language_modeling_via_stochastic_processes
1.0.0
[紙] [オープンレビュー] [ロングビデオ]
ICLRオーラル2022
ローズ・E・王、エシン・ドゥルムス、ノア・グッドマン、タツノリ・ハシモト

要約:現代言語モデルは、高品質の短いテキストを生成できます。ただし、長いテキストを生成すると、蛇行したり、一貫性がありません。これらの問題は、次のトークンのみの言語モデリングの目標から生じます。自己学習学習における最近の研究は、モデルが対照学習を介して優れた潜在表現を学ぶことができることを示唆しています。これは、差別的なタスクに効果的である可能性があります。私たちの仕事は、長いテキスト生成などの生成タスクの対照表現の適用を分析します。制御(TC)と呼ばれる制約表現を活用するための1つのアプローチを提案します。 TCはまず、ターゲットテキストドメインの対照的な表現を学習し、次にこれらの表現からデコードすることによりテキストを生成します。さまざまなテキストドメインにわたってドメイン固有の方法や微調整GPT2と比較して、TCは、談話の一貫性に関する文の表現を学習するために固有の方法に競争力のあるパフォーマンスを発揮します。長いテキスト生成設定では、TCは、注文(最大 +15%より良い)とテキストの長さの一貫性(最大 +90%良い)の両方の観点からテキスト構造を保持します。
コンテンツ:
setup.shのコマンドに従ってくださいconda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
このレポは、2つのデータセットを除くすべてのデータ(WikiHowおよびRecipe NLG)が含まれています。指示は以下にあります。
他の4つのデータセットはすでにこのレポにあります。
このリンクからWikiHowデータセットをダウンロードする必要があります。これはpath/2/repo/data/wikihow/wiki_how_data.pklの下にある必要があるPKLファイルです。
このペーパーで使用されているウィキセクションデータセットはすでに含まれています。
これは、この以前の作品から来ました。具体的には、英国の都市ウィキペディアの記事を使用しました。
レシピNLGデータセットをダウンロードする必要があります。レシピNLGデータセットをダウンロードし、データをencoder/data/recipe_nlgの下に配置します。
このペーパーで使用されているTM2データセットはすでに含まれています。 TM2レストラン検索データセットから来ました。
このペーパーで使用されているチケットデータセットはすでに含まれています。
チケットデータセット(すべてのJSONファイル)として見つけることができます。
実験を実行する前に、 cd encoder/code; source init_env.sh
encoder/code/scripts/run_ou.pyで、変数名ckpt_dirチェックポイントディレクトリに設定します。
エンコーダ(TC、VAE、Brownian、Infonce)をトレーニングするためのスクリプトはencoder/code/scripts/train_encoders.shにあります。
実験を実行する前に、 cd encoder/code; source init_env.sh
encoder/code/scripts/run_discourse.py and encoder/code/src/systems/discourse_system.pyで、正しいパスをデータディレクトリとリポジトリに設定します。
談話コヒーレンス実験を実行するためのスクリプトはencoder/code/scripts/discourse.shにあります。
デコーダーをトレーニングするには、ディレクトリdecoder/examples/pytorch/language-modeling/にある必要があります。
デコーダーをトレーニングするためのスクリプトはdecoder/examples/pytorch/language-modeling/train_encoders.shにあります。 path2repo変数を必ず変更してください。
run_time_clm.pyで必要に応じて、ディレクトリをデータディレクトリに変更する必要があります
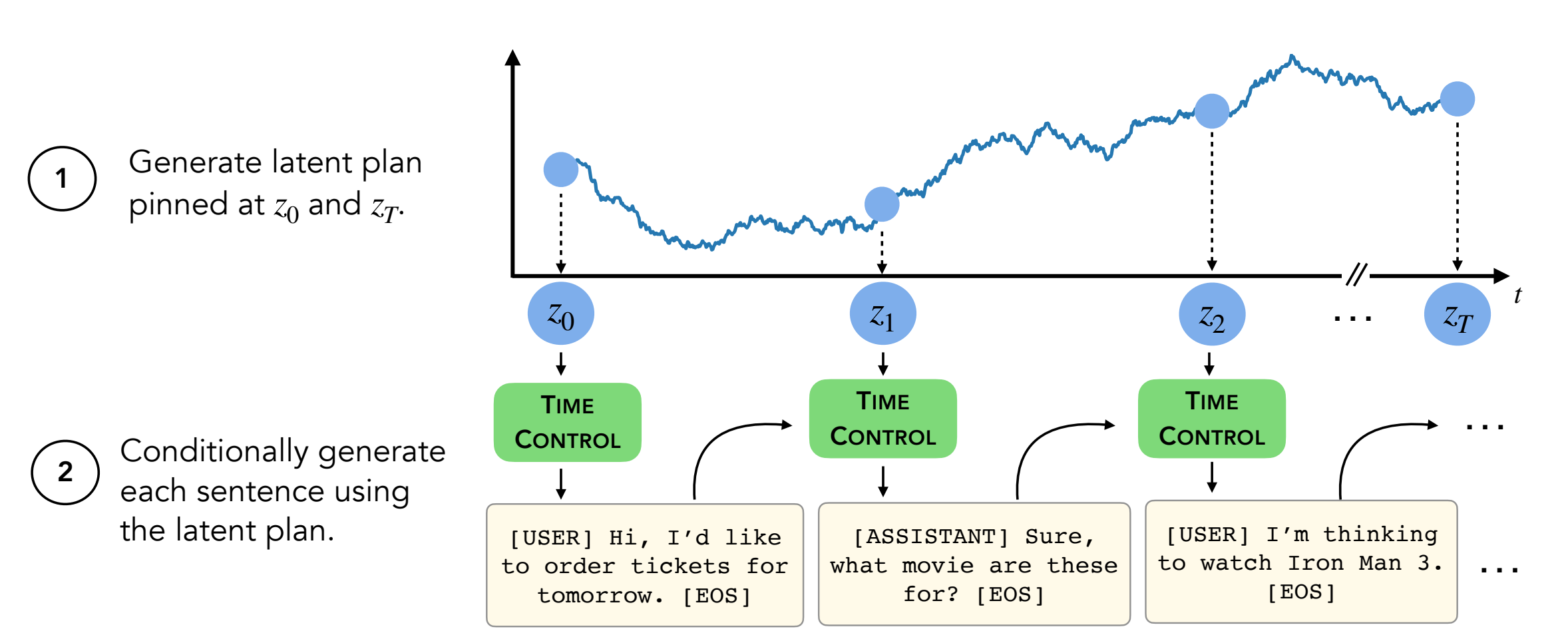
テキストを生成するには、ディレクトリdecoder/transformers/examples/pytorch/text-generation/にある必要があります。
テキストを生成し、セクションごとの長さの不一致を測定するためのスクリプトはdecoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.shにあります。
長いテキストを生成するためのスクリプトはdecoder/transformers/examples/pytorch/text-generation/long_generation.shにあります。
すべてのメトリックを収集するには、 analysis/run_analysis.shをご覧ください。 source analysis/run_analysis.shですべての評価を実行できます。
WandBユーザー名とプロジェクト名をエンコーダーとデコーダーの実験にリストしたものとして変更することを忘れないでください。


