LM LSTM CRF
implemented most features
Vérifiez notre nouvelle boîte à outils NER
Ce projet fournit des outils de marquage de séquences aux personnages haute performance, y compris la formation, l'évaluation et la prédiction.
Les détails sur LM-LSTM-CRF sont accessibles ici, et l'implémentation est basée sur la bibliothèque Pytorch.
IMPORTANT: Un bogue sérieux a été trouvé sur la fonction bioes_to_span dans la mise en œuvre d'origine, veuillez consulter les nombres rapportés dans la section Benchmarks comme des performances précises.
Les documents seraient disponibles ici.
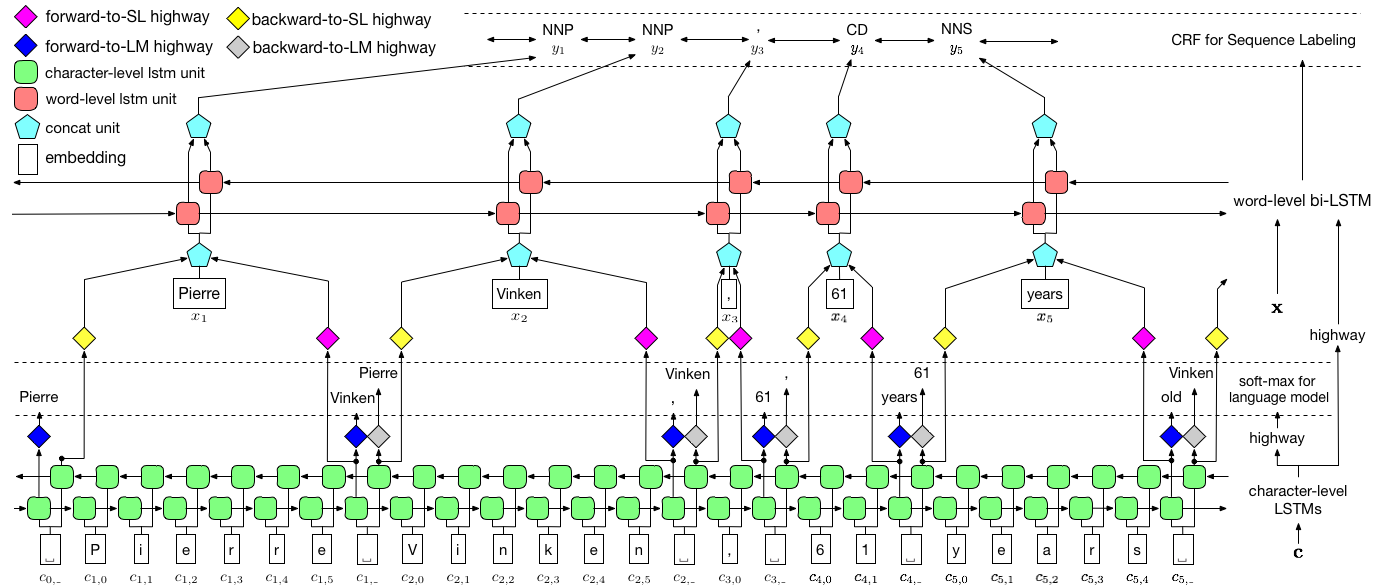
Comme visualisé ci-dessus, nous utilisons un champ aléatoire conditionnel (CRF) pour capturer les dépendances des étiquettes et adoptons un LSTM hiérarchique pour tirer parti des entrées au niveau du charbon et au niveau des mots. La structure au niveau du charbon est en outre guidée par un modèle de langue, tandis que les incorporations de mots pré-formées sont exploitées au niveau des mots. Le modèle de langue et le modèle d'étiquetage de séquence sont formés en même temps, et tous deux font des prédictions au niveau des mots. Les réseaux routiers sont utilisés pour transformer la sortie du LSTM de niveau Char en différents espaces sémantiques, et ainsi en médiant ces deux tâches et en permettant à un modèle de langue pour autonomiser l'étiquetage des séquences.
Pour l'entraînement, un GPU est fortement recommandé pour la vitesse. Le processeur est soutenu mais la formation pourrait être extrêmement lente.
Le code est basé sur Pytorch et prend en charge Pytorch 0.4 maintenant . Vous pouvez trouver des instructions d'installation ici.
Le code est écrit dans Python 3.6. Ses dépendances sont résumées dans le fichier requirements.txt . Vous pouvez installer ces dépendances comme ceci:
pip3 install -r requirements.txt
Nous nous concentrons principalement sur l'ensemble de données CONLL 2003 NER, et le code prend son format d'origine comme entrée. Cependant, en raison du problème de licence, nous sommes limités à distribuer cet ensemble de données. Vous devriez pouvoir l'obtenir ici. Vous pouvez également rechercher en ligne (par exemple, github), quelqu'un pourrait le libérer accidentellement.
Nous supposons que le corpus est formaté de la même manière que l'ensemble de données CONLL 2003 NER. Plus précisément, les lignes vides sont utilisées comme séparateurs entre les phrases, et le séparateur entre les documents est une ligne spéciale comme ci-dessous.
-DOCSTART- -X- -X- -X- O
D'autres lignes contient des mots, des étiquettes et d'autres champs. Le mot doit être le premier champ, l'étiquette Mush soit la dernière , et ces champs sont séparés par l'espace . Par exemple, les premières lignes de la partie WSJ du corpus de marquage PTB POS devraient être comme l'extrait suivant.
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
Ici, nous fournissons des implémentations pour deux modèles, l'un est LM-LSTM-CRF et l'autre est sa variante, LSTM-CRF , qui ne contient que la structure au niveau du mot et le CRF. train_wc.py et eval_wc.py sont des scripts pour LM-LSTM-CRF, tandis que train_w.py et eval_w.py sont des scripts pour LSTM-CRF. Les usages de ces scripts sont accessibles par le paramètre -h , c'est-à-dire,
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
Les commandes en cours d'exécution par défaut pour le marquage NER et POS, et la section NP sont:
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
Pour d'autres ensembles de données ou tâches, vous voudrez peut-être essayer différents paramètres d'arrêt, en particulier, pour un ensemble de données plus petit, vous voudrez peut-être définir least_iters sur une valeur plus grande; Et pour certaines tâches, si la vitesse de la perte diminue est trop lente, vous voudrez peut-être augmenter lr .
Ici, nous comparons LM-LSTM-CRF avec des modèles récents de pointe sur l'ensemble de données CONLL 2000 Chunking, le jeu de données CONLL 2003 NER et la partie WSJ de l'ensemble de données de marquage PTB POS. Toutes les expériences sont menées sur un GTX 1080 GPU.
Un bogue sérieux a été trouvé sur la fonction bioes_to_span dans l'implémentation d'origine, veuillez appeler les numéros suivants comme des performances précises.
Lorsque les modèles ne sont formés que sur la partie WSJ de l'ensemble de données de marquage PTB POS, les résultats sont résumés comme ci-dessous.
| Modèle | Max (ACC) | Moyenne (ACC) | STD (ACC) | Temps (h) |
|---|---|---|---|---|
| LM-LSTM-CRF | 91.35 | 91.24 | 0,12 | 4 |
| - Autoroute | 90.87 | 90,79 | 0,07 | 4 |
| - co-essai | 91.23 | 90,95 | 0,34 | 2 |
Lorsque les modèles ne sont formés que sur la partie WSJ de l'ensemble de données de marquage PTB POS, les résultats sont résumés comme ci-dessous.
| Modèle | Max (ACC) | Moyenne (ACC) | STD (ACC) | Rapporté (ACC) | Temps (h) |
|---|---|---|---|---|---|
| Lample et al. 2016 | 97.51 | 97.35 | 0,09 | N / A | 37 |
| Ma et al. 2016 | 97.46 | 97.42 | 0,04 | 97,55 | 21 |
| LM-LSTM-CRF | 97,59 | 97,53 | 0,03 | 16 |
Nous avons publié des modèles pré-formés sur ces trois tâches. Le fichier de point de contrôle peut être téléchargé sur les liens suivants. Notez que le modèle NER et le modèle de section (à venir bientôt) sont formés à la fois sur l'ensemble de formation et l'ensemble de développement:
| Tagging POS WSJ-PTB | Conll03 ner |
|---|---|
| Args | Args |
| Modèle | Modèle |
De plus, eval_wc.py est fourni pour charger et exécuter ces points de contrôle. Son utilisation est accessible par Commande python eval_wc.py -h , et un exemple de commande en cours d'exécution est fourni ci-dessous:
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
Pour annoter le texte brut, seq_wc.py est fourni pour annoter le texte non annoté. Son utilisation est accessible par la commande python seq_wc.py -h , et un exemple de commande en cours d'exécution est fourni ci-dessous:
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
Le format d'entrée est similaire à Conll, mais chaque ligne est nécessaire pour ne contenir qu'un seul champ, jeton. Par exemple, un fichier d'entrée pourrait être:
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
et la sortie correspondante est:
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


