language_modeling_via_stochastic_processes
1.0.0
[Documento] [Revisión abierta] [Video largo]
ICLR Oral 2022
Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto

Resumen: Los modelos de lenguaje moderno pueden generar textos cortos de alta calidad. Sin embargo, a menudo serpentean o son incoherentes cuando se generan textos más largos. Estos problemas surgen del objetivo de modelado de idiomas de la próxima prueba. El trabajo reciente en el aprendizaje auto-supervisado sugiere que los modelos pueden aprender buenas representaciones latentes a través del aprendizaje contrastante, lo que puede ser efectivo para tareas discriminativas. Nuestro trabajo analiza la aplicación de representaciones contrastantes para tareas generativas, como la generación de texto largo. Proponemos un enfoque para aprovechar representaciones constructivas, que llamamos control de tiempo (TC). TC primero aprende una representación contrastante del dominio de texto de destino, luego genera texto mediante la decodificación de estas representaciones. En comparación con los métodos específicos del dominio y el ajuste de GPT2 en una variedad de dominios de texto, TC se desempeña de manera competitiva a los métodos específicos para el aprendizaje de representaciones de oraciones sobre la coherencia del discurso. En la configuración de generación de texto largo, TC conserva la estructura del texto tanto en términos de orden (hasta +15% mejor) como la consistencia de la longitud del texto (hasta +90% mejor).
Contenido:
setup.shconda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
Este repositorio contiene todos menos dos conjuntos de datos (wikihow y receta nlg) . Las instrucciones están a continuación.
Los otros cuatro conjuntos de datos ya están en este repositorio.
El conjunto de datos WikiHow debe descargarse de este enlace. Es un archivo PKL que debe ir como path/2/repo/data/wikihow/wiki_how_data.pkl .
El conjunto de datos de wikisection utilizado en este documento ya está incluido.
Viene de este trabajo anterior: específicamente, utilizamos los artículos de Wikipedia de la ciudad inglesa.
El conjunto de datos NLG de receta debe descargarse. Descargue el conjunto de datos NLG de receta y coloque los datos en encoder/data/recipe_nlg .
El conjunto de datos TM2 utilizado en este documento ya está incluido. Vino del conjunto de datos de búsqueda de restaurantes TM2.
El conjunto de datos TicketTalk utilizado en este documento ya está incluido.
Se puede encontrar como el conjunto de datos TicketTalk (todos los archivos JSON).
Antes de ejecutar experimentos, cd encoder/code; source init_env.sh
En encoder/code/scripts/run_ou.py , establezca el nombre de la variable ckpt_dir en su directorio de punto de control.
El guión para capacitar a los codificadores (TC, VAE, Brownian, Infonce) se puede encontrar en encoder/code/scripts/train_encoders.sh .
Antes de ejecutar experimentos, cd encoder/code; source init_env.sh
En encoder/code/scripts/run_discourse.py y encoder/code/src/systems/discourse_system.py , establezca las rutas correctas en su directorio de datos y repose.
El script para ejecutar los experimentos de coherencia del discurso se puede encontrar en encoder/code/scripts/discourse.sh .
Para capacitar al decodificador, deberá estar en decoder/examples/pytorch/language-modeling/ .
El script para capacitar al decodificador se puede encontrar en decoder/examples/pytorch/language-modeling/train_encoders.sh . Asegúrese de cambiar la variable path2repo .
Deberá cambiar los directorios a su directorio de datos según corresponda en run_time_clm.py
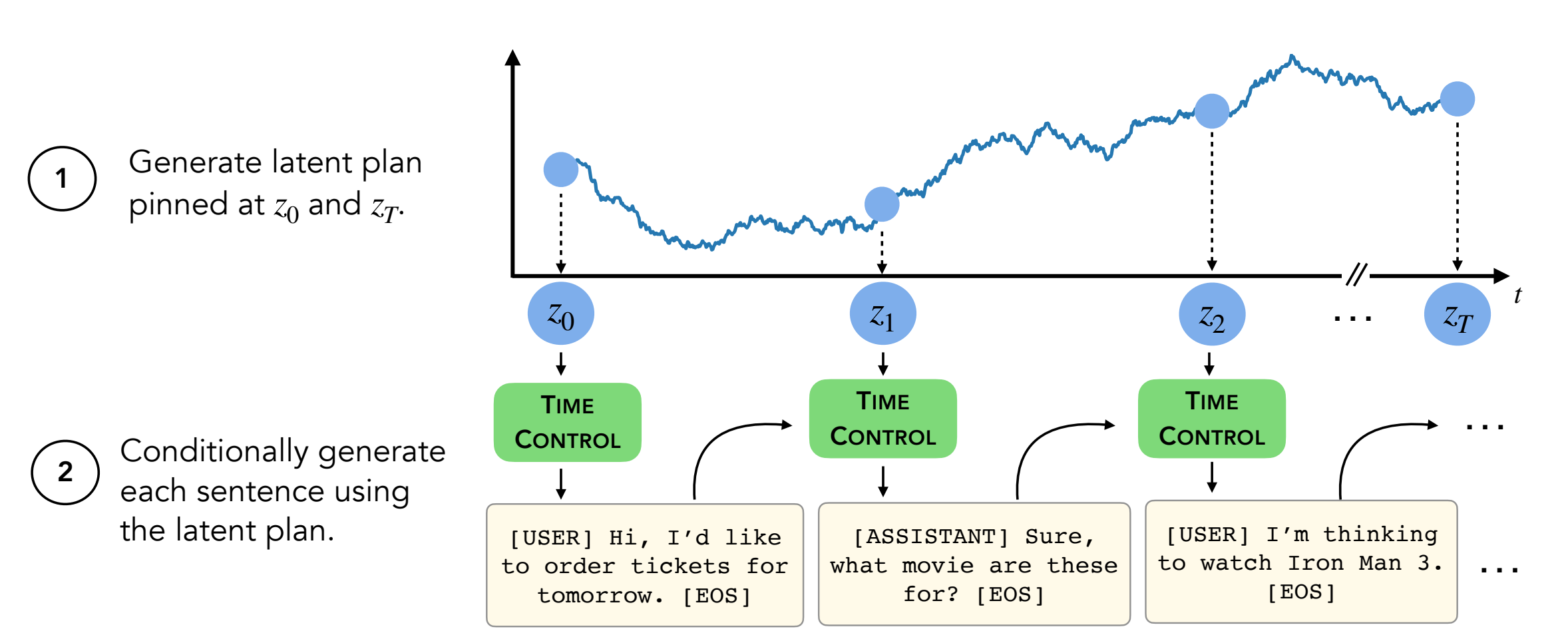
Para generar textos, deberá estar en Directory decoder/transformers/examples/pytorch/text-generation/ .
El script para generar mensajes de texto y no coincidencias de longitud por sección se puede encontrar en decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh .
El script para generar textos largos se puede encontrar en decoder/transformers/examples/pytorch/text-generation/long_generation.sh .
Para recopilar todas las métricas, consulte analysis/run_analysis.sh . Puede ejecutar todas las evaluaciones con source analysis/run_analysis.sh .
Recuerde cambiar el nombre de usuario WandB y el nombre del proyecto como lo que mencionó en los experimentos de codificadores y decodificadores.


