LM LSTM CRF
implemented most features
Проверьте наш новый NER Toolkit
Этот проект обеспечивает высокопроизводительные инструменты маркировки последовательности с учетом символов, включая обучение, оценку и прогноз.
Подробности о LM-LSTM-CRF можно получить здесь, и реализация основана на библиотеке Pytorch.
ВАЖНО: Серьезная ошибка была обнаружена в функции bioes_to_span в исходной реализации, пожалуйста, обратитесь к номерам, представленным в разделе Clarderks как точную производительность.
Документы будут доступны здесь.
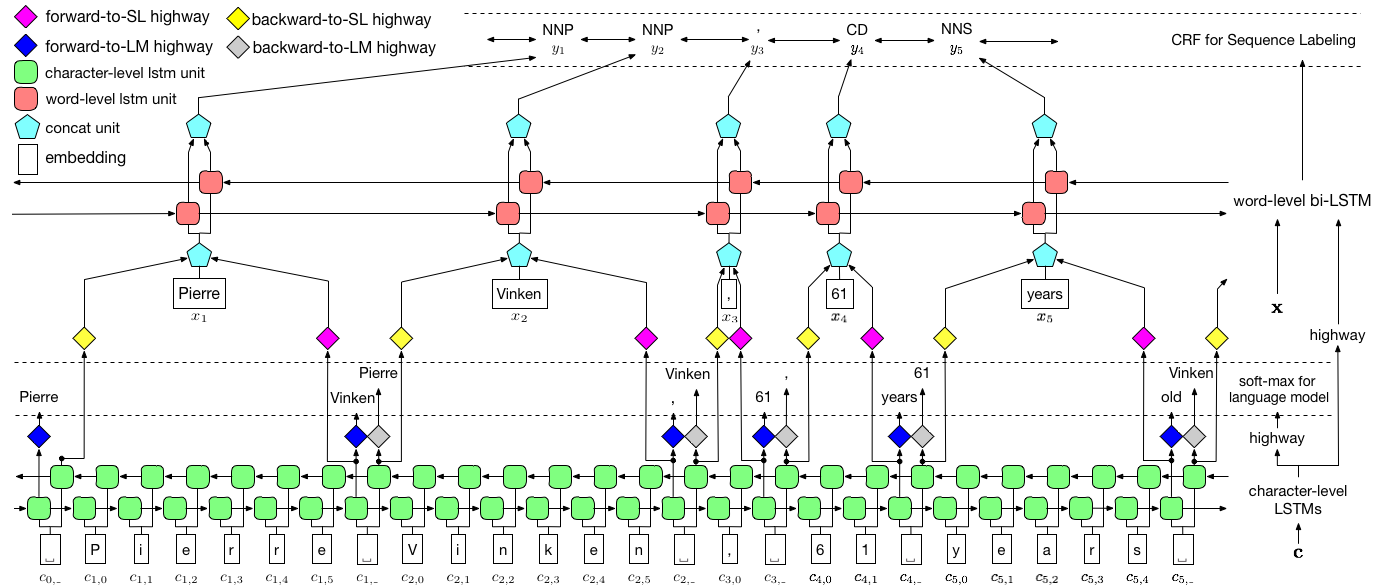
Как визуализировано выше, мы используем условное случайное поле (CRF) для захвата зависимостей метки и применяем иерархический LSTM для использования как входов уровня, так и уровня слов. Структура уровня ChAR дополнительно руководствуется языковой моделью, в то время как предварительно обученные встроения слов используются на уровне слов. Языковая модель и модель маркировки последовательности обучаются одновременно, и оба делают прогнозы на уровне слов. Шосовые сети используются для преобразования вывода LSTM уровня ChAR в различные семантические пространства и, таким образом, опосредуя эти две задачи и позволяя языковой модели расширить эти возможности для маркировки последовательности.
Для тренировок, графический процессор настоятельно рекомендуется для скорости. ЦП поддерживается, но обучение может быть чрезвычайно медленным.
Код основан на Pytorch и теперь поддерживает Pytorch 0,4 . Вы можете найти инструкции по установке здесь.
Код записан в Python 3.6. Его зависимости суммированы в File requirements.txt . Вы можете установить эти зависимости, как это:
pip3 install -r requirements.txt
В основном мы сосредоточены на наборе данных Conll 2003 NER, и код принимает свой исходный формат в качестве ввода. Однако из -за проблемы лицензии мы ограничены для распространения этого набора данных. Вы должны быть в состоянии получить его здесь. Вы также можете захотеть искать в Интернете (например, GitHub), кто -то может выпустить его случайно.
Мы предполагаем, что корпус форматируется таким же, как и набор данных Conll 2003 NER. Более конкретно, пустые линии используются в качестве разделителей между предложениями, а разделитель между документами является специальной линией, как показано ниже.
-DOCSTART- -X- -X- -X- O
Другие строки содержат слова, метки и другие поля. Слово должно быть первым полем, метка Mush будет последним , и эти поля разделены пространством . Например, первые несколько строк в части WSJ корпуса тега PTB POS должны быть похожи на следующий фрагмент.
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
Здесь мы предоставляем реализации для двух моделей, одна -LM-LSTM-CRF , а другая-его вариант, LSTM-CRF , который содержит только структуру уровня слова и CRF. train_wc.py и eval_wc.py -это сценарии для LM-LSTM-CRF, а train_w.py и eval_w.py -сценарии для LSTM-CRF. Использование этих сценариев можно получить с помощью параметра -h , т.е.
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
Команды по умолчанию по умолчанию для тега NER и POS, а NP Chunking - это:
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
Для других наборов данных или задач вы можете попробовать разные параметры остановки, особенно для более мелких наборов данных, вы можете установить least_iters на более широкое значение; И для некоторых задач, если скорость уменьшения потерь слишком медленная, вы можете увеличить lr .
Здесь мы сравниваем LM-LSTM-CRF с недавними современными моделями на наборе данных Conll 2000 Chunking, наборе данных Conll 2003 NER и частью WSJ POST набора данных PTB POS. Все эксперименты проводятся на графическом процессоре GTX 1080.
Серьезная ошибка была найдена на функции bioes_to_span в исходной реализации, пожалуйста, обратитесь к следующим числам как точную производительность.
Когда модели обучаются только на наборе данных WSJ набора данных PTB POS, результаты суммируются, как показано ниже.
| Модель | Макс (ACC) | Среднее (ACC) | STD (ACC) | Время (h) |
|---|---|---|---|---|
| LM-LSTM-CRF | 91.35 | 91.24 | 0,12 | 4 |
| - шоссе | 90.87 | 90.79 | 0,07 | 4 |
| -Коайд | 91.23 | 90,95 | 0,34 | 2 |
Когда модели обучаются только на наборе данных WSJ набора данных PTB POS, результаты суммируются, как показано ниже.
| Модель | Макс (ACC) | Среднее (ACC) | STD (ACC) | Сообщено (ACC) | Время (h) |
|---|---|---|---|---|---|
| Layple et al. 2016 | 97.51 | 97.35 | 0,09 | N/a | 37 |
| Ma et al. 2016 | 97.46 | 97.42 | 0,04 | 97.55 | 21 |
| LM-LSTM-CRF | 97.59 | 97.53 | 0,03 | 16 |
Мы выпустили предварительно обученные модели по этим трем задачам. Файл контрольной точки может быть загружен по следующим ссылкам. Обратите внимание, что модель NER и модель Chunking (скоро) обучаются как на учебном наборе, так и на набор разработки:
| WSJ-PTB POS-тег | Conll03 ner |
|---|---|
| Аргс | Аргс |
| Модель | Модель |
Кроме того, eval_wc.py предоставляется для загрузки и запуска этих контрольных точек. Его использование может быть доступно по команде python eval_wc.py -h , и приведен пример команды запуска:
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
Для аннотированного необработанного текста seq_wc.py предоставляется для аннотирования без аннотированного текста. Его использование может быть доступно по команде python seq_wc.py -h , и приведенный ниже пример команды выполняется:
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
Входной формат похож на Conll, но каждая строка требуется, чтобы содержать только одно поле, токен. Например, входной файл может быть:
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
и соответствующий вывод:
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


