LM LSTM CRF
implemented most features
Verifique nosso novo kit de ferramentas nerds
Este projeto fornece ferramentas de rotulagem de sequência de alto desempenho, incluindo treinamento, avaliação e previsão.
Detalhes sobre o LM-LSTM-CRF podem ser acessados aqui, e a implementação é baseada na biblioteca Pytorch.
IMPORTANTE: Um bug grave foi encontrado na função bioes_to_span na implementação original, consulte os números relatados na seção de referência como desempenho preciso.
Os documentos estariam disponíveis aqui.
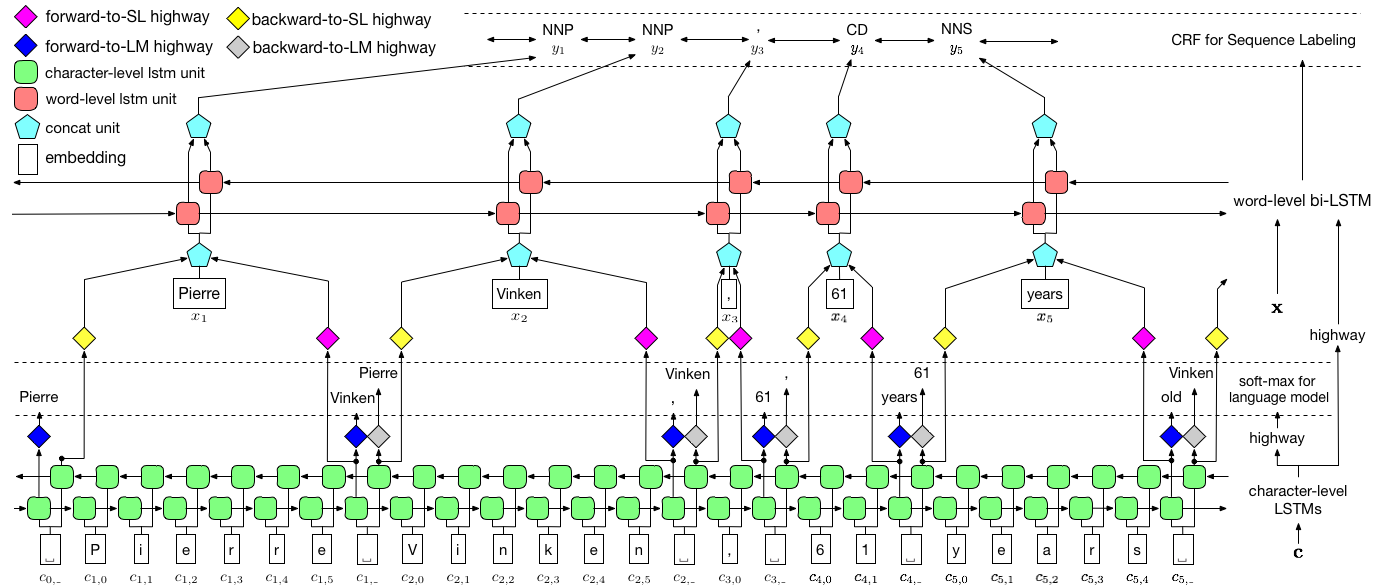
Conforme visualizado acima, usamos o campo aleatório condicional (CRF) para capturar dependências do rótulo e adotar um LSTM hierárquico para alavancar as entradas de nível de char e no nível de palavras. A estrutura no nível do char é ainda mais guiada por um modelo de idioma, enquanto as incorporações de palavras pré-treinadas são alavancadas no nível da palavra. O modelo de idioma e o modelo de rotulagem de sequência são treinados ao mesmo tempo e ambos fazem previsões no nível da palavra. As redes de rodovias são usadas para transformar a saída do LSTM de nível de char em diferentes espaços semânticos, mediando essas duas tarefas e permitindo que o modelo de linguagem capacite a marcação de sequência.
Para treinamento, uma GPU é fortemente recomendada para a velocidade. A CPU é suportada, mas o treinamento pode ser extremamente lento.
O código é baseado no Pytorch e suporta Pytorch 0.4 agora . Você pode encontrar instruções de instalação aqui.
O código é escrito no Python 3.6. Suas dependências estão resumidas nos requirements.txt de arquivo.txt. Você pode instalar essas dependências como esta:
pip3 install -r requirements.txt
Nós nos concentramos principalmente no conjunto de dados NER da Conll 2003, e o código toma seu formato original como entrada. No entanto, devido ao problema da licença, estamos restritos a distribuir esse conjunto de dados. Você deve conseguir obtê -lo aqui. Você também pode pesquisar on -line (por exemplo, github), alguém pode lançá -lo acidentalmente.
Assumimos que o corpus é formatado da mesma forma que o conjunto de dados NER da Conll 2003. Mais especificamente, as linhas vazias são usadas como separadores entre as frases, e o separador entre os documentos é uma linha especial como abaixo.
-DOCSTART- -X- -X- -X- O
Outras linhas contém palavras, rótulos e outros campos. A palavra deve ser o primeiro campo, o rótulo é o último e esses campos são separados pelo espaço . Por exemplo, as primeiras linhas na parte WSJ do corpus de etiqueta do PTB POS devem ser como o seguinte snippet.
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
Aqui, fornecemos implementações para dois modelos, um é LM-LSTM-CRF e o outro é sua variante, LSTM-CRF , que contém apenas a estrutura e o CRF no nível da palavra. train_wc.py e eval_wc.py são scripts para LM-LSTM-CRF, enquanto train_w.py e eval_w.py são scripts para LSTM-CRF. Os usos desses scripts podem ser acessados pelo parâmetro -h , ou seja,
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
Os comandos em execução padrão para marcação de NER e POS, e o NP Chunking são:
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
Para outros conjuntos de dados ou tarefas, você pode tentar parar diferentes parâmetros, especialmente para um conjunto de dados menores, você pode definir pelo least_iters como um valor maior; E para algumas tarefas, se a velocidade da perda é muito lenta, convém aumentar lr .
Aqui, comparamos o LM-LSTM-CRF com os recentes modelos de ponta no conjunto de dados de Chunking Conll 2000, o conjunto de dados NER Conll 2003 e a parte WSJ do conjunto de dados de marcação do PTB POS. Todas as experiências são realizadas em uma GPU GTX 1080.
Um bug grave foi encontrado na função bioes_to_span na implementação original, consulte os seguintes números como o desempenho preciso.
Quando os modelos são treinados apenas na parte WSJ do conjunto de dados de marcação do PTB POS, os resultados são resumidos como abaixo.
| Modelo | Max (ACC) | Média (ACC) | Std (ACC) | Tempo (h) |
|---|---|---|---|---|
| LM-LSTM-CRF | 91.35 | 91.24 | 0,12 | 4 |
| -- Autoestrada | 90.87 | 90.79 | 0,07 | 4 |
| -Co-treino | 91.23 | 90.95 | 0,34 | 2 |
Quando os modelos são treinados apenas na parte WSJ do conjunto de dados de marcação do PTB POS, os resultados são resumidos como abaixo.
| Modelo | Max (ACC) | Média (ACC) | Std (ACC) | Relatado (ACC) | Tempo (h) |
|---|---|---|---|---|---|
| Lample et al. 2016 | 97.51 | 97.35 | 0,09 | N / D | 37 |
| Ma et al. 2016 | 97.46 | 97.42 | 0,04 | 97.55 | 21 |
| LM-LSTM-CRF | 97.59 | 97.53 | 0,03 | 16 |
Lançamos modelos pré-treinados nessas três tarefas. O arquivo do ponto de verificação pode ser baixado nos seguintes links. Observe que o modelo NER e o modelo de chunking (em breve) são treinados no conjunto de treinamento e no conjunto de desenvolvimento:
| WSJ-PTB POS marcando | CONLL03 NER |
|---|---|
| Args | Args |
| Modelo | Modelo |
Além disso, eval_wc.py é fornecido para carregar e executar esses pontos de verificação. Seu uso pode ser acessado pelo comando python eval_wc.py -h , e um exemplo de comando em execução é fornecido abaixo:
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
Para textos brutos anotados, seq_wc.py é fornecido para anotar texto não anotado. Seu uso pode ser acessado pelo comando python seq_wc.py -h , e um exemplo de comando em execução é fornecido abaixo:
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
O formato de entrada é semelhante ao CONLL, mas cada linha é necessária para conter apenas um campo, token. Por exemplo, um arquivo de entrada pode ser:
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
e a saída correspondente é:
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


