LM LSTM CRF
implemented most features
Consulte nuestro nuevo kit de herramientas NER
Este proyecto proporciona herramientas de etiquetado de secuencia de carácter de alto rendimiento, incluida la capacitación, la evaluación y la predicción.
Se pueden acceder a los detalles sobre LM-LSTM-CRF aquí, y la implementación se basa en la Biblioteca Pytorch.
IMPORTANTE: Se encontró un error serio en la función bioes_to_span en la implementación original, consulte los números informados en la sección de puntos de referencia como el rendimiento preciso.
Los documentos estarían disponibles aquí.
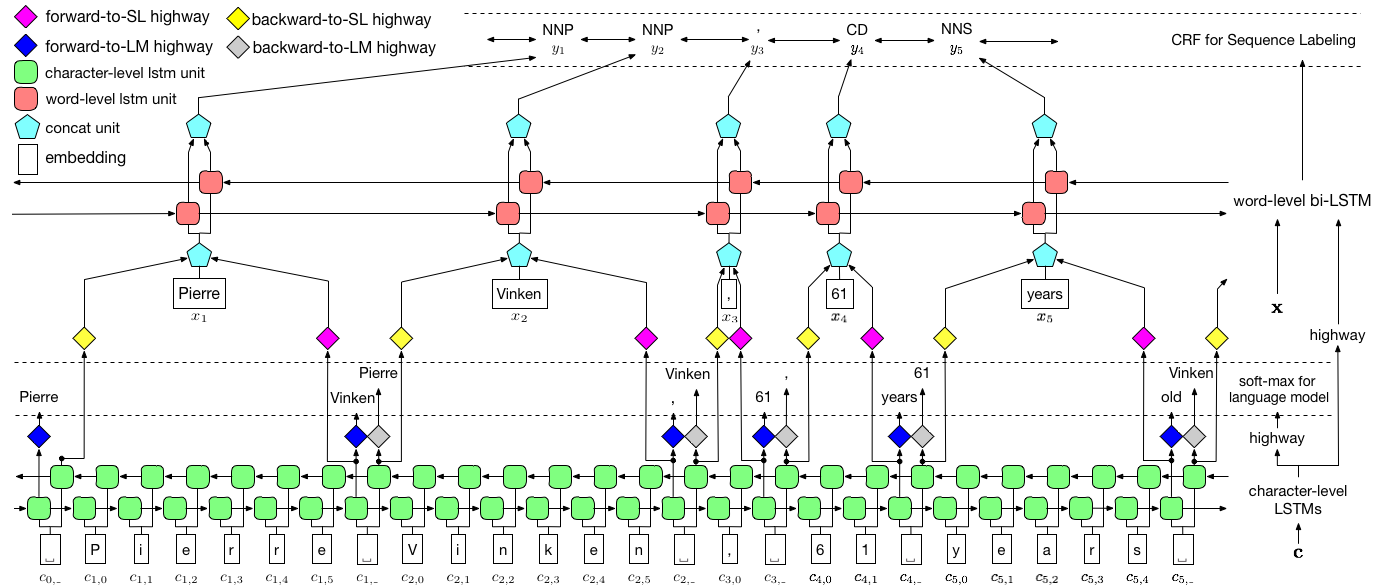
Como se visualizó anteriormente, utilizamos un campo aleatorio condicional (CRF) para capturar las dependencias de las etiquetas y adoptamos un LSTM jerárquico para aprovechar las entradas de nivel de char y de palabras. La estructura de nivel de char se guía aún más por un modelo de lenguaje, mientras que los incrustaciones de palabras previamente entrenadas se aprovechan en el nivel de palabras. El modelo de lenguaje y el modelo de etiquetado de secuencia están entrenados al mismo tiempo, y ambas hacen predicciones a nivel de palabra. Las redes de carreteras se utilizan para transformar la salida de LSTM a nivel de char en diferentes espacios semánticos, y así mediar estas dos tareas y permitir que el modelo de lenguaje empodere el etiquetado de secuencia.
Para el entrenamiento, se recomienda una GPU para la velocidad. La CPU es compatible, pero el entrenamiento podría ser extremadamente lento.
El código se basa en Pytorch y admite Pytorch 0.4 ahora . Puede encontrar instrucciones de instalación aquí.
El código está escrito en Python 3.6. Sus dependencias se resumen en los requirements.txt del archivo.txt. Puede instalar estas dependencias como esta:
pip3 install -r requirements.txt
Nos centramos principalmente en el conjunto de datos NER de Conll 2003, y el código toma su formato original como entrada. Sin embargo, debido al problema de la licencia, estamos restringidos a distribuir este conjunto de datos. Deberías poder conseguirlo aquí. También es posible que desee buscar en línea (por ejemplo, GitHub), alguien podría liberarlo accidentalmente.
Suponemos que el corpus está formateado de la misma manera que el conjunto de datos NER de Conll 2003. Más específicamente, las líneas vacías se usan como separadores entre oraciones, y el separador entre documentos es una línea especial como se muestra a continuación.
-DOCSTART- -X- -X- -X- O
Otras líneas contienen palabras, etiquetas y otros campos. La palabra debe ser el primer campo, la papilla de etiqueta será la última , y estos campos están separados por el espacio . Por ejemplo, las primeras líneas en la parte WSJ del Corpus de etiquetado PTB POS deberían ser como el siguiente fragmento.
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
Aquí proporcionamos implementaciones para dos modelos, uno es LM-LSTM-CRF y el otro es su variante, LSTM-CRF , que solo contiene la estructura de nivel de palabras y CRF. train_wc.py y eval_wc.py son scripts para LM-LSTM-CRF, mientras que train_w.py y eval_w.py son scripts para LSTM-CRF. Los usos de estos scripts pueden acceder mediante el parámetro -h , es decir,
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
Los comandos de ejecución predeterminados para el etiquetado NER y POS, y NP Chuncking son:
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
Para otros conjuntos de datos o tareas, es posible que desee probar diferentes parámetros de detención, especialmente, para un conjunto de datos más pequeño, es posible que desee establecer least_iters en un valor más grande; Y para algunas tareas, si la velocidad de la disminución de la velocidad es demasiado lenta, es posible que desee aumentar lr .
Aquí comparamos LM-LSTM-CRF con modelos recientes de última generación en el conjunto de datos de folleto Conll 2000, el conjunto de datos NER CONLL 2003 y la parte WSJ del conjunto de datos de etiquetado PTB POS. Todos los experimentos se realizan en una GPU GTX 1080.
Se encontró un error serio en la función bioes_to_span en la implementación original, consulte los siguientes números como el rendimiento preciso.
Cuando los modelos solo están entrenados en la parte WSJ del conjunto de datos de etiquetado PTB POS, los resultados se resumen a continuación.
| Modelo | Max (ACC) | Media (ACC) | STD (ACC) | Tiempo (h) |
|---|---|---|---|---|
| LM-LSTM-CRF | 91.35 | 91.24 | 0.12 | 4 |
| -- Carretera | 90.87 | 90.79 | 0.07 | 4 |
| -Co-tren | 91.23 | 90.95 | 0.34 | 2 |
Cuando los modelos solo están entrenados en la parte WSJ del conjunto de datos de etiquetado PTB POS, los resultados se resumen a continuación.
| Modelo | Max (ACC) | Media (ACC) | STD (ACC) | Reportado (ACC) | Tiempo (h) |
|---|---|---|---|---|---|
| Lampher et al. 2016 | 97.51 | 97.35 | 0.09 | N / A | 37 |
| Ma et al. 2016 | 97.46 | 97.42 | 0.04 | 97.55 | 21 |
| LM-LSTM-CRF | 97.59 | 97.53 | 0.03 | 16 |
Lanzamos modelos previamente capacitados en estas tres tareas. El archivo de punto de control se puede descargar en los siguientes enlaces. Observe que el modelo NER y el modelo de fragmentación (próximamente) están entrenados tanto en el conjunto de capacitación como en el conjunto de desarrollo:
| Etiquetado POS de WSJ-PTB | Conll03 ner |
|---|---|
| Argumentos | Argumentos |
| Modelo | Modelo |
Además, se proporciona eval_wc.py para cargar y ejecutar estos puntos de control. Se puede acceder a su uso por comando python eval_wc.py -h , y se proporciona un ejemplo de comando en ejecución a continuación:
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
Para el texto en bruto anotado, se proporciona seq_wc.py para anotar el texto no anotado. Se puede acceder a su uso por comando python seq_wc.py -h , y se proporciona un ejemplo de comando en ejecución a continuación:
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
El formato de entrada es similar a Conll, pero se requiere que cada línea solo contenga un campo, Token. Por ejemplo, un archivo de entrada podría ser:
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
y la salida correspondiente es:
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


