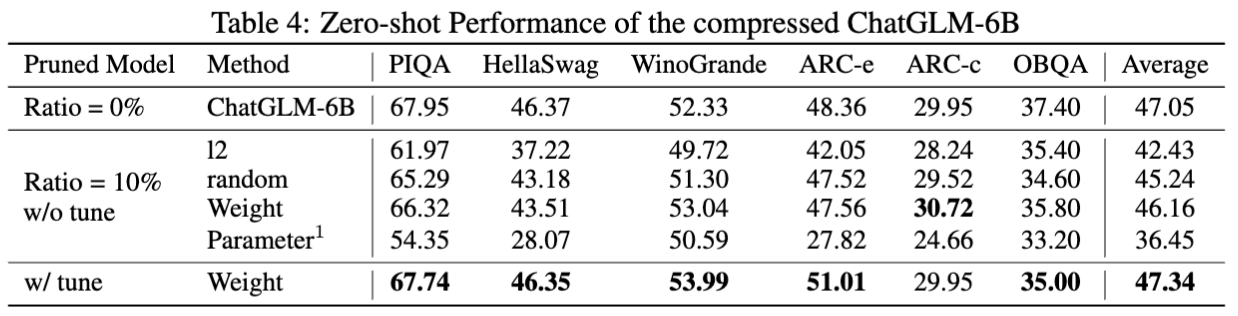
สถิติสำหรับแบบจำลองการตัดแต่ง:
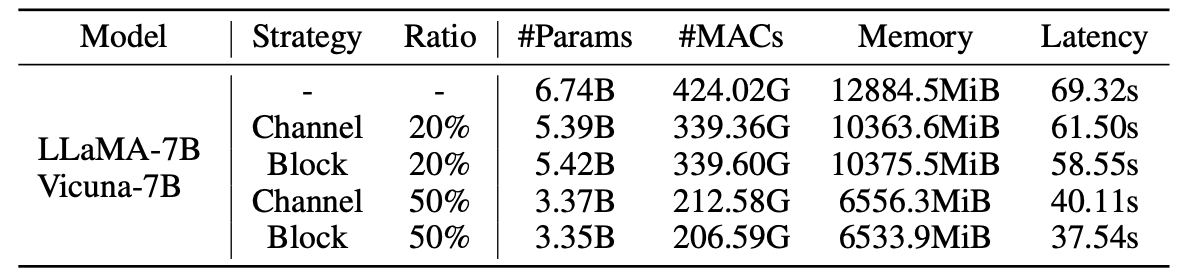
ผลลัพธ์ของ LLM-pruner พร้อมตัวอย่าง 2.59m:
| อัตราส่วนการตัดแต่ง | #param | หน่วยความจำ | ความหน่วงแฝง | การเร่งความเร็ว | บูลค์ | Piqa | Hellaswag | Winogrande | ส่วนโค้ง | ARC-C | OBQA | เฉลี่ย |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLAMA-7B | 6.74b | 12884.5MIB | 69.32s | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| LLAMA-5.4B กับ Alpaca (50K) | 5.47b | 10488.4MIB | 58.55s | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| LLAMA-5.4B กับ LAMINI (2.59M) | 5.47b | 10488.4MIB | 58.55s | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40.70 | 38.80 | 62.36 |
ผลลัพธ์เพิ่มเติมสามารถพบได้ในกระดาษ
| รุ่นดั้งเดิม | เอาท์พุท | รุ่นตัดแต่ง | เอาท์พุท |
|---|---|---|---|
| LLAMA-7B | จักรวาลเป็นพื้นที่ว่างเวลาเวลาและพลังงานที่มีอยู่ มันรวมถึงสสารและพลังงานทั้งหมดไม่ว่าจะมองเห็นได้หรือไม่และในความเป็นจริงทั้งจักรวาลนั้นมองไม่เห็น มีหลายทฤษฎีเกี่ยวกับต้นกำเนิดและชะตากรรมที่ดีที่สุด ... | LLAMA-5.4B | จักรวาลเป็นพื้นที่ว่างเวลาเวลาและพลังงานที่มีอยู่ กฎหมายที่ประกอบขึ้นเป็นฟิสิกส์ - อิเล็กตรอนโคจรรอบอะตอมแม่เหล็กดึงดูดวัตถุอื่น ๆ ดาวเคราะห์โคจรรอบดวงอาทิตย์ - มีความสอดคล้องกัน ... |
| Vicuna-7b | 10 ขั้นตอนในการสร้างแอพ iOS: 1. การวิจัยและพัฒนาความคิด 2. ตัดสินใจเกี่ยวกับแพลตฟอร์มที่คุณต้องการใช้ (iOS, Android หรือทั้งสองอย่าง) 3. สร้างแผนและงบประมาณ 4. จ้างทีมนักพัฒนา 5. ออกแบบส่วนต่อประสานผู้ใช้ (UI) 6. พัฒนาอินเทอร์เฟซผู้ใช้ (UI) 7. ทดสอบและวนซ้ำบนแอพ 8. ส่งแอพไปที่ App Store 9. เพิ่มประสิทธิภาพแอพสำหรับประสิทธิภาพและประสบการณ์การใช้งาน (UX) 10. ตลาดและโปรโมตแอพ | Vicuna-5.4b | 10 ขั้นตอนในการสร้างแอพ iOS: 1 วางแผนแอปของคุณ: ตัดสินใจว่าควรทำอย่างไรสิ่งที่จะเป็นอย่างไรและจะมีค่าใช้จ่ายในการสร้างอะไร 2. จ้างนักพัฒนา: นักพัฒนา iOS ที่ดีจะช่วยให้คุณออกแบบส่วนต่อประสานผู้ใช้สร้างแอพและตรวจสอบให้แน่ใจว่าไม่มีข้อผิดพลาด 3. สร้างส่วนต่อประสานผู้ใช้: นี่คือที่ที่เวทมนตร์เกิดขึ้น ส่วนต่อประสานผู้ใช้แอพของคุณจะได้รับการออกแบบและล้อเลียน ณ จุดนี้ ... |
| chatglm-6b | เขียนบทกวีเกี่ยวกับความรักและความสงบสุข ท่ามกลางความเร่งรีบและคึกคักของชีวิตฉันพบว่าความรักของคุณสงบสุข มันเป็นความรู้สึกที่ไม่สามารถถ่ายทอดได้การเชื่อมต่อที่ไม่สามารถห่างไกลได้ ด้วยรอยยิ้มดวงตาของคุณอ้อมกอดของคุณฉันรู้สึกถึงความเป็นเจ้าของที่มีเพียงคุณเท่านั้นที่สามารถให้ได้ มันเป็นความรักที่คงอยู่ตลอดไปความรักที่ไม่สามารถเอาชนะได้ ... | chatglm-5.6b | เขียนบทกวีเกี่ยวกับความรักและความสงบสุข ความรักและความสงบสองสิ่งที่ยอดเยี่ยมเช่นนี้ ความปรารถนาอันบริสุทธิ์และไม่มีที่สิ้นสุดในใจของฉัน และทั้งคู่ฉันต้องแสวงหา นานนานฉันรู้ .. ความรักฉันรู้ว่าเป็นความรู้สึกของการเป็นหุ้นส่วนที่สมบูรณ์แบบในทุกแง่มุม และสันติภาพฉันต้องการมันมากวันหนึ่ง |
เนื่องจากการเปลี่ยนแปลงในรุ่นของรุ่นและ repos ที่ใช้ในโครงการนี้เราแสดงปัญหาเวอร์ชันที่รู้จักและรุ่นเฉพาะที่จำเป็นในการทำซ้ำวิธีการของเรา:
หากคุณพบว่าโครงการนี้มีประโยชน์โปรดอ้างอิง
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


