LM LSTM CRF
implemented most features
檢查我們的新NER工具包
該項目提供了高性能的角色感知序列標籤工具,包括培訓,評估和預測。
有關LM-LSTM-CRF的詳細信息可以在此處訪問,並且實現基於Pytorch庫。
重要的是:在原始實現中,在bioes_to_span函數上發現了一個嚴重的錯誤,請參閱“基準”部分中報告的數字作為準確的性能。
這些文檔將在這裡可用。
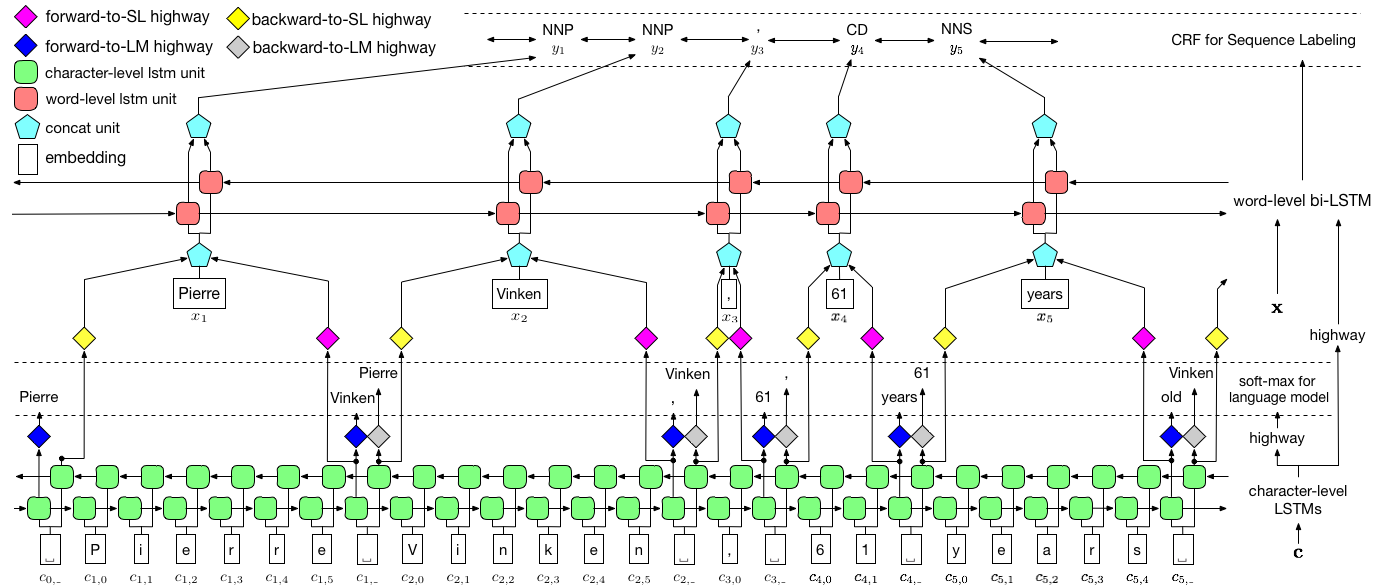
如上所述,我們使用條件隨機字段(CRF)來捕獲標籤依賴性,並採用層次LSTM來利用char級別和文字級輸入。 char級結構由語言模型進一步指導,而預訓練的單詞嵌入在文字級別中利用。語言模型和序列標籤模型同時訓練,並且都在文字級別進行預測。高速公路網絡用於將Char-Level LSTM的輸出轉換為不同的語義空間,從而介導這兩個任務並允許語言模型賦予序列標記。
對於培訓,強烈建議使用GPU以換取速度。 CPU得到了支持,但培訓可能非常慢。
該代碼基於Pytorch,現在支持Pytorch 0.4 。您可以在此處找到安裝說明。
該代碼以Python 3.6編寫。它的依賴項總結在文件requirements.txt中。您可以這樣安裝這些依賴項:
pip3 install -r requirements.txt
我們主要關注Conll 2003 NER數據集,該代碼將其原始格式作為輸入。但是,由於許可問題,我們僅限於分發此數據集。您應該能夠在這裡得到它。您可能還想在線搜索(例如,github),可能會意外釋放它。
我們假設語料庫的格式與Conll 2003 NER數據集一樣。更具體地說,空線被用作句子之間的分離器,文檔之間的分離器是以下特殊行。
-DOCSTART- -X- -X- -X- O
其他行包含單詞,標籤和其他字段。單詞必須是第一個字段,標籤是最後一個字段,並且這些字段被空間隔開。例如,PTB POS標記語料庫的WSJ部分中的前幾行應該像以下片段。
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
在這裡,我們為兩個模型提供了實現,一個是LM-LSTM-CRF ,另一個是其變體LSTM-CRF ,它僅包含單詞級結構和CRF。 train_wc.py和eval_wc.py是LM-LSTM-CRF的腳本,而train_w.py和eval_w.py是LSTM-CRF的腳本。這些腳本的用法可以通過參數-h ,即
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
NER和POS標籤的默認運行命令以及NP塊是:
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
對於其他數據集或任務,您可能想嘗試不同的停止參數,尤其是對於較小的數據集,您可能需要將least_iters設置為較大的值;對於某些任務,如果損失速度的速度太慢,則可能需要增加lr 。
在這裡,我們將LM-LSTM-CRF與Conll 2000塊數據集,Conll 2003 NER數據集和PTB POS標籤數據集的WSJ部分進行比較。所有實驗均在GTX 1080 GPU上進行。
在原始實現中,在bioes_to_span函數上發現了一個嚴重的錯誤,請將以下數字稱為準確的性能。
當模型僅在PTB POS標記數據集的WSJ部分訓練時,結果將如下匯總。
| 模型 | 最大(ACC) | 平均(ACC) | 性病(ACC) | 時間(h) |
|---|---|---|---|---|
| lm-lstm-crf | 91.35 | 91.24 | 0.12 | 4 |
| - 高速公路 | 90.87 | 90.79 | 0.07 | 4 |
| - 共同訓練 | 91.23 | 90.95 | 0.34 | 2 |
當模型僅在PTB POS標記數據集的WSJ部分訓練時,結果將如下匯總。
| 模型 | 最大(ACC) | 平均(ACC) | 性病(ACC) | 報導(ACC) | 時間(h) |
|---|---|---|---|---|---|
| Lample等。 2016 | 97.51 | 97.35 | 0.09 | N/A。 | 37 |
| Ma等。 2016 | 97.46 | 97.42 | 0.04 | 97.55 | 21 |
| lm-lstm-crf | 97.59 | 97.53 | 0.03 | 16 |
我們在這三個任務上發布了預訓練的模型。可以通過以下鏈接下載檢查點文件。請注意,NER模型和塊模型(即將推出)都經過培訓集和開發集的培訓:
| WSJ-PTB POS標籤 | conll03 ner |
|---|---|
| args | args |
| 模型 | 模型 |
另外,還提供了eval_wc.py來加載和運行這些檢查點。可以通過命令python eval_wc.py -h訪問其用法,下面提供了一個運行命令示例:
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
要註釋的原始文本,向未註銷的文本提供了seq_wc.py 。可以通過命令python seq_wc.py -h訪問其用法,下面提供了一個運行命令示例:
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
輸入格式類似於conll,但是每行只包含一個字段,令牌。例如,輸入文件可能是:
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
相應的輸出為:
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


