language_modeling_via_stochastic_processes
1.0.0
[Paper] [Open Review] [Video Panjang]
Iclr oral 2022
Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto

Abstrak: Model bahasa modern dapat menghasilkan teks pendek berkualitas tinggi. Namun, mereka sering berkelok -kelok atau tidak koheren saat menghasilkan teks yang lebih panjang. Masalah-isu ini muncul dari tujuan pemodelan bahasa yang hanya-di-token. Pekerjaan terbaru dalam pembelajaran yang diatur sendiri menunjukkan bahwa model dapat mempelajari representasi laten yang baik melalui pembelajaran kontras, yang dapat efektif untuk tugas diskriminatif. Pekerjaan kami menganalisis penerapan representasi kontras untuk tugas -tugas generatif, seperti pembuatan teks yang panjang. Kami mengusulkan satu pendekatan untuk memanfaatkan representasi konstruktif, yang kami sebut kontrol waktu (TC). TC pertama -tama mempelajari representasi kontras dari domain teks target, kemudian menghasilkan teks dengan decoding dari representasi ini. Dibandingkan dengan metode khusus domain dan menyempurnakan GPT2 di berbagai domain teks, TC berkinerja kompetitif terhadap metode khusus untuk representasi kalimat belajar pada koherensi wacana. Pada pengaturan pembuatan teks yang panjang, TC mempertahankan struktur teks baik dalam hal pemesanan (hingga +15% lebih baik) dan konsistensi panjang teks (hingga +90% lebih baik).
Isi:
setup.shconda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
Repo ini berisi semua kecuali dua dataset (wikihow dan resep NLG) . Instruksi di bawah ini.
Empat dataset lainnya sudah ada dalam repo ini.
Dataset Wikihow perlu diunduh dari tautan ini. Ini adalah file PKL yang harus masuk sebagai path/2/repo/data/wikihow/wiki_how_data.pkl .
Dataset Wikisection yang digunakan dalam makalah ini sudah termasuk.
Itu berasal dari karya sebelumnya ini - khususnya, kami menggunakan artikel Wikipedia Kota Inggris.
Dataset NLG Resep perlu diunduh. Unduh Dataset NLG Resep dan letakkan data di bawah encoder/data/recipe_nlg .
Dataset TM2 yang digunakan dalam makalah ini sudah termasuk. Itu berasal dari dataset pencarian restoran TM2.
Dataset TicketTalk yang digunakan dalam makalah ini sudah termasuk.
Ini dapat ditemukan sebagai dataset TickeTtalk (semua file JSON).
Sebelum menjalankan percobaan, cd encoder/code; source init_env.sh
Dalam encoder/code/scripts/run_ou.py , atur nama variabel ckpt_dir ke direktori pos pemeriksaan Anda.
Script untuk melatih Encoders (TC, VAE, Brownian, Infrice) dapat ditemukan di encoder/code/scripts/train_encoders.sh .
Sebelum menjalankan percobaan, cd encoder/code; source init_env.sh
Dalam encoder/code/scripts/run_discourse.py dan encoder/code/src/systems/discourse_system.py , atur jalur yang benar ke direktori data dan repo Anda.
Skrip untuk menjalankan eksperimen koherensi wacana dapat ditemukan di encoder/code/scripts/discourse.sh .
Untuk melatih decoder, Anda harus berada di decoder/examples/pytorch/language-modeling/ .
Skrip untuk melatih decoder dapat ditemukan di decoder/examples/pytorch/language-modeling/train_encoders.sh . Pastikan untuk mengubah variabel path2repo .
Anda harus mengubah direktori ke direktori data Anda sebagaimana mestinya di run_time_clm.py
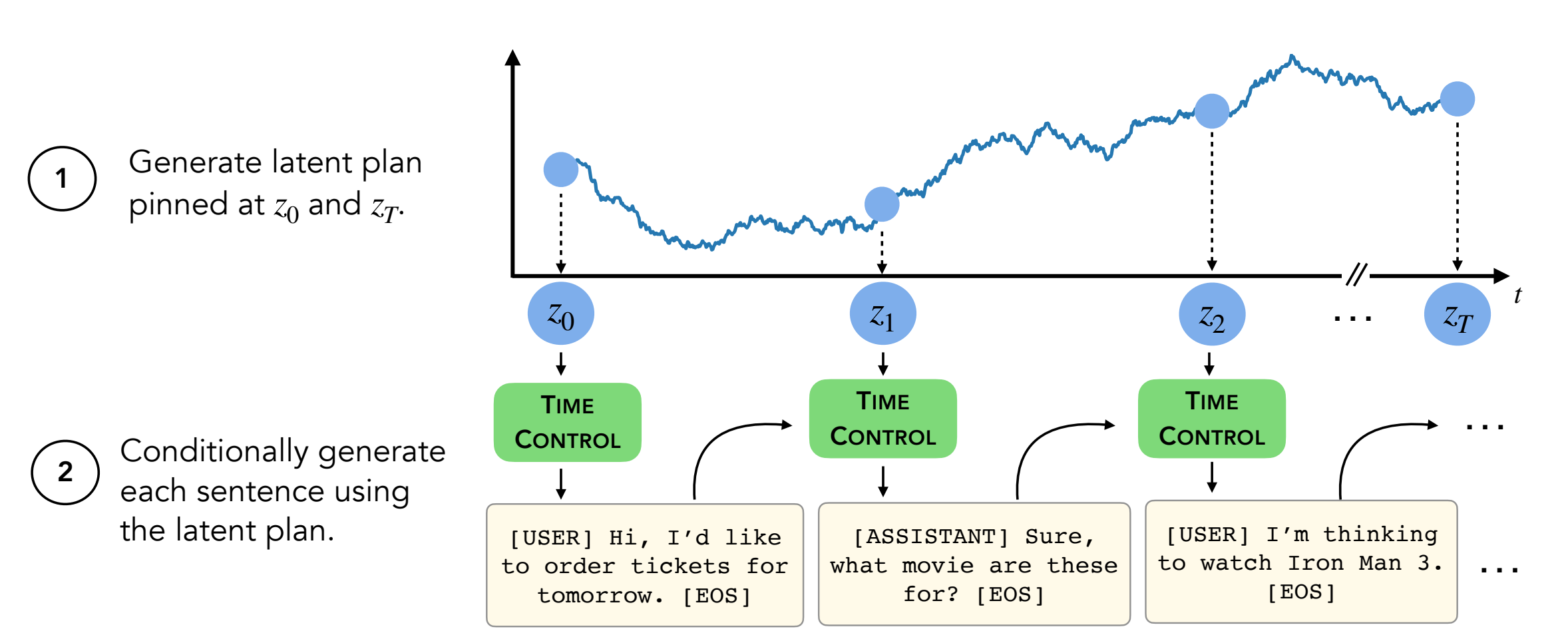
Untuk menghasilkan teks, Anda harus berada di decoder/transformers/examples/pytorch/text-generation/ .
Skrip untuk menghasilkan teks dan pengukuran ketidaksesuaian per-bagian dapat ditemukan di decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh .
Script untuk menghasilkan teks panjang dapat ditemukan di decoder/transformers/examples/pytorch/text-generation/long_generation.sh .
Untuk mengumpulkan semua metrik, lihat analysis/run_analysis.sh . Anda dapat menjalankan semua evaluasi dengan source analysis/run_analysis.sh .
Ingatlah untuk mengubah nama pengguna Wandb dan nama proyek sebagai apa yang Anda daftarkan dalam eksperimen encoder dan decoder.


