LM LSTM CRF
implemented most features
检查我们的新NER工具包
该项目提供了高性能的角色感知序列标签工具,包括培训,评估和预测。
有关LM-LSTM-CRF的详细信息可以在此处访问,并且实现基于Pytorch库。
重要的是:在原始实现中,在bioes_to_span函数上发现了一个严重的错误,请参阅“基准”部分中报告的数字作为准确的性能。
这些文档将在这里可用。
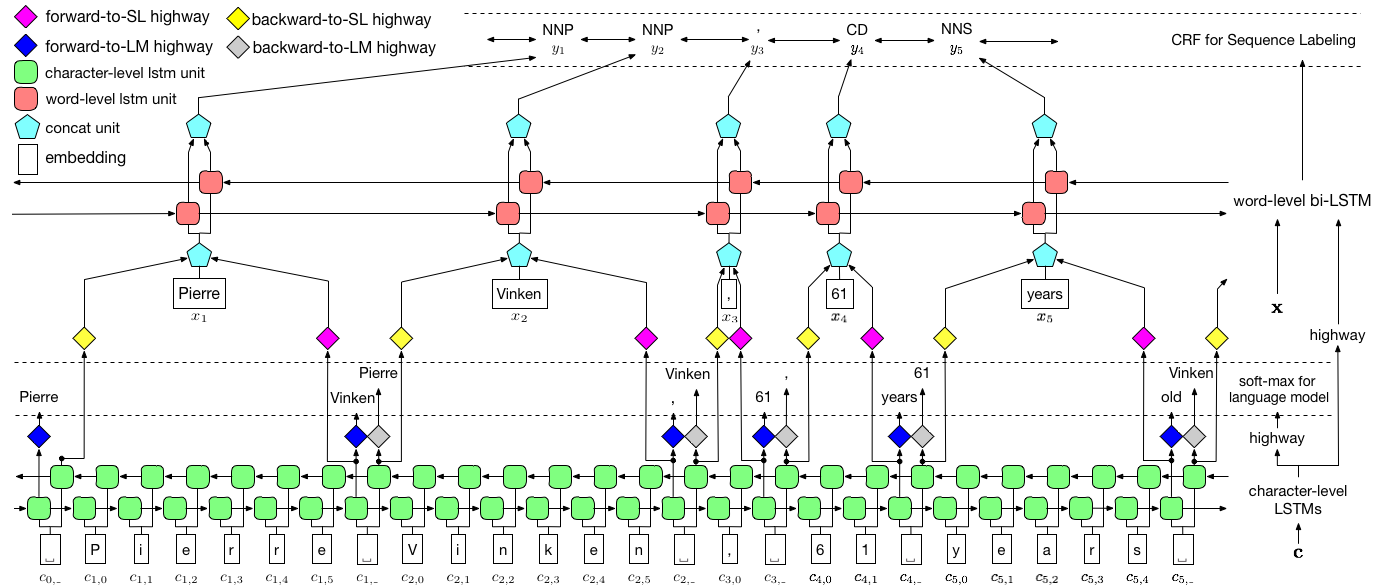
如上所述,我们使用条件随机字段(CRF)来捕获标签依赖性,并采用层次LSTM来利用char级别和文字级输入。 char级结构由语言模型进一步指导,而预训练的单词嵌入在文字级别中利用。语言模型和序列标签模型同时训练,并且都在文字级别进行预测。高速公路网络用于将Char-Level LSTM的输出转换为不同的语义空间,从而介导这两个任务并允许语言模型赋予序列标记。
对于培训,强烈建议使用GPU以换取速度。 CPU得到了支持,但培训可能非常慢。
该代码基于Pytorch,现在支持Pytorch 0.4 。您可以在此处找到安装说明。
该代码以Python 3.6编写。它的依赖项总结在文件requirements.txt中。您可以这样安装这些依赖项:
pip3 install -r requirements.txt
我们主要关注Conll 2003 NER数据集,该代码将其原始格式作为输入。但是,由于许可问题,我们仅限于分发此数据集。您应该能够在这里得到它。您可能还想在线搜索(例如,github),可能会意外释放它。
我们假设语料库的格式与Conll 2003 NER数据集一样。更具体地说,空线被用作句子之间的分离器,文档之间的分离器是以下特殊行。
-DOCSTART- -X- -X- -X- O
其他行包含单词,标签和其他字段。单词必须是第一个字段,标签是最后一个字段,并且这些字段被空间隔开。例如,PTB POS标记语料库的WSJ部分中的前几行应该像以下片段。
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
在这里,我们为两个模型提供了实现,一个是LM-LSTM-CRF ,另一个是其变体LSTM-CRF ,它仅包含单词级结构和CRF。 train_wc.py和eval_wc.py是LM-LSTM-CRF的脚本,而train_w.py和eval_w.py是LSTM-CRF的脚本。这些脚本的用法可以通过参数-h ,即
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
NER和POS标签的默认运行命令以及NP块是:
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
对于其他数据集或任务,您可能想尝试不同的停止参数,尤其是对于较小的数据集,您可能需要将least_iters设置为较大的值;对于某些任务,如果损失速度的速度太慢,则可能需要增加lr 。
在这里,我们将LM-LSTM-CRF与Conll 2000块数据集,Conll 2003 NER数据集和PTB POS标签数据集的WSJ部分进行比较。所有实验均在GTX 1080 GPU上进行。
在原始实现中,在bioes_to_span函数上发现了一个严重的错误,请将以下数字称为准确的性能。
当模型仅在PTB POS标记数据集的WSJ部分训练时,结果将如下汇总。
| 模型 | 最大(ACC) | 平均(ACC) | 性病(ACC) | 时间(h) |
|---|---|---|---|---|
| lm-lstm-crf | 91.35 | 91.24 | 0.12 | 4 |
| - 高速公路 | 90.87 | 90.79 | 0.07 | 4 |
| - 共同训练 | 91.23 | 90.95 | 0.34 | 2 |
当模型仅在PTB POS标记数据集的WSJ部分训练时,结果将如下汇总。
| 模型 | 最大(ACC) | 平均(ACC) | 性病(ACC) | 报道(ACC) | 时间(h) |
|---|---|---|---|---|---|
| Lample等。 2016 | 97.51 | 97.35 | 0.09 | N/A。 | 37 |
| Ma等。 2016 | 97.46 | 97.42 | 0.04 | 97.55 | 21 |
| lm-lstm-crf | 97.59 | 97.53 | 0.03 | 16 |
我们在这三个任务上发布了预训练的模型。可以通过以下链接下载检查点文件。请注意,NER模型和块模型(即将推出)都经过培训集和开发集的培训:
| WSJ-PTB POS标签 | conll03 ner |
|---|---|
| args | args |
| 模型 | 模型 |
另外,还提供了eval_wc.py来加载和运行这些检查点。可以通过命令python eval_wc.py -h访问其用法,下面提供了一个运行命令示例:
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
要注释的原始文本,向未注销的文本提供了seq_wc.py 。可以通过命令python seq_wc.py -h访问其用法,下面提供了一个运行命令示例:
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
输入格式类似于conll,但是每行只包含一个字段,令牌。例如,输入文件可能是:
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
相应的输出为:
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


