language_modeling_via_stochastic_processes
1.0.0
[ورقة] [مراجعة مفتوحة] [فيديو طويل]
ICLR عن طريق الفم 2022
روز إي وانغ ، إيسين دورموس ، نوح جودمان ، تاتسونوري هاشموتو

الخلاصة: يمكن أن تولد نماذج اللغة الحديثة نصوصًا قصيرة عالية الجودة. ومع ذلك ، فإنها في كثير من الأحيان تعرج أو تكون غير متماسكة عند توليد نصوص أطول. تنشأ هذه المشكلات من هدف نمذجة اللغة فقط. يشير العمل الأخير في التعلم الخاضع للإشراف ذاتيًا إلى أن النماذج يمكن أن تتعلم تمثيلات كامنة جيدة من خلال التعلم التباين ، والتي يمكن أن تكون فعالة للمهام التمييزية. يحلل عملنا تطبيق تمثيلات متناقضة للمهام التوليدية ، مثل توليد النص الطويل. نقترح نهجًا واحدًا للاستفادة من التمثيلات المتنوعة ، والتي نسميها التحكم في الوقت (TC). يتعلم TC أولاً تمثيلًا متناقضًا لمجال النص المستهدف ، ثم ينشئ النص عن طريق فك التشفير من هذه العروض. بالمقارنة مع الأساليب الخاصة بالمجال وضبط GPT2 عبر مجموعة متنوعة من المجالات النصية ، فإن TC يؤدي تنافسيًا إلى الأساليب الخاصة بتمثيلات الجملة التعليمية على تماسك الخطاب. في إعدادات توليد النص الطويل ، تحافظ TC على بنية النص من حيث الطلب (تصل إلى +15 ٪ أفضل) واتساق طول النص (ما يصل إلى +90 ٪ أفضل).
محتويات:
setup.shconda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
يحتوي هذا الريبو على جميع مجموعات بيانات (Wikihow و NLG) . التعليمات أدناه.
مجموعات البيانات الأربعة الأخرى موجودة بالفعل في هذا الريبو.
يجب تنزيل مجموعة بيانات WikiHow من هذا الرابط. إنه ملف PKL الذي يجب أن يخضع path/2/repo/data/wikihow/wiki_how_data.pkl .
تم تضمين مجموعة بيانات Wikisection المستخدمة في هذه الورقة بالفعل.
لقد جاء من هذا العمل السابق - على وجه التحديد ، استخدمنا مقالات Wikipedia للمدينة الإنجليزية.
يجب تنزيل مجموعة بيانات الوصفة NLG. قم بتنزيل مجموعة بيانات الوصفة NLG ووضع البيانات ضمن encoder/data/recipe_nlg .
تم تضمين مجموعة بيانات TM2 المستخدمة في هذه الورقة بالفعل. جاء من مجموعة بيانات البحث عن مطعم TM2.
تم تضمين مجموعة بيانات TicketTalk المستخدمة في هذه الورقة بالفعل.
يمكن العثور عليها كمجموعة بيانات TicketTalk (جميع ملفات JSON).
قبل إجراء التجارب ، cd encoder/code; source init_env.sh
في encoder/code/scripts/run_ou.py ، اضبط اسم المتغير ckpt_dir على دليل نقطة التفتيش.
يمكن العثور على البرنامج النصي للتدريب على الترميز (TC ، VAE ، Brownian ، Infonce) في encoder/code/scripts/train_encoders.sh .
قبل إجراء التجارب ، cd encoder/code; source init_env.sh
في encoder/code/scripts/run_discourse.py و encoder/code/src/systems/discourse_system.py ، قم بتعيين المسارات الصحيحة على دليل البيانات الخاص بك و repo.
يمكن العثور على البرنامج النصي لتشغيل تجارب تماسك الخطاب في encoder/code/scripts/discourse.sh .
لتدريب وحدة فك الترميز ، ستحتاج إلى أن تكون في وحدة decoder/examples/pytorch/language-modeling/ .
يمكن العثور على البرنامج النصي لتدريب Decoder في decoder/examples/pytorch/language-modeling/train_encoders.sh . تأكد من تغيير متغير path2repo .
ستحتاج إلى تغيير الدلائل إلى دليل البيانات الخاص بك حسب الاقتضاء في run_time_clm.py
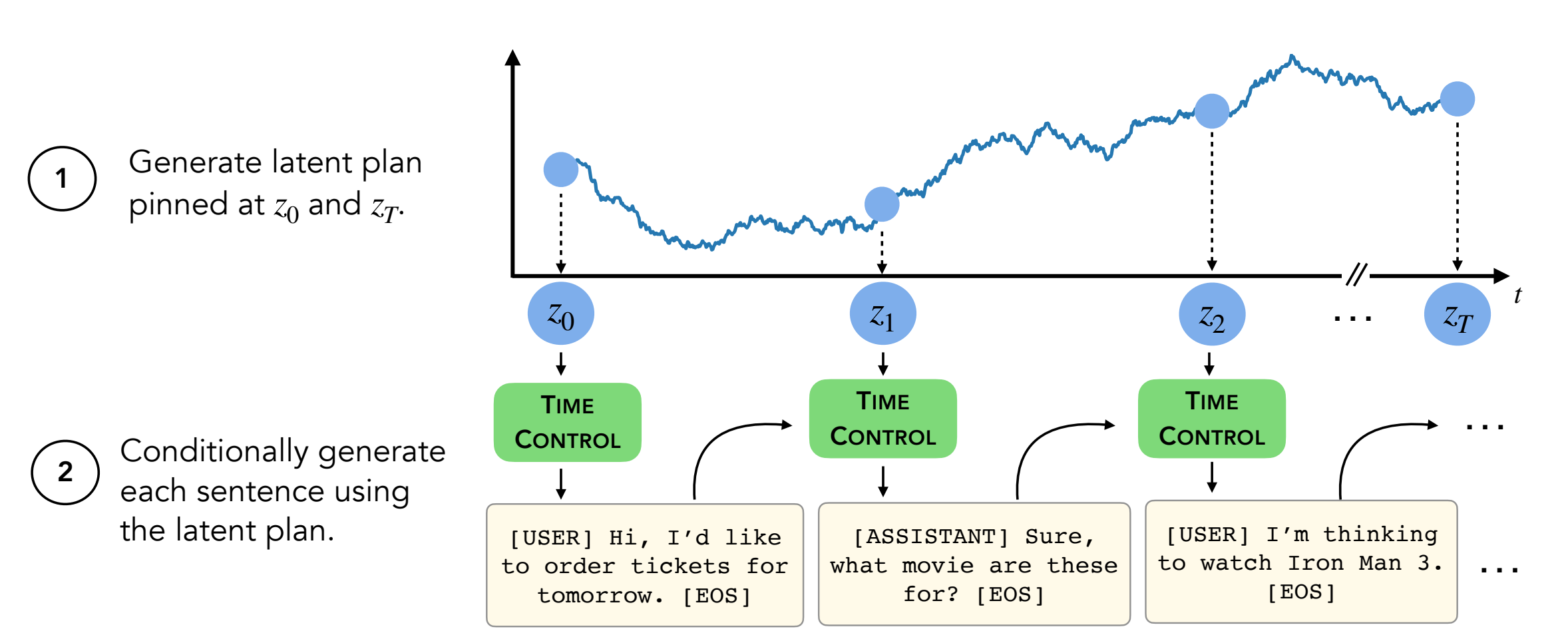
لتوليد النصوص ، ستحتاج إلى أن تكون في وحدة decoder/transformers/examples/pytorch/text-generation/ .
يمكن العثور على البرنامج النصي لتوليد النص وقياس عدم تطابق طول القسم في decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh .
يمكن العثور على البرنامج النصي لإنشاء نصوص طويلة في decoder/transformers/examples/pytorch/text-generation/long_generation.sh .
لجمع جميع المقاييس ، تحقق من analysis/run_analysis.sh . يمكنك تشغيل جميع التقييمات مع source analysis/run_analysis.sh .
تذكر تغيير اسم مستخدم WANDB واسم المشروع على أنه ما أدرجته في تجارب التشفير وفك الترميز.


