language_modeling_via_stochastic_processes
1.0.0
[Papier] [Open Review] [Langes Video]
ICLR Oral 2022
Rose e Wang, Essin Durmus, Noah Goodman, Tatsunori Hashimoto

Zusammenfassung: Moderne Sprachmodelle können qualitativ hochwertige kurze Texte erzeugen. Sie schlängeln sich jedoch oft oder sind inkohärent, wenn sie längere Texte erzeugen. Diese Themen ergeben sich aus dem erst geeigneten Sprachmodellungsziel. Jüngste Arbeiten beim selbstverletzten Lernen legen nahe, dass Modelle gute latente Darstellungen durch kontrastives Lernen lernen können, was für diskriminative Aufgaben wirksam sein kann. Unsere Arbeit analysiert die Anwendung von kontrastiven Darstellungen für generative Aufgaben wie die lange Textgenerierung. Wir schlagen einen Ansatz vor, um einschränkende Darstellungen zu nutzen, die wir als Time Control (TC) bezeichnen. TC lernt zunächst eine kontrastive Darstellung der Zieltextdomäne und generiert dann Text durch Entschlüsseln aus diesen Darstellungen. Im Vergleich zu domänenspezifischen Methoden und Feinabstimmungs-GPT2 über eine Vielzahl von Textdomänen verfügt TC wettbewerbsfähig mit Methoden, die für Lernsatzdarstellungen in Bezug auf die Kohärenz von Diskursspezifikationen spezifisch sind. Bei langen Einstellungen für die Textgenerierung bewahrt TC die Textstruktur sowohl in Bezug auf die Bestellung (bis zu +15% besser) als auch die Konsistenz der Textlänge (bis zu +90% besser).
Inhalt:
setup.shconda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
Dieses Repo enthält alle bis auf zwei Datensätze (WikiHow und Rezept NLG) . Anweisungen finden Sie unten.
Die anderen vier Datensätze befinden sich bereits in diesem Repo.
Der WikiHow -Datensatz muss aus diesem Link heruntergeladen werden. Es handelt sich um eine PKL -Datei, die unter path/2/repo/data/wikihow/wiki_how_data.pkl gehen sollte.
Der in diesem Papier verwendete Wikisection -Datensatz ist bereits enthalten.
Es stammt aus dieser früheren Arbeit - insbesondere haben wir die Artikeln der englischen Stadt Wikipedia verwendet.
Das Rezept -NLG -Datensatz muss heruntergeladen werden. Laden Sie das Rezept -NLG -Datensatz herunter und legen Sie die Daten unter encoder/data/recipe_nlg .
Der in diesem Papier verwendete TM2 -Datensatz ist bereits enthalten. Es stammte aus dem TM2 -Restaurant -Suchdatensatz.
Der in diesem Papier verwendete Tickettalk -Datensatz ist bereits enthalten.
Es kann als Tickettalk -Datensatz (alle JSON -Dateien) gefunden werden.
Vor dem Ausführen von Experimenten cd encoder/code; source init_env.sh
Setzen Sie in encoder/code/scripts/run_ou.py den Variablennamen ckpt_dir auf Ihr Checkpoint -Verzeichnis.
Das Skript zum Training der Encoder (TC, VAE, Brownian, Infonce) finden Sie unter encoder/code/scripts/train_encoders.sh .
Vor dem Ausführen von Experimenten cd encoder/code; source init_env.sh
Legen Sie in encoder/code/scripts/run_discourse.py und encoder/code/src/systems/discourse_system.py die richtigen Pfade in Ihr Datenverzeichnis und Repo fest.
Das Skript zum Ausführen der Experimente zur Kohärenz von Diskurs finden Sie unter encoder/code/scripts/discourse.sh .
Für die Schulung des Decoders müssen Sie sich im Verzeichnis decoder/examples/pytorch/language-modeling/ befinden.
Das Skript zum Training des Decoders finden Sie unter decoder/examples/pytorch/language-modeling/train_encoders.sh . Stellen Sie sicher, dass Sie die Variable path2repo ändern.
Sie müssen run_time_clm.py Verzeichnis
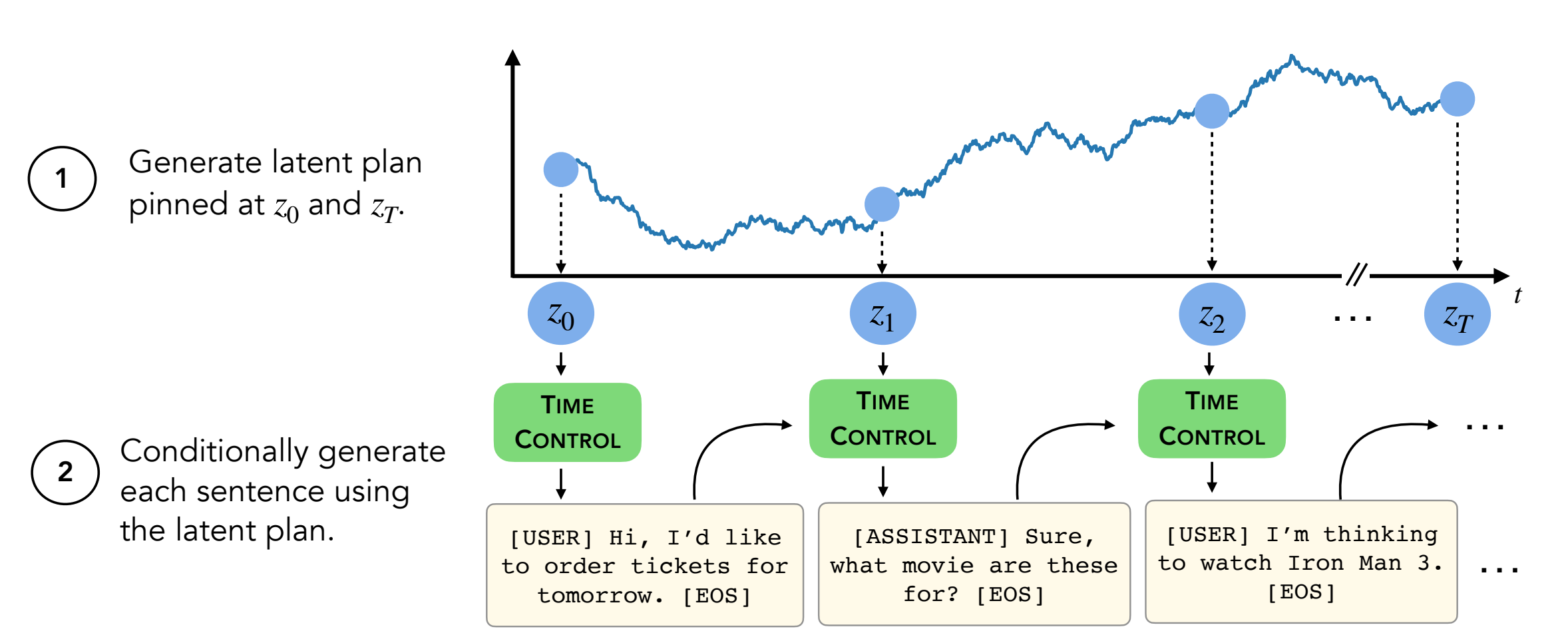
Zum Generieren von Texten müssen Sie sich im Verzeichnis decoder/transformers/examples/pytorch/text-generation/ befinden.
Das Skript zum Generieren von Text und Messung von Mismpatine pro Abschnitt Länge finden Sie in decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh .
Das Skript zum Generieren langer Texte finden Sie in decoder/transformers/examples/pytorch/text-generation/long_generation.sh .
Um alle Metriken zu sammeln, lesen Sie analysis/run_analysis.sh . Sie können alle Bewertungen mit source analysis/run_analysis.sh ausführen.
Denken Sie daran, den Benutzernamen und den Projektnamen des Wandb als das zu ändern, was Sie in den Experimenten Encoder und Decoder aufgelistet haben.


