LM LSTM CRF
implemented most features
ตรวจสอบชุดเครื่องมือใหม่ของเรา
โครงการนี้ให้เครื่องมือการติดฉลากลำดับตัวละครที่มีประสิทธิภาพสูงรวมถึงการฝึกอบรมการประเมินผลและการทำนาย
รายละเอียดเกี่ยวกับ LM-LSTM-CRF สามารถเข้าถึงได้ที่นี่และการใช้งานจะขึ้นอยู่กับไลบรารี Pytorch
สำคัญ: พบข้อผิดพลาดที่ร้ายแรงในฟังก์ชั่น bioes_to_span ในการใช้งานดั้งเดิมโปรดดูตัวเลขที่รายงานในส่วนการเปรียบเทียบเป็นประสิทธิภาพที่แม่นยำ
เอกสารจะมีอยู่ที่นี่
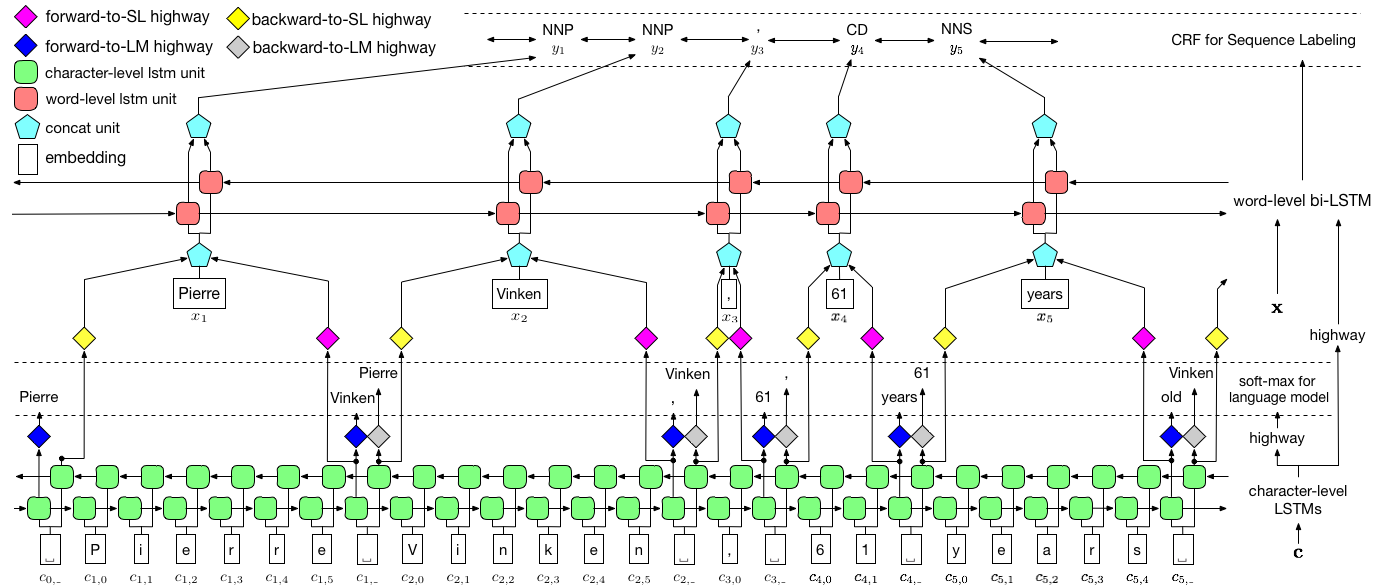
ดังที่เห็นภาพข้างต้นเราใช้ฟิลด์แบบสุ่มแบบมีเงื่อนไข (CRF) เพื่อจับการพึ่งพาฉลากและใช้ LSTM แบบลำดับชั้นเพื่อใช้ประโยชน์จากอินพุตทั้งระดับถ่านและระดับคำ โครงสร้างระดับถ่านได้รับการชี้นำเพิ่มเติมโดยแบบจำลองภาษาในขณะที่การฝังคำที่ผ่านการฝึกอบรมมาก่อนจะถูกยกระดับในระดับคำ รูปแบบภาษาและรูปแบบการติดฉลากลำดับได้รับการฝึกฝนในเวลาเดียวกันและทั้งคู่ทำการคาดการณ์ในระดับคำ เครือข่ายทางหลวงใช้ในการแปลงเอาต์พุตของ LSTM ระดับถ่านเป็นพื้นที่ความหมายที่แตกต่างกันและทำให้การไกล่เกลี่ยงานทั้งสองนี้และทำให้แบบจำลองภาษาสามารถเพิ่มขีดความสามารถในการติดฉลากลำดับ
สำหรับการฝึกอบรมแนะนำให้ใช้ GPU อย่างมากสำหรับความเร็ว CPU ได้รับการสนับสนุน แต่การฝึกอบรมอาจช้ามาก
รหัสขึ้นอยู่กับ pytorch และ รองรับ pytorch 0.4 ตอนนี้ คุณสามารถค้นหาคำแนะนำการติดตั้งได้ที่นี่
รหัสถูกเขียนใน Python 3.6 การพึ่งพาของมันสรุปไว้ใน requirements.txt ไฟล์ txt คุณสามารถติดตั้งการพึ่งพาเหล่านี้ได้เช่นนี้:
pip3 install -r requirements.txt
เรามุ่งเน้นไปที่ชุดข้อมูลของ Conll 2003 NER และรหัสใช้รูปแบบดั้งเดิมเป็นอินพุต อย่างไรก็ตามเนื่องจากปัญหาใบอนุญาตเราถูก จำกัด ให้แจกจ่ายชุดข้อมูลนี้ คุณควรจะได้รับที่นี่ คุณอาจต้องการค้นหาออนไลน์ (เช่น GitHub) ใครบางคนอาจปล่อยมันโดยไม่ตั้งใจ
เราถือว่าคลังข้อมูลถูกจัดรูปแบบเหมือนกับชุดข้อมูล Conll 2003 NER โดยเฉพาะอย่างยิ่ง สายเปล่า จะใช้เป็นตัวคั่นระหว่างประโยคและตัวคั่นระหว่างเอกสารเป็นบรรทัดพิเศษดังต่อไปนี้
-DOCSTART- -X- -X- -X- O
บรรทัดอื่น ๆ มีคำว่าป้ายกำกับและฟิลด์อื่น ๆ Word ต้องเป็นฟิลด์ แรก , Label Mush เป็น ครั้งสุดท้าย และฟิลด์เหล่านี้จะ ถูกคั่นด้วยอวกาศ ตัวอย่างเช่นหลายบรรทัดแรกในส่วน WSJ ของ Corpus แท็ก PTB POS ควรเป็นตัวอย่างดังต่อไปนี้
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
ที่นี่เราให้การใช้งานสำหรับสองรุ่นหนึ่งคือ LM-LSTM-CRF และอีกรุ่นคือตัวแปร LSTM-CRF ซึ่งมีโครงสร้างระดับคำและ CRF เท่านั้น train_wc.py และ eval_wc.py เป็นสคริปต์สำหรับ lm-lstm-crf ในขณะที่ train_w.py และ eval_w.py เป็นสคริปต์สำหรับ LSTM-CRF การใช้งานของสคริปต์เหล่านี้สามารถเข้าถึงได้โดยพารามิเตอร์ -h , เช่น
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
คำสั่งการรันเริ่มต้นสำหรับการติดแท็ก NER และ POS และ NP chunking คือ:
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
สำหรับชุดข้อมูลหรืองานอื่น ๆ คุณอาจต้องการลองใช้พารามิเตอร์การหยุดที่แตกต่างกันโดยเฉพาะอย่างยิ่งสำหรับชุดข้อมูลขนาดเล็กคุณอาจต้องการตั้ง least_iters ให้เป็นค่าที่ใหญ่กว่า และสำหรับงานบางอย่างหากความเร็วของการสูญเสียลดลงช้าเกินไปคุณอาจต้องการเพิ่ม lr
ที่นี่เราเปรียบเทียบ LM-LSTM-CRF กับโมเดลที่ทันสมัยล่าสุดในชุดข้อมูล Chunking ของ Conll 2000 ชุดข้อมูล CONLL 2003 NER และส่วน WSJ ของชุดข้อมูลการติดแท็ก PTB POS การทดลองทั้งหมดดำเนินการบน GTX 1080 GPU
พบข้อผิดพลาดที่ร้ายแรงในฟังก์ชั่น bioes_to_span ในการใช้งานดั้งเดิมโปรดอ้างอิงตัวเลขต่อไปนี้ว่าเป็นประสิทธิภาพที่แม่นยำ
เมื่อโมเดลได้รับการฝึกฝนเฉพาะในส่วน WSJ ของชุดข้อมูลการติดแท็ก PTB POS ผลลัพธ์จะถูกสรุปไว้ด้านล่าง
| แบบอย่าง | สูงสุด (ACC) | ค่าเฉลี่ย (ACC) | std (ACC) | เวลา (h) |
|---|---|---|---|---|
| LM-LSTM-CRF | 91.35 | 91.24 | 0.12 | 4 |
| - ทางหลวง | 90.87 | 90.79 | 0.07 | 4 |
| -การฝึกอบรม | 91.23 | 90.95 | 0.34 | 2 |
เมื่อโมเดลได้รับการฝึกฝนเฉพาะในส่วน WSJ ของชุดข้อมูลการติดแท็ก PTB POS ผลลัพธ์จะถูกสรุปไว้ด้านล่าง
| แบบอย่าง | สูงสุด (ACC) | ค่าเฉลี่ย (ACC) | std (ACC) | รายงาน (ACC) | เวลา (h) |
|---|---|---|---|---|---|
| Lample และคณะ ปี 2559 | 97.51 | 97.35 | 0.09 | N/A | 37 |
| Ma et al. ปี 2559 | 97.46 | 97.42 | 0.04 | 97.55 | 21 |
| LM-LSTM-CRF | 97.59 | 97.53 | 0.03 | 16 |
เราเปิดตัวโมเดลที่ผ่านการฝึกอบรมมาก่อนในงานทั้งสามนี้ ไฟล์จุดตรวจสามารถดาวน์โหลดได้ที่ลิงค์ต่อไปนี้ ขอให้สังเกตว่าโมเดล NER และรูปแบบ chunking (เร็ว ๆ นี้) ได้รับการฝึกอบรมทั้งชุดฝึกอบรมและชุดการพัฒนา:
| WSJ-PTB POS Tagging | conll03 ner |
|---|---|
| อาร์กอน | อาร์กอน |
| แบบอย่าง | แบบอย่าง |
นอกจากนี้ eval_wc.py มีให้สำหรับการโหลดและเรียกใช้จุดตรวจเหล่านี้ การใช้งานสามารถเข้าถึงได้โดยคำสั่ง python eval_wc.py -h และตัวอย่างคำสั่งที่ทำงานอยู่ด้านล่าง:
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
ในการใส่คำอธิบายประกอบข้อความดิบ seq_wc.py มีให้สำหรับคำอธิบายประกอบข้อความที่ไม่ได้อธิบายคำอธิบายประกอบ การใช้งานสามารถเข้าถึงได้โดยคำสั่ง python seq_wc.py -h และตัวอย่างคำสั่งที่ทำงานอยู่ด้านล่าง:
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
รูปแบบอินพุตนั้นคล้ายกับ Conll แต่แต่ละบรรทัดจะต้องมีเพียงฟิลด์เดียวเท่านั้นโทเค็น ตัวอย่างเช่นไฟล์อินพุตอาจเป็น:
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
และผลลัพธ์ที่สอดคล้องกันคือ:
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


