language_modeling_via_stochastic_processes
1.0.0
[Paper] [Open Review] [วิดีโอยาว]
ICLR ORAL 2022
Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto

บทคัดย่อ: โมเดลภาษาที่ทันสมัยสามารถสร้างข้อความสั้น ๆ คุณภาพสูง อย่างไรก็ตามพวกเขามักจะคดเคี้ยวหรือไม่ต่อเนื่องกันเมื่อสร้างข้อความที่ยาวขึ้น ปัญหาเหล่านี้เกิดขึ้นจากวัตถุประสงค์การสร้างแบบจำลองภาษาแบบเปิดใหม่เท่านั้น งานล่าสุดในการเรียนรู้ที่ดูแลตนเองชี้ให้เห็นว่าแบบจำลองสามารถเรียนรู้การเป็นตัวแทนแฝงที่ดีผ่านการเรียนรู้แบบตรงกันข้ามซึ่งอาจมีประสิทธิภาพสำหรับงานที่เลือกปฏิบัติ งานของเราวิเคราะห์การประยุกต์ใช้การเป็นตัวแทนที่ตรงกันข้ามสำหรับงานสร้างเช่นการสร้างข้อความยาว เราเสนอวิธีหนึ่งสำหรับการใช้ประโยชน์จากการเป็นตัวแทนที่ จำกัด ซึ่งเราเรียกว่าการควบคุมเวลา (TC) TC ก่อนเรียนรู้การเป็นตัวแทนของโดเมนข้อความเป้าหมายจากนั้นสร้างข้อความโดยการถอดรหัสจากการเป็นตัวแทนเหล่านี้ เมื่อเปรียบเทียบกับวิธีเฉพาะโดเมนและการปรับแต่ง GPT2 ในโดเมนข้อความที่หลากหลาย TC ดำเนินการกับวิธีการเฉพาะสำหรับการเรียนรู้ประโยคการเรียนรู้เกี่ยวกับการเชื่อมโยงวาทกรรม ในการตั้งค่าการสร้างข้อความยาว TC รักษาโครงสร้างข้อความทั้งในแง่ของการสั่งซื้อ (ดีกว่า +15%) และความสอดคล้องของความยาวข้อความ (ดีกว่า +90% ดีกว่า)
สารบัญ:
setup.shconda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
repo นี้มีชุดข้อมูลทั้งหมด แต่สองชุด (wikihow และสูตร NLG) คำแนะนำอยู่ด้านล่าง
ชุดข้อมูลอีกสี่ชุดอยู่ใน repo นี้แล้ว
ชุดข้อมูล WikiHow จะต้องดาวน์โหลดจากลิงค์นี้ มันเป็นไฟล์ PKL ที่ควรอยู่ภายใต้ path/2/repo/data/wikihow/wiki_how_data.pkl
ชุดข้อมูล Wikisection ที่ใช้ในบทความนี้รวมอยู่แล้ว
มันมาจากงานก่อนหน้านี้ - โดยเฉพาะเราใช้บทความ Wikipedia ของเมืองอังกฤษ
ต้องดาวน์โหลดชุดข้อมูลสูตร NLG ดาวน์โหลดชุดข้อมูลสูตร NLG และวางข้อมูลภายใต้ encoder/data/recipe_nlg
ชุดข้อมูล TM2 ที่ใช้ในบทความนี้รวมอยู่แล้ว มันมาจากชุดข้อมูลการค้นหาร้านอาหาร TM2
ชุดข้อมูล Tickettalk ที่ใช้ในบทความนี้รวมอยู่แล้ว
มันสามารถพบได้เป็นชุดข้อมูล Tickettalk (ไฟล์ JSON ทั้งหมด)
ก่อนที่จะเรียกใช้การทดลอง cd encoder/code; source init_env.sh
ใน encoder/code/scripts/run_ou.py ตั้งค่าชื่อตัวแปร ckpt_dir เป็นไดเรกทอรีจุดตรวจสอบของคุณ
สคริปต์สำหรับการฝึกอบรมตัวเข้ารหัส (TC, VAE, Brownian, Infonce) สามารถพบได้ที่ encoder/code/scripts/train_encoders.sh
ก่อนที่จะเรียกใช้การทดลอง cd encoder/code; source init_env.sh
ใน encoder/code/scripts/run_discourse.py และ encoder/code/src/systems/discourse_system.py ตั้งค่าเส้นทางที่ถูกต้องไปยังไดเรกทอรีข้อมูลและ repo ของคุณ
สคริปต์สำหรับเรียกใช้การทดลองการเชื่อมโยงวาทกรรมสามารถพบได้ที่ encoder/code/scripts/discourse.sh
สำหรับการฝึกอบรมตัวถอดรหัสคุณจะต้องอยู่ในตัว decoder/examples/pytorch/language-modeling/
สคริปต์สำหรับการฝึกอบรมตัวถอดรหัสสามารถพบได้ที่ decoder/examples/pytorch/language-modeling/train_encoders.sh ตรวจสอบให้แน่ใจว่าได้เปลี่ยนตัวแปร path2repo
คุณจะต้องเปลี่ยนไดเรกทอรีเป็นไดเรกทอรีข้อมูลของคุณตามความเหมาะสมใน run_time_clm.py
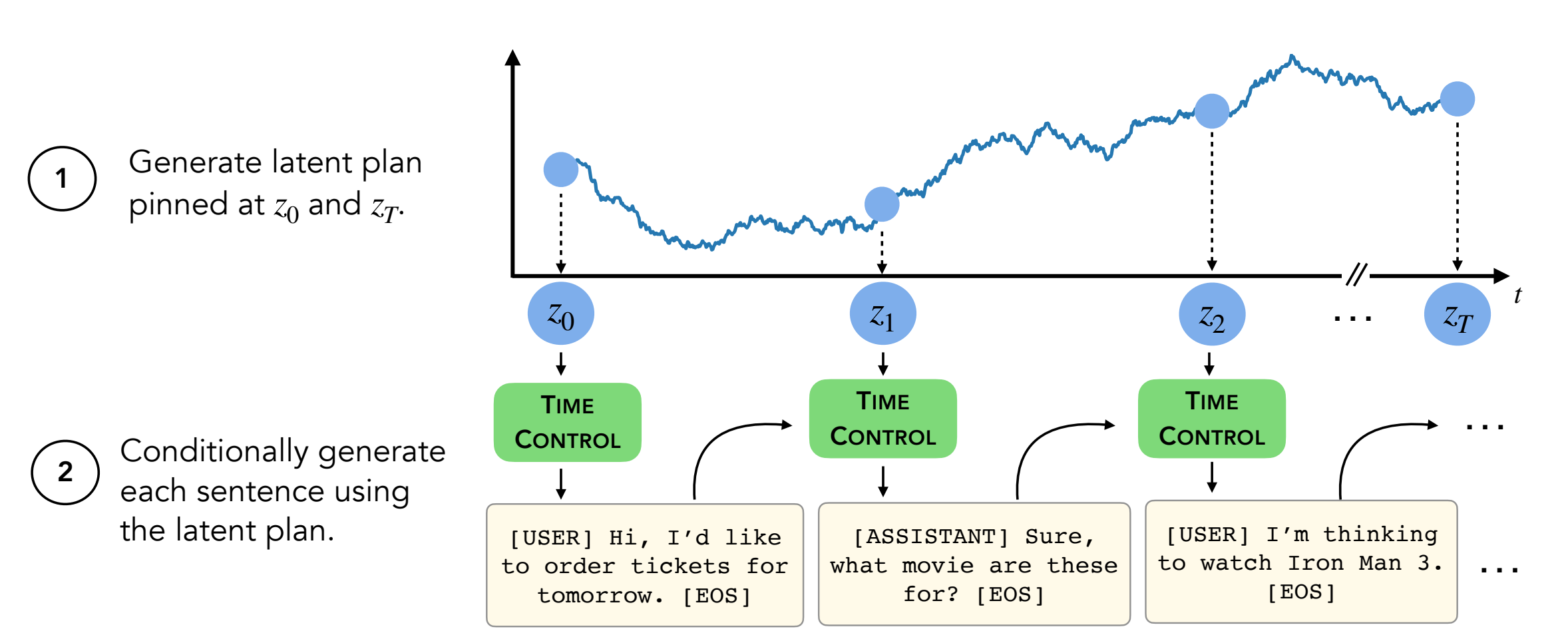
สำหรับการสร้างข้อความคุณจะต้องอยู่ในไดเรกทอรี decoder/transformers/examples/pytorch/text-generation/
สคริปต์สำหรับการสร้างข้อความและการวัดความยาวต่อส่วนไม่ตรงกันสามารถพบได้ที่ decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh
สคริปต์สำหรับการสร้างข้อความยาวสามารถพบได้ที่ decoder/transformers/examples/pytorch/text-generation/long_generation.sh
ในการรวบรวมตัวชี้วัดทั้งหมดให้ตรวจสอบ analysis/run_analysis.sh คุณสามารถเรียกใช้การประเมินทั้งหมดด้วย source analysis/run_analysis.sh
อย่าลืมเปลี่ยนชื่อผู้ใช้ Wandb และชื่อโครงการเป็นสิ่งที่คุณระบุไว้ในการทดลองตัวเข้ารหัสและตัวถอดรหัส


