language_modeling_via_stochastic_processes
1.0.0
[纸] [开放评论] [长视频]
ICLR口服2022
Rose E Wang,Esin Durmus,Noah Goodman,Tatsunori Hashimoto

摘要:现代语言模型可以生成高质量的短文。但是,它们在生成更长的文本时通常蜿蜒曲折或不连贯。这些问题是由下一步的语言建模目标引起的。自学学习的最新工作表明,模型可以通过对比度学习学习良好的潜在表示,这对于歧视性任务可能是有效的。我们的工作分析了对比表示在生成任务(如长文本生成)中的应用。我们提出了一种利用约束表示的方法,我们称之为时间控制(TC)。 TC首先了解目标文本域的对比表示,然后通过解码这些表示形式生成文本。与各种文本域中的特定于域特异性方法和微调GPT2相比,TC竞争性地针对有关话语相干性学习句子表示的特定方法。在长期文本生成设置上,TC在订购方面保留文本结构(增强 +15%)和文本长度一致性(高达 +90%更好)。
内容:
setup.sh中的命令遵循conda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
此存储库包含除两个数据集(Wikihow和配方NLG)以外的所有数据集。说明如下。
其他四个数据集已经在此存储库中。
Wikihow数据集需要从此链接下载。这是一个PKL文件,应作为path/2/repo/data/wikihow/wiki_how_data.pkl下达。
本文中使用的Wikisection数据集已经包含。
它来自先前的工作 - 特别是我们使用了英国城市Wikipedia文章。
需要下载配方NLG数据集。下载食谱NLG数据集,并将数据放在encoder/data/recipe_nlg下。
本文中使用的TM2数据集已包含。它来自TM2餐厅搜索数据集。
本文中使用的tickettalk数据集已包含。
可以找到作为tickettalk数据集(所有JSON文件)。
在运行实验之前, cd encoder/code; source init_env.sh
在encoder/code/scripts/run_ou.py中,将变量名称ckpt_dir设置为您的检查点目录。
可以在encoder/code/scripts/train_encoders.sh上找到训练编码器(TC,VAE,Brownian,Infonce)的脚本。
在运行实验之前, cd encoder/code; source init_env.sh
在encoder/code/scripts/run_discourse.py和encoder/code/src/systems/discourse_system.py中,将正确的路径设置为数据目录和repo。
可以在encoder/code/scripts/discourse.sh上找到用于运行话语连贯实验的脚本。
为了培训解码器,您需要使用目录decoder/examples/pytorch/language-modeling/ 。
训练脚本可以在decoder/examples/pytorch/language-modeling/train_encoders.sh找到解码器。确保更改path2repo变量。
您需要在run_time_clm.py中适当地将目录更改为数据目录
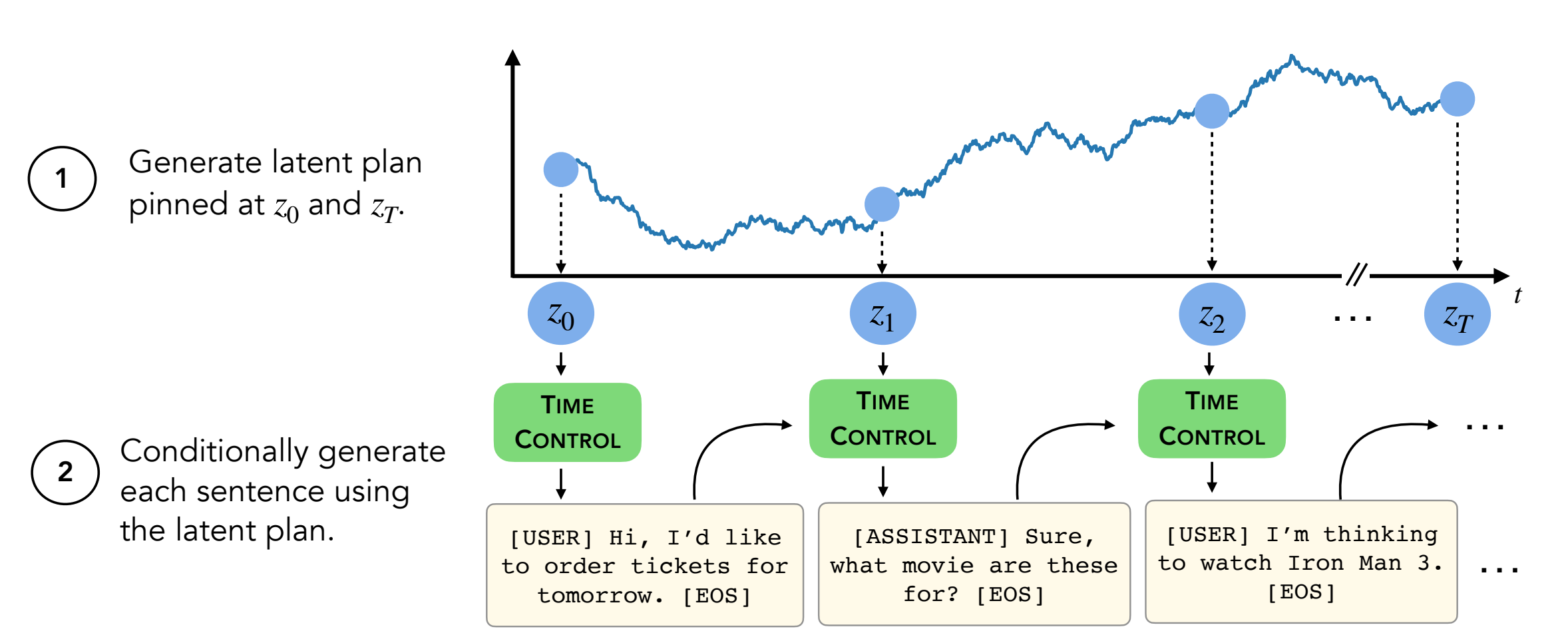
对于生成文本,您需要使用目录decoder/transformers/examples/pytorch/text-generation/ 。
可以在decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh找到用于生成文本和测量每节不匹配的文本和测量不匹配的脚本。
可以在decoder/transformers/examples/pytorch/text-generation/long_generation.sh中找到用于生成长文本的脚本。
要收集所有指标,请查看analysis/run_analysis.sh 。您可以通过source analysis/run_analysis.sh运行所有评估。
请记住,将WANDB用户名和项目名称更改为您在编码器和解码器实验中列出的内容。


