LM LSTM CRF
implemented most features
新しいNERツールキットを確認してください
このプロジェクトは、トレーニング、評価、予測など、高性能のキャラクター認識シーケンスラベル付けツールを提供します。
LM-LSTM-CRFの詳細はこちらからアクセスでき、実装はPytorchライブラリに基づいています。
重要:元の実装でbioes_to_span関数に深刻なバグが見つかりました。ベンチマークセクションで報告された数値を正確なパフォーマンスとして参照してください。
ドキュメントはこちらから入手できます。
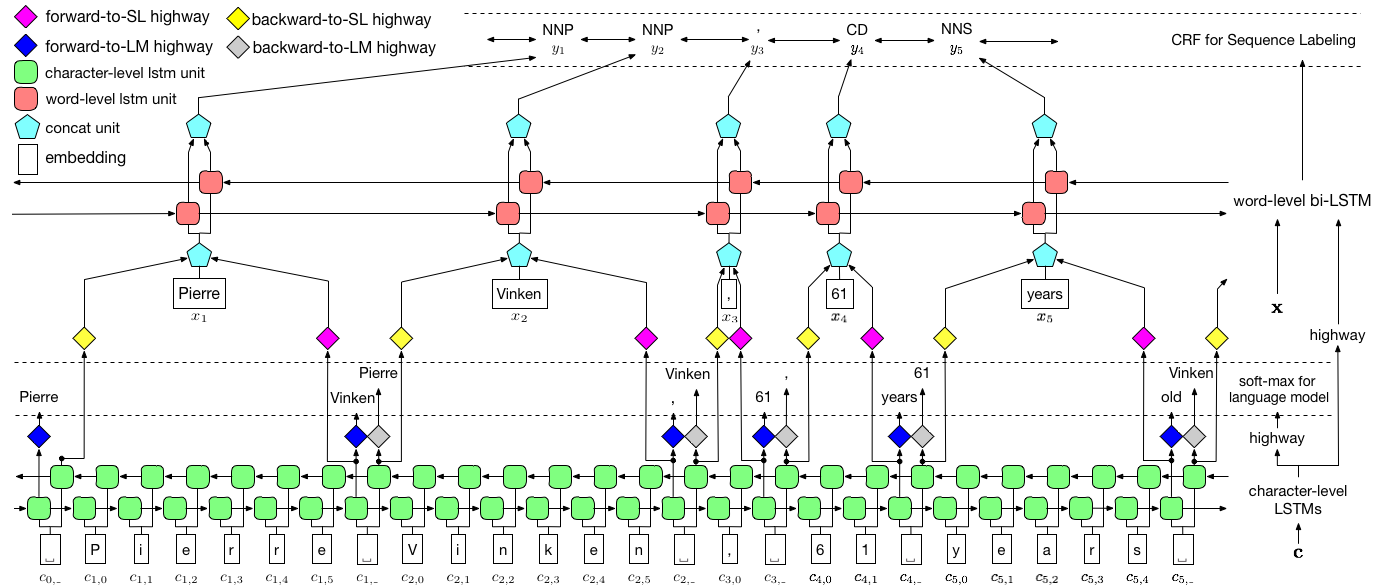
上記で視覚化されたように、条件付きランダムフィールド(CRF)を使用してラベルの依存関係をキャプチャし、階層LSTMを採用して、char-levelと単語レベルの両方の入力を活用します。 char-level構造は言語モデルによってさらに導かれ、事前に訓練された単語の埋め込みは単語レベルで活用されます。言語モデルとシーケンス標識モデルは同時にトレーニングされ、両方とも単語レベルで予測を行います。高速道路ネットワークは、char-level LSTMの出力を異なるセマンティックスペースに変換するために使用され、したがってこれら2つのタスクを媒介し、言語モデルにシーケンスラベル付けを強化することができます。
トレーニングには、速度にGPUを強くお勧めします。 CPUはサポートされていますが、トレーニングは非常に遅い場合があります。
このコードはPytorchに基づいており、 Pytorch 0.4を現在サポートしています。ここでインストール手順を見つけることができます。
コードはPython 3.6で記述されています。その依存関係は、ファイルrequirements.txtにまとめられています。txt。次のようなこれらの依存関係をインストールできます。
pip3 install -r requirements.txt
主にConll 2003 NERデータセットに焦点を当てており、コードは元の形式を入力として取得します。ただし、ライセンスの問題により、このデータセットの配布が制限されています。ここで手に入れることができるはずです。また、オンラインで検索することもできます(たとえば、github)、誰かが誤ってそれをリリースするかもしれません。
コーパスは、Conll 2003 NERデータセットと同じようにフォーマットされていると仮定します。より具体的には、空の線は文の間の分離器として使用され、ドキュメント間の分離器は以下の特別な行です。
-DOCSTART- -X- -X- -X- O
他の行には、単語、ラベル、その他のフィールドが含まれています。単語は最初のフィールドでなければならず、ラベルマッシュが最後であり、これらのフィールドは空間で区切られています。たとえば、PTB POSタグ付けコーパスのWSJ部分の最初のいくつかの線は、次のスニペットのようになければなりません。
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
ここでは、2つのモデルの実装を提供します。1つはLM-LSTM-CRF 、もう1つはそのバリアントであるLSTM-CRFで、単語レベルの構造とCRFのみが含まれています。 train_wc.pyとeval_wc.py LM-LSTM-CRFのスクリプトであり、 train_w.pyとeval_w.py LSTM-CRFのスクリプトです。これらのスクリプトの使用法は、パラメーター-h 、IE、
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
NERおよびPOSタグ付けのデフォルトの実行コマンド、およびNPチャンキングは次のとおりです。
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
他のデータセットまたはタスクの場合、特に小さなデータセットの場合、さまざまな停止パラメーターを試してみてください。 least_itersをより大きな値に設定することができます。また、一部のタスクでは、損失の速度が低下する場合、 lrを増やすことをお勧めします。
ここでは、LM-LSTM-CRFを、CONLL 2000チャンキングデータセット、CONLL 2003 NERデータセット、およびPTB POSタグ付けデータセットのWSJ部分の最近の最先端モデルと比較します。すべての実験は、GTX 1080 GPUで行われます。
元の実装でbioes_to_span関数に深刻なバグが見つかりました。正確なパフォーマンスとして、次の数値を参照してください。
モデルがPTB POSタグ付けデータセットのWSJ部分でのみトレーニングされている場合、結果は以下のように要約されています。
| モデル | マックス(acc) | 平均(acc) | std(acc) | 時間(h) |
|---|---|---|---|---|
| LM-LSTM-CRF | 91.35 | 91.24 | 0.12 | 4 |
| - 高速道路 | 90.87 | 90.79 | 0.07 | 4 |
| - 共同トレイン | 91.23 | 90.95 | 0.34 | 2 |
モデルがPTB POSタグ付けデータセットのWSJ部分でのみトレーニングされている場合、結果は以下のように要約されています。
| モデル | マックス(acc) | 平均(acc) | std(acc) | 報告(acc) | 時間(h) |
|---|---|---|---|---|---|
| Lample et al。 2016年 | 97.51 | 97.35 | 0.09 | n/a | 37 |
| Ma et al。 2016年 | 97.46 | 97.42 | 0.04 | 97.55 | 21 |
| LM-LSTM-CRF | 97.59 | 97.53 | 0.03 | 16 |
これら3つのタスクで事前に訓練されたモデルをリリースしました。チェックポイントファイルは、次のリンクでダウンロードできます。 NERモデルとチャンクモデル(近日公開)は、トレーニングセットと開発セットの両方でトレーニングされていることに注意してください。
| WSJ-PTB POSタグ付け | conll03 ner |
|---|---|
| args | args |
| モデル | モデル |
また、 eval_wc.pyこれらのチェックポイントをロードして実行するために提供されます。その使用は、コマンドpython eval_wc.py -hでアクセスでき、実行中のコマンドの例を以下に示します。
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
注釈付きの生のテキストには、未解決のテキストに注釈を付けるためにseq_wc.pyが提供されます。その使用は、コマンドpython seq_wc.py -hでアクセスでき、実行中のコマンドの例を以下に示します。
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
入力形式はCONLLに似ていますが、各行は1つのフィールド、トークンのみを含むために必要です。たとえば、入力ファイルは次のとおりです。
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
対応する出力は次のとおりです。
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


