language_modeling_via_stochastic_processes
1.0.0
[Paper] [Aberto da revisão] [Vídeo longo]
ICLR ORAL 2022
Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto

Resumo: Os modelos de idiomas modernos podem gerar textos curtos de alta qualidade. No entanto, eles costumam serpenteados ou são incoerentes ao gerar textos mais longos. Esses problemas surgem do objetivo de modelagem de idiomas apenas para token-token. Trabalhos recentes em aprendizado auto-supervisionado sugerem que os modelos podem aprender boas representações latentes por meio de aprendizado contrastivo, o que pode ser eficaz para tarefas discriminativas. Nosso trabalho analisa a aplicação de representações contrastantes para tarefas generativas, como geração de texto longo. Propomos uma abordagem para alavancar representações constrrastivas, que chamamos de controle de tempo (TC). A TC primeiro aprende uma representação contrastiva do domínio de texto de destino e gera texto decodificando a partir dessas representações. Comparado aos métodos específicos de domínio e ao GPT2 de ajuste fino em vários domínios de texto, o TC tem um desempenho competitivo a métodos específicos para representações de sentenças de aprendizado sobre a coerência do discurso. Em configurações de geração de texto longo, o TC preserva a estrutura de texto, tanto em termos de pedidos (até +15% melhor) quanto a consistência do comprimento do texto (até +90% melhor).
Conteúdo:
setup.shconda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
Este repo contém todos os conjuntos de dados, exceto dois (WikiHow e Recipe NLG) . As instruções estão abaixo.
Os outros quatro conjuntos de dados já estão neste repositório.
O conjunto de dados WikiHow precisa ser baixado a partir deste link. É um arquivo PKL que deve ser submetido a path/2/repo/data/wikihow/wiki_how_data.pkl .
O conjunto de dados da Wikisection usado neste artigo já está incluído.
Ele veio desse trabalho anterior - especificamente, usamos os artigos da Wikipedia da cidade inglesa.
O conjunto de dados da receita NLG precisa ser baixado. Faça o download do conjunto de dados NLG da receita e coloque os dados em encoder/data/recipe_nlg .
O conjunto de dados TM2 usado neste artigo já está incluído. Ele veio do conjunto de dados de pesquisa de restaurantes TM2.
O conjunto de dados Ticketalk usado neste artigo já está incluído.
Pode ser encontrado como o conjunto de dados da ticketalk (todos os arquivos JSON).
Antes de executar experimentos, cd encoder/code; source init_env.sh
No encoder/code/scripts/run_ou.py , defina o nome da variável ckpt_dir no seu diretório de ponto de verificação.
O script para treinar os codificadores (TC, VAE, Brownian, Infonce) pode ser encontrado no encoder/code/scripts/train_encoders.sh .
Antes de executar experimentos, cd encoder/code; source init_env.sh
No encoder/code/scripts/run_discourse.py e encoder/code/src/systems/discourse_system.py , defina os caminhos corretos para o seu diretório de dados e repo.
O script para executar os experimentos de coerência do discurso pode ser encontrado em encoder/code/scripts/discourse.sh .
Para treinar o decodificador, você precisará estar no decoder/examples/pytorch/language-modeling/ .
O script para treinamento que o decodificador pode ser encontrado em decoder/examples/pytorch/language-modeling/train_encoders.sh . Certifique -se de alterar a variável path2repo .
Você precisará alterar os diretórios para o seu diretório de dados, conforme apropriado em run_time_clm.py
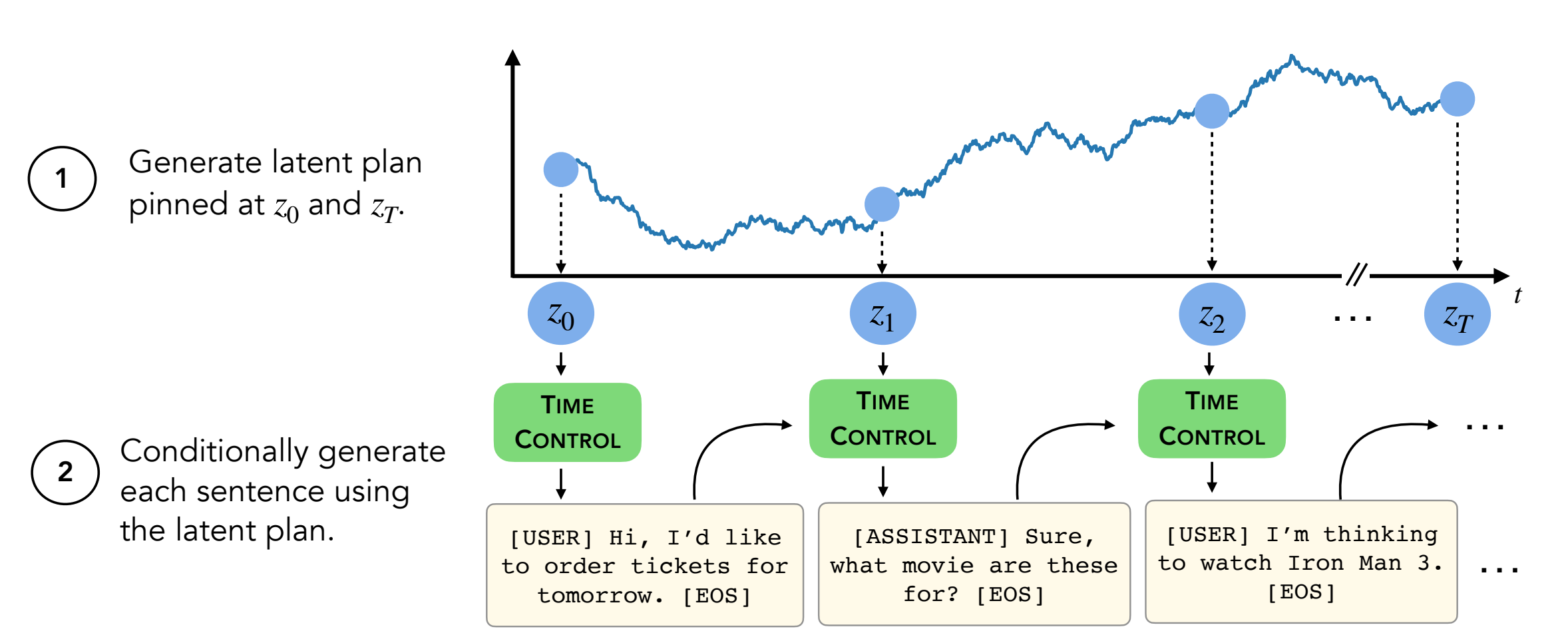
Para gerar textos, você precisará estar no decoder/transformers/examples/pytorch/text-generation/ .
O script para gerar texto e medir as incompatibilidades de comprimento da seção pode ser encontrado em decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh .
O script para gerar textos longos pode ser encontrado em decoder/transformers/examples/pytorch/text-generation/long_generation.sh .
Para coletar todas as métricas, consulte analysis/run_analysis.sh . Você pode executar todas as avaliações com source analysis/run_analysis.sh .
Lembre -se de alterar o nome de usuário do Wandb e o nome do projeto como o que você listou nos experimentos do codificador e decodificador.


