language_modeling_via_stochastic_processes
1.0.0
[Document] [Revue ouverte] [Vidéo longue]
ICLR oral 2022
Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto

Résumé: Les modèles de langue moderne peuvent générer des textes courts de haute qualité. Cependant, ils serpentent souvent ou sont incohérents lors de la génération de textes plus longs. Ces problèmes découlent de l'objectif de modélisation du langage uniquement uniquement token. Des travaux récents dans l'apprentissage auto-levé suggèrent que les modèles peuvent apprendre de bonnes représentations latentes via un apprentissage contrastif, qui peut être efficace pour les tâches discriminantes. Notre travail analyse l'application de représentations contrastives pour les tâches génératives, comme la longue génération de texte. Nous proposons une approche pour tirer parti des représentations contrastives, que nous appelons le contrôle du temps (TC). TC apprend d'abord une représentation contrastive du domaine de texte cible, puis génère du texte en décodant ces représentations. Par rapport aux méthodes spécifiques au domaine et au réglage fin GPT2 dans une variété de domaines de texte, TC fonctionne de manière compétitive à des méthodes spécifiques pour l'apprentissage des représentations de phrases sur la cohérence du discours. Sur les paramètres longs de la génération de texte, TC préserve la structure du texte à la fois en termes de commande (jusqu'à + 15% mieux) et de cohérence de longueur de texte (jusqu'à + 90% de mieux).
Contenu:
setup.shconda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
Ce dépôt contient tous les ensembles de données sauf deux (WikiHow et Recipe NLG) . Les instructions sont ci-dessous.
Les quatre autres ensembles de données sont déjà dans ce dépôt.
L'ensemble de données WikiHow doit être téléchargé à partir de ce lien. Il s'agit d'un fichier PKL qui devrait passer en tant que path/2/repo/data/wikihow/wiki_how_data.pkl .
L'ensemble de données Wikisection utilisé dans ce document est déjà inclus.
Il est venu de ce travail antérieur - en particulier, nous avons utilisé les articles de Wikipedia de la ville anglaise.
L'ensemble de données NLG recette doit être téléchargé. Téléchargez l'ensemble de données NLG Recette et placez les données sous encoder/data/recipe_nlg .
L'ensemble de données TM2 utilisé dans cet article est déjà inclus. Il provient de l'ensemble de données de recherche de restaurants TM2.
L'ensemble de données Tickettalk utilisé dans cet article est déjà inclus.
Il peut être trouvé comme l'ensemble de données Tickettalk (tous les fichiers JSON).
Avant d'exécuter des expériences, cd encoder/code; source init_env.sh
Dans encoder/code/scripts/run_ou.py , définissez le nom de la variable ckpt_dir dans votre répertoire de point de contrôle.
Le script pour la formation des encodeurs (TC, VAE, Brownien, Infonce) peut être trouvé dans encoder/code/scripts/train_encoders.sh .
Avant d'exécuter des expériences, cd encoder/code; source init_env.sh
Dans encoder/code/scripts/run_discourse.py et encoder/code/src/systems/discourse_system.py , définissez les chemins corrects sur votre répertoire de données et votre repo.
Le script pour exécuter les expériences de cohérence du discours peut être trouvé dans encoder/code/scripts/discourse.sh .
Pour la formation du décodeur, vous devrez être dans decoder/examples/pytorch/language-modeling/ .
Le script pour la formation du décodeur peut être trouvé sur decoder/examples/pytorch/language-modeling/train_encoders.sh . Assurez-vous de modifier la variable path2repo .
Vous devrez modifier les répertoires en votre répertoire de données, le cas échéant, dans run_time_clm.py
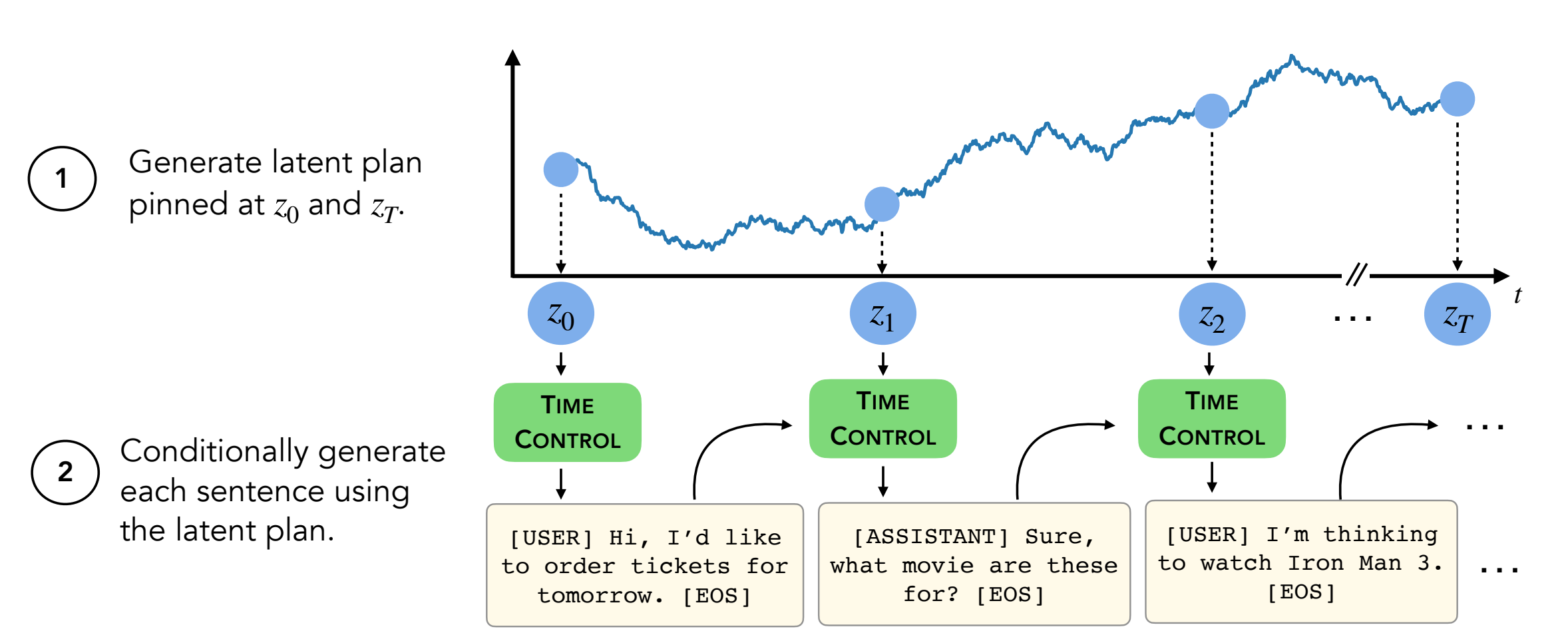
Pour générer des textes, vous devrez être dans decoder/transformers/examples/pytorch/text-generation/ .
Le script pour générer du texte et mesurer les décalages de longueur par coupe se trouvent à decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh .
Le script pour générer de longs textes peut être trouvé sur decoder/transformers/examples/pytorch/text-generation/long_generation.sh .
Pour collecter toutes les mesures, consultez analysis/run_analysis.sh . Vous pouvez exécuter toutes les évaluations avec source analysis/run_analysis.sh .
N'oubliez pas de modifier le nom d'utilisateur Wandb et le nom du projet comme ce que vous avez répertorié dans les expériences de l'encodeur et du décodeur.


