LLM Pruner
1.0.0
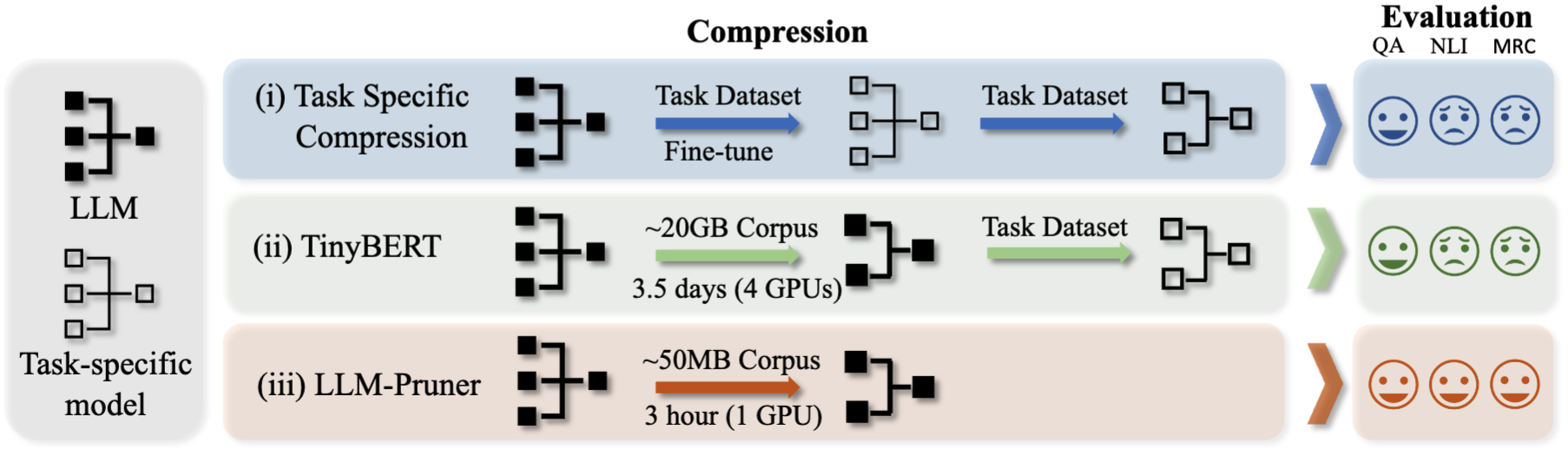
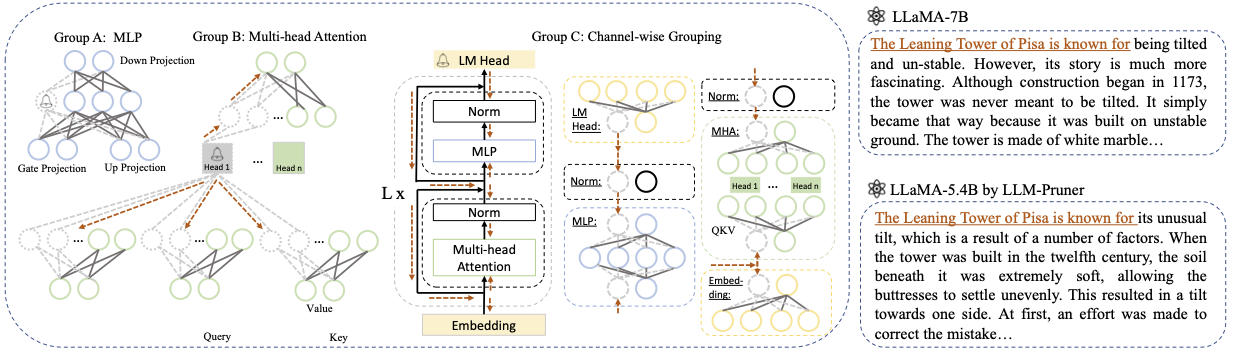
LLM-Pruner: Über das strukturelle Beschneiden großer Sprachmodelle [ARXIV]
Xinyin MA, Gongfan Fang, Xinchao Wang
Nationale Universität von Singapur
.from_pretrained() zum Laden des Modells. Treten Sie unserer Wechat -Gruppe für einen Chat bei:
pip install -r requirement.txt
bash script/llama_prune.sh
Dieses Skript würde das Lama-7b-Modell mit 20% igen Parametern komprimieren. Alle vorgeborenen Modelle und der Datensatz würden automatisch heruntergeladen, sodass Sie die Ressource nicht manuell herunterladen müssen. Wenn Sie dieses Skript zum ersten Mal ausführen, müssen Sie einige Zeit benötigen, um das Modell und den Datensatz herunterzuladen.
Es dauert drei Schritte, um ein LLM zu beschneiden:
Nach dem Beschneiden und nach dem Training folgen wir der Bewertung der LM-Bewertung.
? Lama/Lama-2-Beschneidung mit ~ 20% -Parametern beschnitten:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
Argumente:
Base model : Wählen Sie das Basismodell aus Lama oder Lama-2 und übergeben Sie die pretrained_model_name_or_path an --base_model . Der Modellname wird für AutoModel.from_pretrained verwendet. From_Pretraed, um das vorgebrachte LLM zu laden. Wenn Sie beispielsweise das LLAMA-2 mit 13 Milliarden Parametern verwenden möchten, übergeben Sie meta-llama/Llama-2-13b-hf an- --base_model .Pruning Strategy : Wählen Sie zwischen blockvoller, kanal- oder schichtweise Beschneidung mit den jeweiligen Befehlsoptionen: {--Block_Wise}, {-Channel_Wise}, {--Layer_Wise--Layer-Nummer_OF_Layers}. Geben Sie zum Block-Beschneiden die zu beschnittenen Start- und Endschichten an. Das kanal-wise-Beschneidung erfordert keine zusätzlichen Argumente. Verwenden Sie zum Schichtbeschnitten -Layer Number_OF_Layers, um die gewünschte Anzahl von Schichten anzugeben, die nach dem Beschneiden aufbewahrt werden müssen.Importance Criterion : Wählen Sie mit dem Argument -Pruner_type aus L1, L2, zufällig oder Taylor aus. Wählen Sie für den Taylor Pruner eine der folgenden Optionen aus: vectorize, param_second, param_first, param_mix. Standardmäßig wird param_mix verwendet, das approximierte hessische und erster Ordnung Gradienten kombiniert. Wenn Sie L1, L2 oder zufällig verwenden, sind keine zusätzlichen Argumente erforderlich.Pruning Ratio : Gibt das Schnittverhältnis von Gruppen an. Es unterscheidet sich von der Schnittrate von Parametern, da Gruppen als minimale Einheiten entfernt werden.Device und Eval_device : Beschneiden und Bewertung können auf verschiedenen Geräten durchgeführt werden. Taylor-basierte Methoden erfordern während des Beschneidens eine Rückwärtsberechnung, die möglicherweise einen signifikanten GPU-RAM erfordern. Unsere Implementierung verwendet die CPU zur Wichtigkeitsschätzung (unterstützt auch die GPU, einfach verwenden Sie -Geräte -CUDA). Eval_Device wird verwendet, um das beschnittene Modell zu testen. Wenn Sie Vicuna ausprobieren möchten, geben Sie bitte das Argument --base_model zum Pfad zum Vicuna -Gewicht. Bitte folgen Sie https://github.com/lm-sys/fastchat, um Vicuna-Gewichte zu erhalten.
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
Weitere Informationen finden Sie im Beispiel/Baichuan
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
Stellen Sie sicher, dass Sie PATH_TO_PRUNE_MODEL durch den Pfad zum geschnittenen Modell in Schritt 1 ersetzen, und ersetzen Sie PATH_TO_SAVE_TUNE_MODEL durch den gewünschten Ort, an dem Sie das abgestimmte Modell speichern möchten.
Tipp : Das Training LLAMA-2 in Float16 wird nicht empfohlen und ist dafür bekannt, NAN zu produzieren. Als solches sollte das Modell in Bfloat16 trainiert werden.
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
Verwenden Sie für das beschnittene Modell einfach den folgenden Befehl, um Ihr Modell zu laden.
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
Aufgrund der unterschiedlichen Konfigurationen zwischen Modulen im beschnittenen Modell, bei denen bestimmte Schichten möglicherweise eine größere Breite haben, während andere mehr Beschneidung unterzogen werden, wird es unpraktisch, das Modell unter Verwendung des .from_pretrained() wie durch Umarmung bereitzustellen. Derzeit beschäftigen wir die torch.save , um das beschnittene Modell zu speichern.
Da das beschnittene Modell in jeder Ebene eine unterschiedliche Konfiguration aufweist, wie einige Schichten möglicherweise breiter sind, aber einige Schichten mehr beschnitten wurden, kann das Modell nicht mit dem .from_pretrained() im Umarmungsgesicht geladen werden. Derzeit verwenden wir einfach die torch.save , um das beschnittene Modell und torch.load zu speichern. Laden Sie, um das beschnittene Modell zu laden.
Geneat-Texte bieten ein einfaches Skript an, indem wir vorhandene / beschnittene Modelle / beschnittene Modelle mit nach dem Training unter Verwendung von nach dem Training befindlich sind.
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
In den oben genannten Anweisungen werden Ihre LLMs lokal bereitgestellt.
Zur Bewertung der Leistung des beschnittenen Modells folgen wir LM-Evaluation-HARDES, um das Modell zu bewerten:
lm-evaluation-harness zu erfüllen. Der abgestimmte Checkpoint aus dem nach dem Trainingsschritt speichern würde im folgenden Format gespeichert: - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
Ordnen Sie die Dateien nach den folgenden Befehlen an:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
Wenn Sie den checkpoint-200 bewerten möchten, stellen Sie die Epoche gleich auf 200 durch export epoch=200 ein.
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
Ersetzen Sie hier PATH_TO_PRUNE_MODEL und PATH_TO_SAVE_TUNE_MODEL durch den Pfad, den Sie das beschnittene Modell und das PATH_OR_NAME_TO_BASE_MODEL Modell speichern.
[Update]: Wir laden ein Skript auf einfach den Bewertungsprozess hoch, wenn Sie das beschnittene Modell mit dem abgestimmten Checkpoint bewerten möchten. Verwenden Sie einfach den folgenden Befehl:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
Ersetzen Sie die erforderlichen Informationen Ihres Modells im Befehl. Die letzte wird verwendet, um über verschiedene Epochen zu iterieren, wenn Sie mehrere Kontrollpunkte in einem Befehl bewerten möchten. Zum Beispiel:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
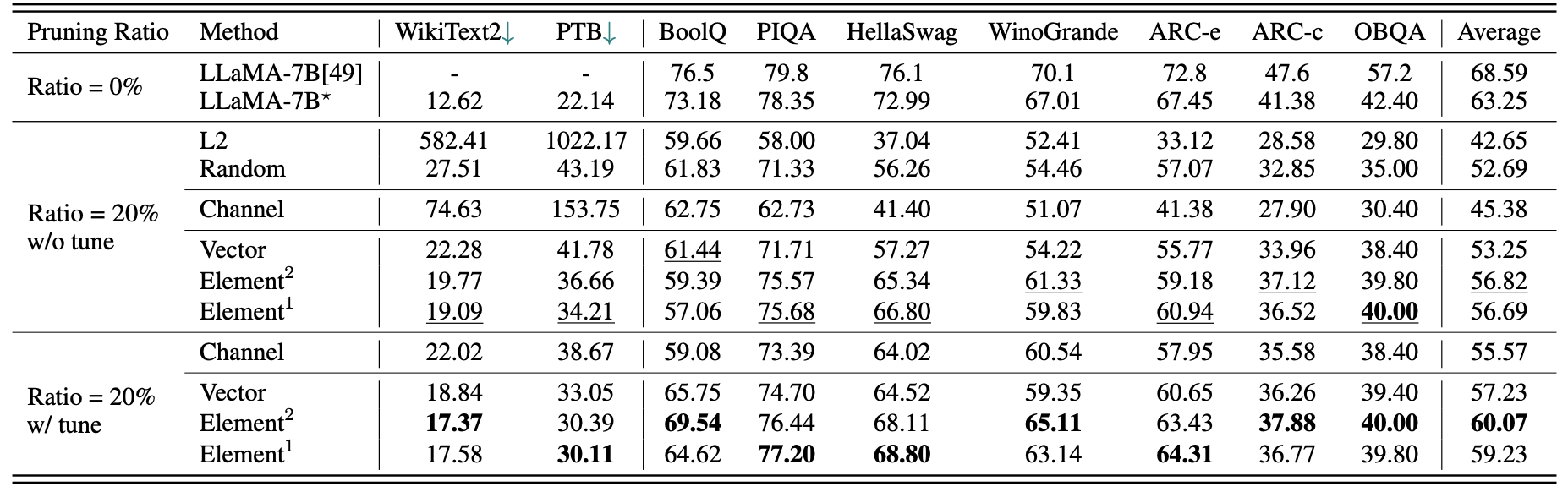
Eine kurze quantitative Ergebnisse für Lama-7b:
Die Ergebnisse für Vicuna-7b:
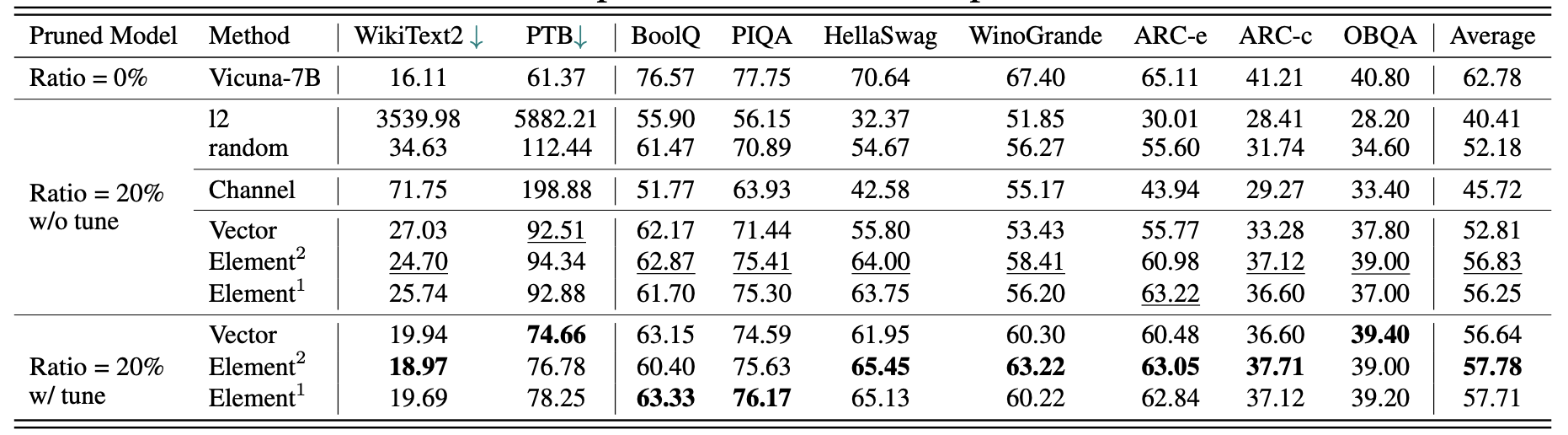
Die Ergebnisse für Chatglm-6b:
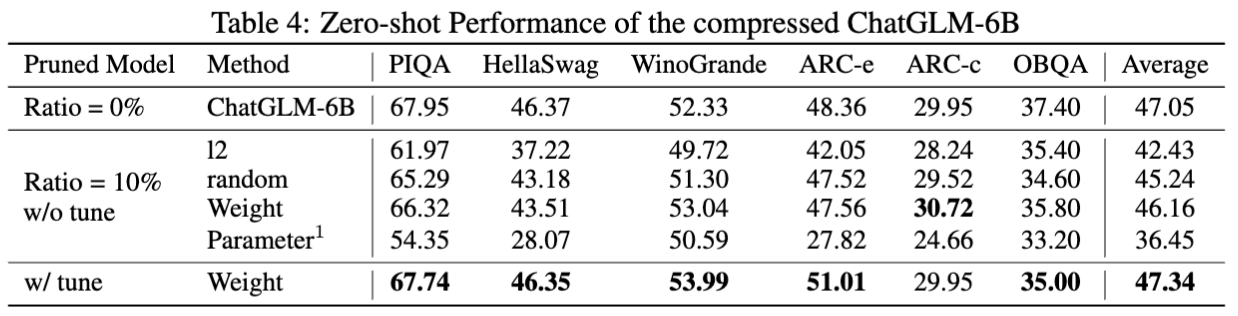
Statistiken für Schnürmodelle:
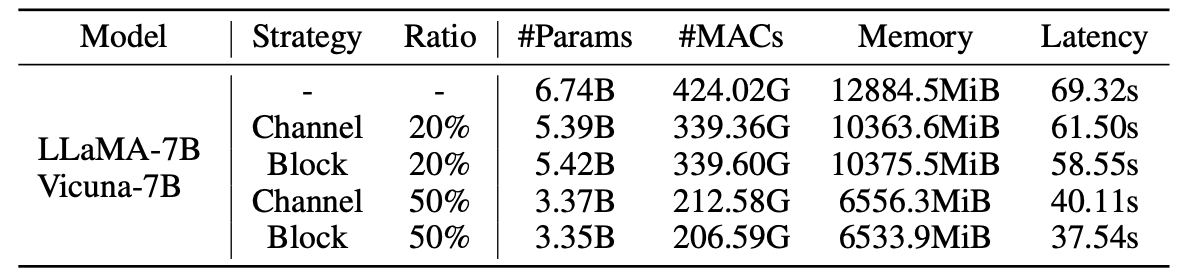
Ergebnisse von LLM-Pruner mit 2,59M-Proben:
| Schnittverhältnis | #Param | Erinnerung | Latenz | Beschleunigung | Boolq | Piqa | Hellaswag | Winogrande | Bogen-e | ARC-C | Obqa | Durchschnitt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lama-7b | 6.74b | 12884.5Mib | 69.32s | 1x | 73.18 | 78,35 | 72.99 | 67.01 | 67,45 | 41.38 | 42.40 | 63,25 |
| Lama-5.4b mit Alpaka (50k) | 5.47b | 10488.4mib | 58.55s | 1.18x | 64,62 | 77,20 | 68.80 | 63.14 | 64.31 | 36.77 | 39,80 | 59.23 |
| Lama-5.4b mit Lamini (2,59 m) | 5.47b | 10488.4mib | 58.55s | 1.18x | 76,57 | 77,37 | 66.60 | 65,82 | 70,62 | 40.70 | 38.80 | 62.36 |
Weitere Ergebnisse finden Sie im Papier.
| Originalmodell | Ausgabe | Beschnittenes Modell | Ausgabe |
|---|---|---|---|
| Lama-7b | Das Universum ist die Gesamtheit von Raum, Zeit, Materie und Energie, die existiert. Es umfasst alle Materie und Energie, ob sichtbar oder nicht, und tatsächlich ist das gesamte Universum unsichtbar. Es gibt viele Theorien in Bezug auf seine Herkunft und das ultimative Schicksal ... | Lama-5.4b | Das Universum ist die Gesamtheit von Raum, Zeit, Materie und Energie, die existiert. Die Gesetze, aus denen sich die Physik zusammensetzt - Elektronen, die Atome umkreisen, Magnete, die andere Objekte anziehen, Planeten, die die Sonne umkreisen - waren konsistent über ... |
| Vicuna-7b | 10 Schritte zum Erstellen einer iOS -App: 1. Forschung und Entwicklung der Idee. 2. Entscheiden Sie sich für die Plattform, die Sie verwenden möchten (iOS, Android oder beides). 3. Erstellen Sie einen Plan und ein Budget. 4. Mieten Sie ein Team von Entwicklern. 5. Entwerfen Sie die Benutzeroberfläche (UI). 6. Entwickeln Sie die Benutzeroberfläche (UI). 7. Testen Sie und iterieren Sie die App. 8. Senden Sie die App in den App Store. 9. Optimieren Sie die App für Leistung und Benutzererfahrung (UX). 10. Markt und fördern Sie die App. | Vicuna-5.4b | 10 Schritte zum Erstellen einer iOS -App: 1. Planen Sie Ihre App: Entscheiden Sie, was sie tun soll, wie sie aussehen und wie es kostet, sie zu bauen. 2. Mieten Sie einen Entwickler: Ein guter iOS-Entwickler hilft Ihnen beim Entwerfen der Benutzeroberfläche, erstellt die App und stellt sicher, dass sie fehlerfrei ist. 3. Erstellen Sie eine Benutzeroberfläche: Hier passiert die Magie. Die Benutzeroberfläche Ihrer App wird an diesem Punkt entworfen und verspottet ... |
| Chatglm-6b | Schreiben Sie eine Gedichte über Liebe und Frieden. Inmitten des Trubels des Lebens finde ich Ihre Liebe einen beruhigenden Frieden. Es ist ein Gefühl, das nicht vermittelt werden kann, eine Verbindung, die nicht distanziert werden kann. Mit Ihrem Lächeln, Ihren Augen, Ihrer Umarmung habe ich ein Gefühl der Zugehörigkeit, das nur Sie geben können. Es ist eine Liebe, die für immer dauert, eine Liebe, die nicht besiegen kann ... | Chatglm-5.6b | Schreiben Sie eine Gedichte über Liebe und Frieden. Liebe und Frieden, zwei so wundervolle Dinge ein reines und endloses Verlangen in meinem Herzen und beide, ich muss nach einer langen, langen Zeit suchen. |
Aufgrund von Änderungen in den in diesem Projekt verwendeten Versionen von Modellen und Repos haben wir einige bekannte Versionsprobleme und die spezifischen Versionen aufgeführt, die zur Reproduktion unserer Methode erforderlich sind:
Wenn Sie dieses Projekt nützlich finden, zitieren Sie bitte
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


