LM LSTM CRF
implemented most features
Überprüfen Sie unser neues NER -Toolkit
Dieses Projekt bietet leistungsstarke Charakter-Kennzeichnungs-Tools für Sequenz-Kennzeichnungen, einschließlich Training, Bewertung und Vorhersage.
Details zu LM-LSTM-CRF können hier zugegriffen werden, und die Implementierung basiert auf der Pytorch-Bibliothek.
Wichtig: In der ursprünglichen Implementierung wurde in der Funktion bioes_to_span ein schwerwiegender Fehler gefunden. Siehe die im Bereich Benchmarks gemeldeten Zahlen als genaue Leistung.
Die Dokumente wären hier verfügbar.
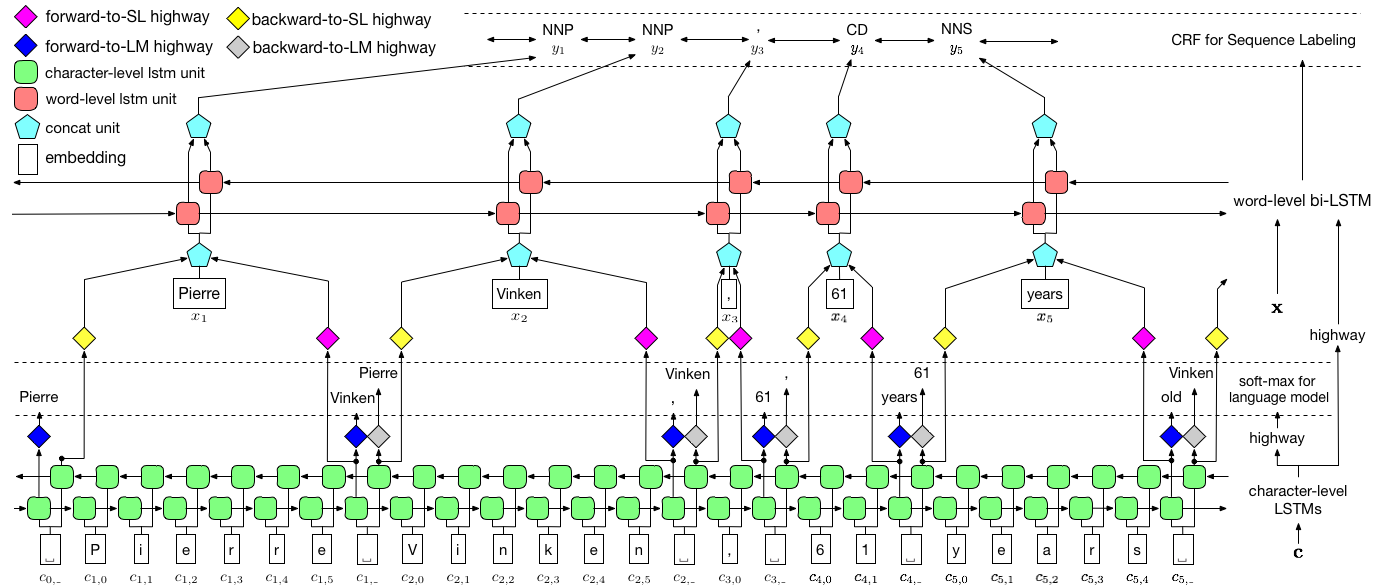
Wie oben visualisiert, verwenden wir das Conditional Random Field (CRF), um Label-Abhängigkeiten zu erfassen, und verwenden eine hierarchische LSTM, um sowohl Eingänge auf Zeichen und Wortebene zu nutzen. Die Struktur auf Char-Level wird weiter von einem Sprachmodell geleitet, während vorgeborene Wort-Einbettungen in Wortebene genutzt werden. Das Sprachmodell und das Sequenzmodellmodell werden gleichzeitig trainiert und machen beide Vorhersagen auf Wortebene. Autobahnnetzwerke werden verwendet, um die Ausgabe von LSTM auf Char-Level in verschiedene semantische Räume zu verwandeln und so diese beiden Aufgaben zu vermitteln und das Sprachmodell zur Stärkung der Sequenzmarkierung zu ermöglichen.
Für das Training wird eine GPU dringend für die Geschwindigkeit empfohlen. CPU wird unterstützt, aber das Training könnte extrem langsam sein.
Der Code basiert auf Pytorch und unterstützt jetzt Pytorch 0.4 . Hier finden Sie Installationsanweisungen.
Der Code ist in Python 3.6 geschrieben. Die Abhängigkeiten sind in der requirements.txt zusammengefasst.txt. Sie können diese Abhängigkeiten wie folgt installieren:
pip3 install -r requirements.txt
Wir konzentrieren uns hauptsächlich auf den NER -Datensatz von Conll 2003, und der Code nimmt sein ursprüngliches Format als Eingabe an. Aufgrund der Lizenzprobleme sind wir jedoch darauf beschränkt, diesen Datensatz zu verteilen. Sie sollten in der Lage sein, es hierher zu bekommen. Möglicherweise möchten Sie auch online suchen (z. B. GitHub), jemand kann es versehentlich veröffentlichen.
Wir gehen davon aus, dass der Korpus so formatiert ist wie der NER -Datensatz von Conll 2003. Insbesondere werden leere Linien als Trennzeichen zwischen den Sätzen verwendet, und das Separator zwischen den Dokumenten ist eine spezielle Zeile wie unten.
-DOCSTART- -X- -X- -X- O
Andere Zeilen enthalten Wörter, Beschriftungen und andere Felder. Das Wort muss das erste Feld sein, mush das letzte und diese Felder werden durch den Raum getrennt . Zum Beispiel sollten die ersten mehrere Zeilen im WSJ -Teil des PTB POS -Tagging -Corpus wie dem folgenden Ausschnitt aussehen.
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
Hier bieten wir Implementierungen für zwei Modelle an, einer ist LM-LSTM-CRF und der andere ist seine Variante LSTM-CRF , die nur die Struktur auf Wortebene und CRF enthält. train_wc.py und eval_wc.py sind Skripte für LM-LSTM-CRF, während train_w.py und eval_w.py Skripte für LSTM-CRF sind. Auf die Verwendung dieser Skripte kann durch den Parameter -h , dh, zugegriffen werden.
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
Die Standardbefehle für NER- und POS -Tagging sowie das NP -Chunking sind:
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
Für andere Datensätze oder Aufgaben möchten Sie möglicherweise verschiedene Stoppparameter ausprobieren, insbesondere für kleinere Datensatz, vielleicht sollten Sie least_iters auf einen größeren Wert einstellen. Und bei einigen Aufgaben möchten Sie möglicherweise lr erhöhen, wenn die Verlustgeschwindigkeit zu langsam ist.
Hier vergleichen wir LM-LSTM-CRF mit aktuellen hochmodernen Modellen im Conll 2000-Chunking-Datensatz, des CONLL 2003-NER-Datensatzes und des WSJ-Teils des PTB POS-Tagging-Datensatzes. Alle Experimente werden an einer GTX 1080 GPU durchgeführt.
In der ursprünglichen Implementierung wurde in der Funktion bioes_to_span ein schwerwiegender Fehler gefunden. Siehe die folgenden Nummern als genaue Leistung.
Wenn Modelle nur im WSJ -Teil des PTB POS -Tagging -Datensatzes trainiert werden, werden die Ergebnisse wie unten zusammengefasst.
| Modell | Max (ACC) | Mittelwert (ACC) | Std (ACC) | Zeit (h) |
|---|---|---|---|---|
| LM-LSTM-CRF | 91.35 | 91.24 | 0,12 | 4 |
| - Autobahn | 90,87 | 90.79 | 0,07 | 4 |
| -Co-Train | 91.23 | 90,95 | 0,34 | 2 |
Wenn Modelle nur im WSJ -Teil des PTB POS -Tagging -Datensatzes trainiert werden, werden die Ergebnisse wie unten zusammengefasst.
| Modell | Max (ACC) | Mittelwert (ACC) | Std (ACC) | Gemeldet (ACC) | Zeit (h) |
|---|---|---|---|---|---|
| Lampe et al. 2016 | 97.51 | 97.35 | 0,09 | N / A | 37 |
| Ma et al. 2016 | 97.46 | 97.42 | 0,04 | 97,55 | 21 |
| LM-LSTM-CRF | 97.59 | 97.53 | 0,03 | 16 |
Wir haben vorgeborene Modelle für diese drei Aufgaben veröffentlicht. Die Checkpoint -Datei kann unter den folgenden Links heruntergeladen werden. Beachten Sie, dass das NER -Modell und das Chunking -Modell (bald in Kürze) sowohl am Trainingssatz als auch am Entwicklungssatz geschult werden:
| WSJ-PTB POS-Tagging | Conll03 ner |
|---|---|
| Args | Args |
| Modell | Modell |
Außerdem wird eval_wc.py zum Laden und Ausführen dieser Kontrollpunkte bereitgestellt. Auf die Verwendung kann durch den Befehl python eval_wc.py -h zugegriffen werden, und ein liefer Befehlsbeispiel ist unten bereitgestellt:
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
Um den rohem Text zu kommentieren, wird seq_wc.py für den nicht annotierten Text zur Verfügung gestellt. Auf die Verwendung kann durch den Befehl python seq_wc.py -h zugegriffen werden, und ein laufendes Befehlsbeispiel wird unten angegeben:
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
Das Eingangsformat ähnelt Conll, aber jede Zeile ist erforderlich, um nur ein Feld zu enthalten. Zum Beispiel könnte eine Eingabedatei sein:
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
und die entsprechende Ausgabe ist:
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


