language_modeling_via_stochastic_processes
1.0.0
[紙] [開放評論] [長視頻]
ICLR口服2022
Rose E Wang,Esin Durmus,Noah Goodman,Tatsunori Hashimoto

摘要:現代語言模型可以生成高質量的短文。但是,它們在生成更長的文本時通常蜿蜒曲折或不連貫。這些問題是由下一步的語言建模目標引起的。自學學習的最新工作表明,模型可以通過對比度學習學習良好的潛在表示,這對於歧視性任務可能是有效的。我們的工作分析了對比表示在生成任務(如長文本生成)中的應用。我們提出了一種利用約束表示的方法,我們稱之為時間控制(TC)。 TC首先了解目標文本域的對比表示,然後通過解碼這些表示形式生成文本。與各種文本域中的特定於域特異性方法和微調GPT2相比,TC競爭性地針對有關話語相干性學習句子表示的特定方法。在長期文本生成設置上,TC在訂購方面保留文本結構(增強 +15%)和文本長度一致性(高達 +90%更好)。
內容:
setup.sh中的命令遵循conda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
此存儲庫包含除兩個數據集(Wikihow和配方NLG)以外的所有數據集。說明如下。
其他四個數據集已經在此存儲庫中。
Wikihow數據集需要從此鏈接下載。這是一個PKL文件,應作為path/2/repo/data/wikihow/wiki_how_data.pkl下達。
本文中使用的Wikisection數據集已經包含。
它來自先前的工作 - 特別是我們使用了英國城市Wikipedia文章。
需要下載配方NLG數據集。下載食譜NLG數據集,並將數據放在encoder/data/recipe_nlg下。
本文中使用的TM2數據集已包含。它來自TM2餐廳搜索數據集。
本文中使用的tickettalk數據集已包含。
可以找到作為tickettalk數據集(所有JSON文件)。
在運行實驗之前, cd encoder/code; source init_env.sh
在encoder/code/scripts/run_ou.py中,將變量名稱ckpt_dir設置為您的檢查點目錄。
可以在encoder/code/scripts/train_encoders.sh上找到訓練編碼器(TC,VAE,Brownian,Infonce)的腳本。
在運行實驗之前, cd encoder/code; source init_env.sh
在encoder/code/scripts/run_discourse.py和encoder/code/src/systems/discourse_system.py中,將正確的路徑設置為數據目錄和repo。
可以在encoder/code/scripts/discourse.sh上找到用於運行話語連貫實驗的腳本。
為了培訓解碼器,您需要使用目錄decoder/examples/pytorch/language-modeling/ 。
訓練腳本可以在decoder/examples/pytorch/language-modeling/train_encoders.sh找到解碼器。確保更改path2repo變量。
您需要在run_time_clm.py中適當地將目錄更改為數據目錄
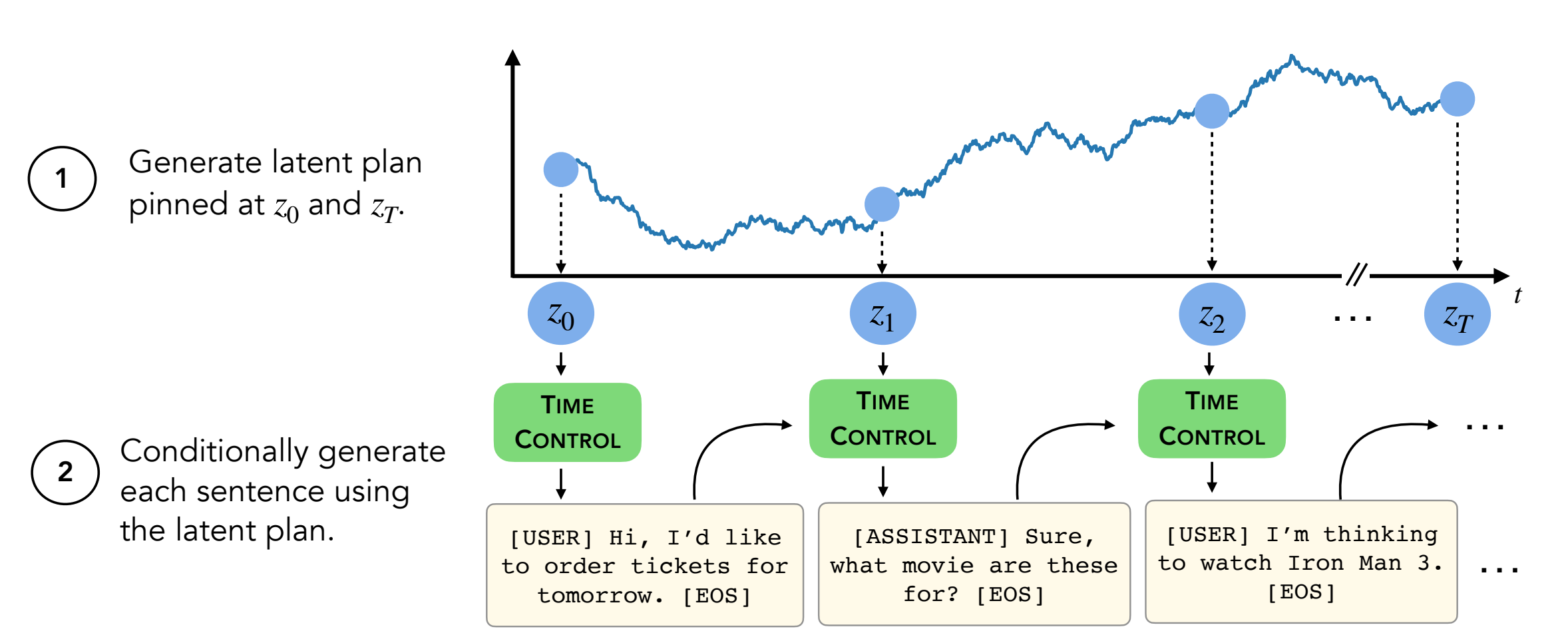
對於decoder/transformers/examples/pytorch/text-generation/ 。
可以在decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh找到用於生成文本和測量每節不匹配的文本和測量不匹配的腳本。
可以在decoder/transformers/examples/pytorch/text-generation/long_generation.sh中找到用於生成長文本的腳本。
要收集所有指標,請查看analysis/run_analysis.sh 。您可以通過source analysis/run_analysis.sh運行所有評估。
請記住,將WANDB用戶名和項目名稱更改為您在編碼器和解碼器實驗中列出的內容。


