language_modeling_via_stochastic_processes
1.0.0
[종이] [오픈 리뷰] [긴 비디오]
ICLR 경구 2022
Rose E Wang, Esin Durmus, Noah Goodman, Tatsunori Hashimoto

초록 : 현대 언어 모델은 고품질의 짧은 텍스트를 생성 할 수 있습니다. 그러나 그들은 종종 더 긴 텍스트를 생성 할 때 구매하거나 일관성이 없습니다. 이러한 문제는 차세대 언어 모델링 목표에서 발생합니다. 자체 감독 학습의 최근 연구는 모델이 대조적 인 학습을 통해 좋은 잠재적 표현을 배울 수 있으며, 이는 차별적 인 작업에 효과적 일 수 있음을 시사합니다. 우리의 작업은 긴 텍스트 생성과 같은 생성 작업에 대한 대조적 표현의 적용을 분석합니다. 우리는 시간 제어 (TC)라고하는 구속적 표현을 활용하기위한 하나의 접근법을 제안합니다. TC는 먼저 대상 텍스트 도메인의 대조적 인 표현을 배우고 이러한 표현에서 디코딩하여 텍스트를 생성합니다. 다양한 텍스트 도메인에 걸쳐 도메인-특이 적 방법 및 미세 조정 GPT2와 비교하여 TC는 담론 일관성에 대한 학습 문장 표현에 맞는 방법에 대해 경쟁적으로 수행합니다. 긴 텍스트 생성 설정에서 TC는 순서 (최대 15% 더 우수)와 텍스트 길이 일관성 (최대 +90% 더 나은) 측면에서 텍스트 구조를 보존합니다.
내용물:
setup.sh 의 명령을 따르십시오conda activate language_modeling_via_stochastic_processes cd decoder # enter the decoder repo
pip install -e . # Installing transformers locally; I modified their GPT2 module to take in our learned embeddings for decoding.
이 repo에는 두 개의 데이터 세트를 제외한 모든 데이터 세트 (Wikihow 및 레시피 NLG)가 포함됩니다 . 지침은 다음과 같습니다.
다른 4 개의 데이터 세트는 이미이 리포지어에 있습니다.
Wikihow 데이터 세트는이 링크에서 다운로드해야합니다. path/2/repo/data/wikihow/wiki_how_data.pkl 로 이동 해야하는 PKL 파일입니다.
이 백서에 사용 된 Wikisection 데이터 세트는 이미 포함되어 있습니다.
이 사전 작업에서 나왔습니다. 구체적으로 우리는 English City Wikipedia 기사를 사용했습니다.
레시피 NLG 데이터 세트를 다운로드해야합니다. 레시피 NLG 데이터 세트를 다운로드하고 데이터를 encoder/data/recipe_nlg 아래에 넣으십시오.
이 백서에 사용 된 TM2 데이터 세트는 이미 포함되어 있습니다. TM2 레스토랑 검색 데이터 세트에서 나왔습니다.
이 백서에 사용 된 Tickettalk 데이터 세트는 이미 포함되어 있습니다.
Tickettalk 데이터 세트 (모든 JSON 파일)로 찾을 수 있습니다.
실험을 실행하기 전에 cd encoder/code; source init_env.sh
encoder/code/scripts/run_ou.py 에서 변수 이름 ckpt_dir CheckPoint 디렉토리로 설정하십시오.
인코더를 훈련하기위한 스크립트 (TC, VAE, Brownian, Infonce)는 encoder/code/scripts/train_encoders.sh 에서 찾을 수 있습니다.
실험을 실행하기 전에 cd encoder/code; source init_env.sh
encoder/code/scripts/run_discourse.py 및 encoder/code/src/systems/discourse_system.py 에서 데이터 디렉토리 및 Repo로 올바른 경로를 설정하십시오.
담론 일관성 실험을위한 스크립트는 encoder/code/scripts/discourse.sh 에서 찾을 수 있습니다.
디코더를 훈련하려면 디렉토리 decoder/examples/pytorch/language-modeling/ 에 있어야합니다.
디코더를 훈련하기위한 스크립트는 decoder/examples/pytorch/language-modeling/train_encoders.sh 에서 찾을 수 있습니다. path2repo 변수를 변경하십시오.
run_time_clm.py 에서 적절하게 디렉토리를 데이터 디렉토리로 변경해야합니다.
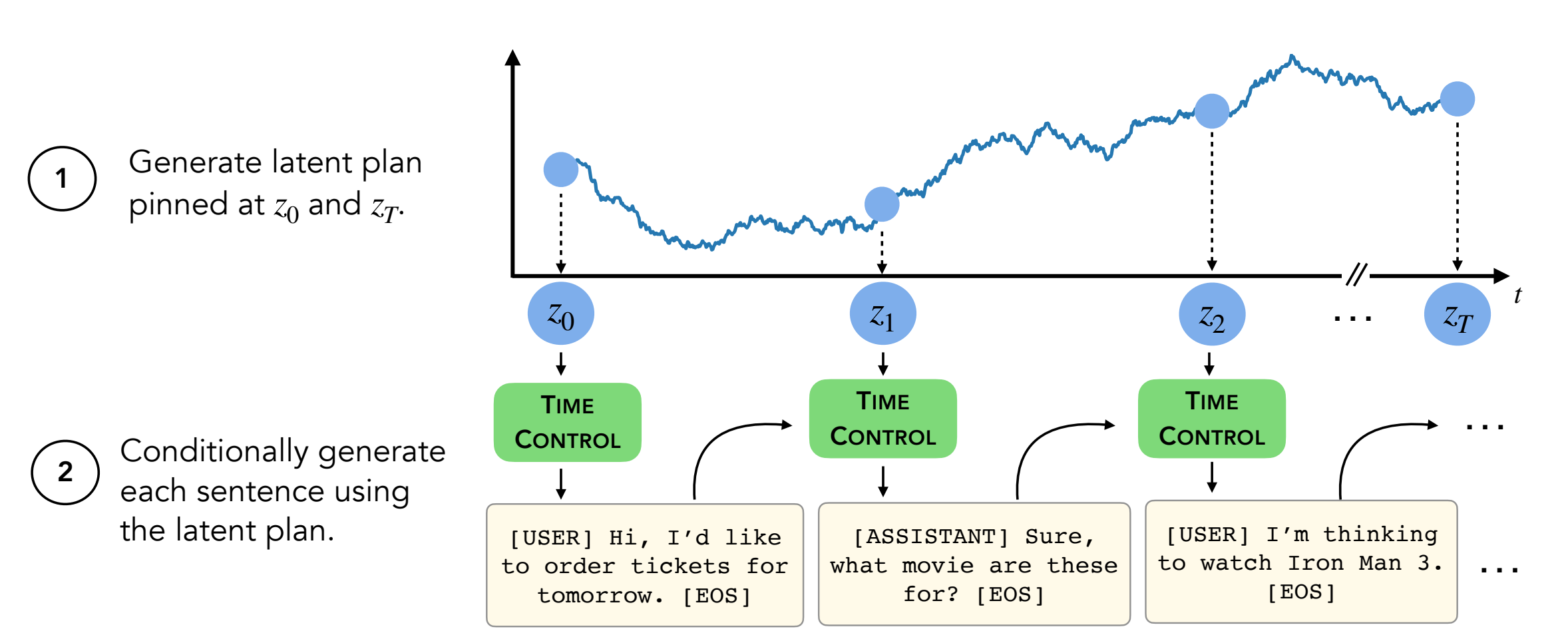
텍스트를 생성하려면 디렉토리 decoder/transformers/examples/pytorch/text-generation/ 에 있어야합니다.
텍스트를 생성하고 섹션 당 길이 당 측정을위한 스크립트는 decoder/transformers/examples/pytorch/text-generation/toy_wikisection_generation.sh 에서 찾을 수 있습니다.
긴 텍스트를 생성하기위한 스크립트는 decoder/transformers/examples/pytorch/text-generation/long_generation.sh 에서 찾을 수 있습니다.
모든 메트릭을 수집하려면 analysis/run_analysis.sh 확인하십시오. source analysis/run_analysis.sh 로 모든 평가를 실행할 수 있습니다.
인코더 및 디코더 실험에 나열된 것으로 Wandb 사용자 이름과 프로젝트 이름을 변경해야합니다.


