LM LSTM CRF
implemented most features
تحقق من مجموعة أدوات NER الجديدة
يوفر هذا المشروع أدوات وضع العلامات على التسلسل ذات الأحرف العالية الأداء ، بما في ذلك التدريب والتقييم والتنبؤ.
يمكن الوصول إلى التفاصيل حول LM-LSTM-CRF هنا ، ويستند التنفيذ على مكتبة Pytorch.
هام: تم العثور على خطأ خطير في وظيفة bioes_to_span في التنفيذ الأصلي ، يرجى إحالة الأرقام المذكورة في قسم المعايير كأداء دقيق.
ستكون المستندات متاحة هنا.
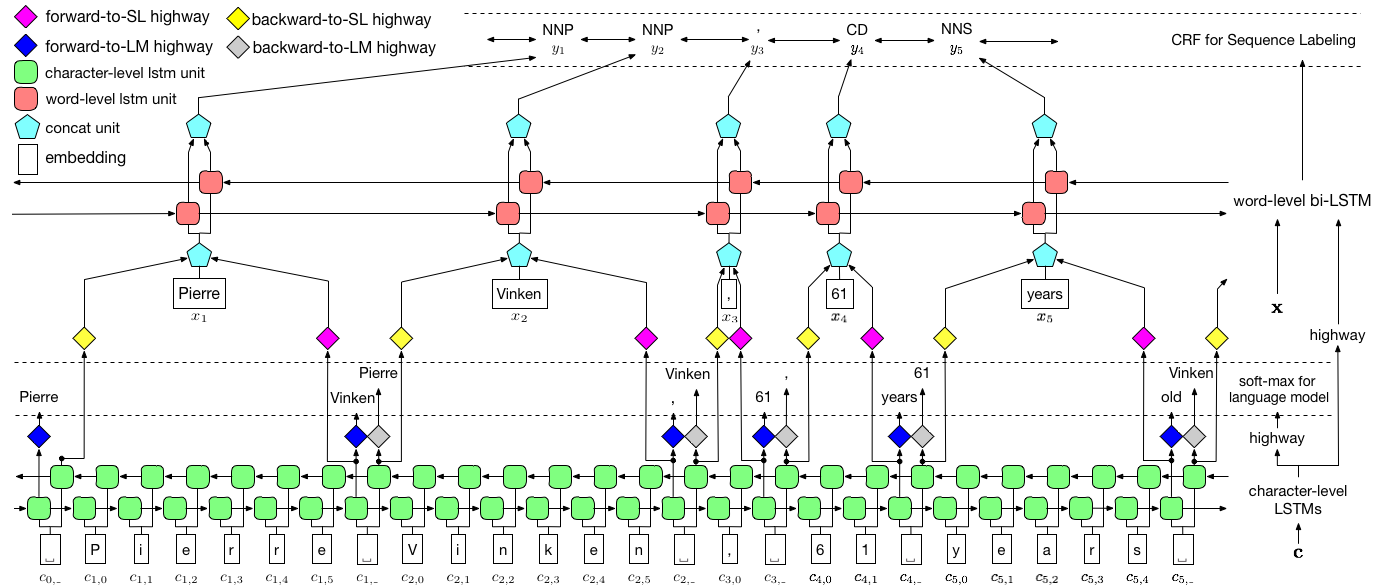
كما هو موضح أعلاه ، نستخدم الحقل العشوائي الشرطي (CRF) لالتقاط تبعيات الملصقات ، واعتماد LSTM هرمي للاستفادة من كل من المدخلات على مستوى char. يتم توجيه الهيكل على مستوى char بنموذج لغة ، في حين يتم الاستفادة من تضمينات الكلمات المدربة مسبقًا في مستوى الكلمات. يتم تدريب نموذج اللغة ونموذج وضع العلامات التسلسل في نفس الوقت ، وكلاهما يصنعان تنبؤات على مستوى الكلمات. تُستخدم شبكات الطرق السريعة لتحويل ناتج LSTM على مستوى Char إلى مساحات دلالية مختلفة ، وبالتالي التوسط في هاتين المهمتين والسماح لنموذج اللغة بتمكين وضع تسلسل.
للتدريب ، ينصح بشدة GPU بالسرعة. يتم دعم وحدة المعالجة المركزية ولكن التدريب قد يكون بطيئًا للغاية.
يعتمد الرمز على Pytorch ويدعم Pytorch 0.4 الآن . يمكنك العثور على تعليمات التثبيت هنا.
الكود مكتوب في Python 3.6. يتم تلخيص تبعياتها في requirements.txt الملف. يمكنك تثبيت هذه التبعيات مثل هذا:
pip3 install -r requirements.txt
نركز بشكل أساسي على مجموعة بيانات CONLL 2003 NER ، ويأخذ الرمز تنسيقه الأصلي كمدخلات. ومع ذلك ، نظرًا لقضية الترخيص ، نحن مقيدون لتوزيع مجموعة البيانات هذه. يجب أن تكون قادرًا على الحصول عليها هنا. قد ترغب أيضًا في البحث عبر الإنترنت (على سبيل المثال ، github) ، قد يطلقه شخص ما عن طريق الخطأ.
نحن نفترض أن المجموعة هي نفس مجموعة بيانات CONLL 2003 NER. وبشكل أكثر تحديداً ، يتم استخدام الخطوط الفارغة كفواصل بين الجمل ، والفاصل بين المستندات هو خط خاص على النحو التالي.
-DOCSTART- -X- -X- -X- O
تحتوي الخطوط الأخرى على كلمات وعلامات وحقول أخرى. يجب أن تكون الكلمة هي الحقل الأول ، وتصنيف Mush يكون الأخير ، ويتم فصل هذه الحقول عن طريق الفضاء . على سبيل المثال ، يجب أن تكون الخطوط العديدة الأولى في جزء WSJ من مجموعة وضع العلامات PTB POS مثل المقتطف التالي.
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
نحن هنا نقدم تطبيقات لنموذجين ، واحد هو LM-LSTM-CRF والآخر هو البديل ، LSTM-CRF ، والذي يحتوي فقط على بنية مستوى الكلمات و CRF. train_wc.py و eval_wc.py هي برامج نصية لـ LM-LSTM-CRF ، في حين أن train_w.py و eval_w.py هي البرامج النصية لـ LSTM-CRF. يمكن الوصول إلى استخدامات هذه البرامج النصية بواسطة المعلمة -h ، أي ،
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
أوامر التشغيل الافتراضية لعلامة NER و POS ، و NP Crunking هي:
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
بالنسبة لمجموعات البيانات أو المهام الأخرى ، قد ترغب في تجربة معلمات إيقاف مختلفة ، خاصة بالنسبة لمجموعة البيانات الأصغر ، قد ترغب في تعيين least_iters لقيمة أكبر ؛ وبالنسبة لبعض المهام ، إذا كانت سرعة الخسارة بطيئة للغاية ، فقد ترغب في زيادة lr .
نحن هنا نقوم بمقارنة LM-LSTM-CRF مع النماذج الحديثة الحديثة على مجموعة بيانات CONLL 2000 ، ومجموعة بيانات CONLL 2003 NER ، وجزء WSJ من مجموعة بيانات وضع علامة PTB POS. يتم إجراء جميع التجارب على GPU GTX 1080.
تم العثور على خطأ خطير في وظيفة bioes_to_span في التنفيذ الأصلي ، يرجى إحالة الأرقام التالية كأداء دقيق.
عندما يتم تدريب النماذج فقط على جزء WSJ من مجموعة بيانات وضع علامات PTB POS ، يتم تلخيص النتائج على النحو التالي.
| نموذج | ماكس (ACC) | يعني (ACC) | STD (ACC) | الوقت (ح) |
|---|---|---|---|---|
| LM-LSTM-CRF | 91.35 | 91.24 | 0.12 | 4 |
| - الطريق السريع | 90.87 | 90.79 | 0.07 | 4 |
| -المشاركة في التدريب | 91.23 | 90.95 | 0.34 | 2 |
عندما يتم تدريب النماذج فقط على جزء WSJ من مجموعة بيانات وضع علامات PTB POS ، يتم تلخيص النتائج على النحو التالي.
| نموذج | ماكس (ACC) | يعني (ACC) | STD (ACC) | تم الإبلاغ عنها (ACC) | الوقت (ح) |
|---|---|---|---|---|---|
| Lample et al. 2016 | 97.51 | 97.35 | 0.09 | ن/أ | 37 |
| ما وآخرون. 2016 | 97.46 | 97.42 | 0.04 | 97.55 | 21 |
| LM-LSTM-CRF | 97.59 | 97.53 | 0.03 | 16 |
أصدرنا نماذج تدريب مسبقًا على هذه المهام الثلاث. يمكن تنزيل ملف نقطة التفتيش على الروابط التالية. لاحظ أن نموذج NER ونموذج الضبط (قريبًا) يتم تدريبهم على كل من مجموعة التدريب ومجموعة التطوير:
| WSJ-PTB POS العلامات | conll03 ner |
|---|---|
| args | args |
| نموذج | نموذج |
أيضا ، يتم توفير eval_wc.py لتحميل وتشغيل نقاط التفتيش هذه. يمكن الوصول إلى استخدامه بواسطة الأمر python eval_wc.py -h ، ويترد أدناه مثال على الأمر:
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
إلى نص RAW المشروح ، يتم توفير seq_wc.py لتوضيح النص غير المعلن. يمكن الوصول إلى استخدامه بواسطة الأمر python seq_wc.py -h ، ويترد أدناه مثال أمر قيد التشغيل:
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
يشبه تنسيق الإدخال Conll ، ولكن كل سطر مطلوب لاحتواء حقل واحد فقط ، رمز. على سبيل المثال ، يمكن أن يكون ملف الإدخال:
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
والإخراج المقابل هو:
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


