LM LSTM CRF
implemented most features
새로운 NER 툴킷을 확인하십시오
이 프로젝트는 교육, 평가 및 예측을 포함한 고성능 문자 인식 시퀀스 라벨링 도구를 제공합니다.
LM-LSTM-CRF에 대한 자세한 내용은 여기에서 액세스 할 수 있으며 구현은 Pytorch 라이브러리를 기반으로합니다.
중요 : 원래 구현에서 bioes_to_span 함수에서 심각한 버그가 발견되었습니다. 벤치 마크 섹션에보고 된 숫자를 정확한 성능으로 참조하십시오.
문서는 여기에서 사용할 수 있습니다.
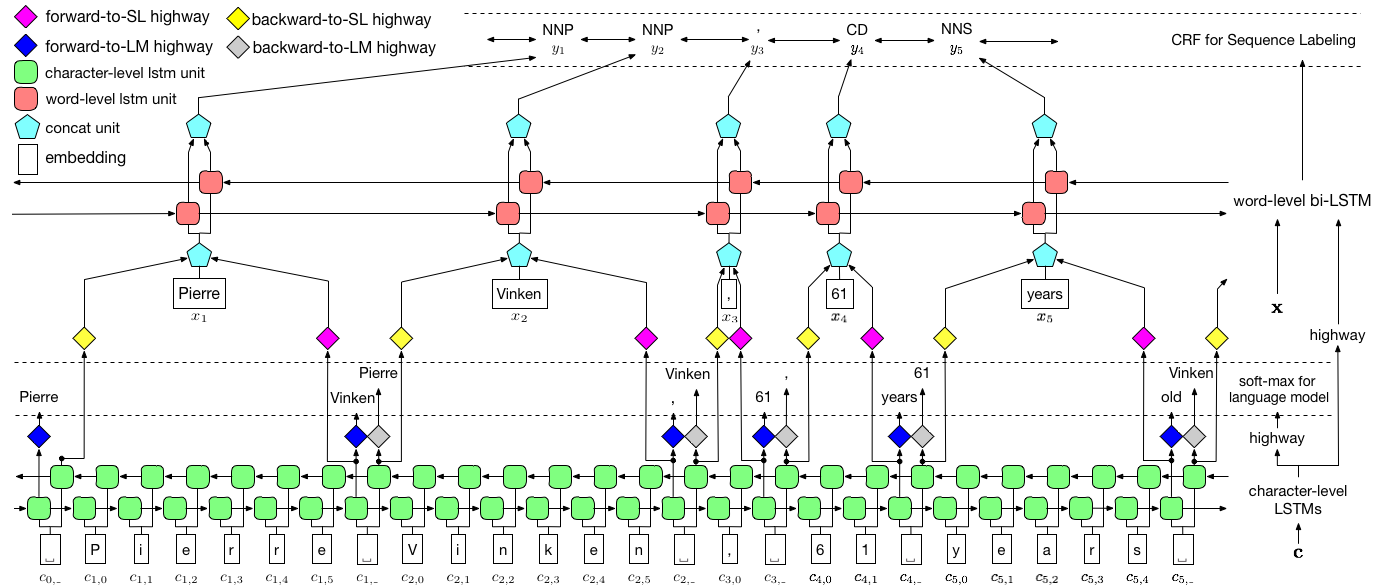
위에서 시각화 한 바와 같이, 우리는 조건부 랜덤 필드 (CRF)를 사용하여 레이블 종속성을 캡처하고 계층 적 LSTM을 채택하여 숯 수준 및 워드 레벨 입력을 모두 활용합니다. char 레벨 구조는 언어 모델에 의해 추가로 유도되는 반면, 미리 훈련 된 단어 임베드는 단어 수준으로 활용됩니다. 언어 모델과 시퀀스 라벨링 모델은 동시에 교육을 받고 단어 수준에서 예측을합니다. 고속도로 네트워크는 숯 LSTM의 출력을 다른 시맨틱 공간으로 변환하는 데 사용되며, 따라서이 두 작업을 중재하고 언어 모델이 시퀀스 라벨링을 권한을 부여 할 수 있습니다.
훈련의 경우 속도에 GPU가 강력히 권장됩니다. CPU가 지원되지만 훈련은 매우 느릴 수 있습니다.
이 코드는 Pytorch를 기반으로하며 Pytorch 0.4를 지원합니다 . 여기에서는 설치 지침을 찾을 수 있습니다.
코드는 Python 3.6으로 작성되었습니다. 의존성은 파일 requirements.txt 에 요약되어 있습니다. 다음과 같이 이러한 종속성을 설치할 수 있습니다.
pip3 install -r requirements.txt
우리는 주로 Conll 2003 NER 데이터 세트에 중점을두고 코드는 원래 형식을 입력으로 가져옵니다. 그러나 라이센스 문제로 인해이 데이터 세트를 배포하도록 제한됩니다. 여기서 얻을 수 있어야합니다. 온라인 (예 : Github)을 검색하고 싶을 수도 있습니다. 누군가 우연히 출시 할 수도 있습니다.
코퍼스는 Conll 2003 NER 데이터 세트와 동일하다고 가정합니다. 보다 구체적으로, 빈 줄은 문장 사이의 구분기로 사용되며 문서 간의 분리기는 다음과 같이 특수 선입니다.
-DOCSTART- -X- -X- -X- O
다른 줄에는 단어, 레이블 및 기타 필드가 포함됩니다. 단어는 첫 번째 필드 여야하고, 레이블 Mush는 마지막 으로,이 필드는 공간으로 분리 됩니다. 예를 들어, PTB POS 태깅 코퍼스의 WSJ 부분에있는 처음 여러 줄은 다음 스 니펫과 같아야합니다.
-DOCSTART- -X- -X- -X- O
Pierre NNP
Vinken NNP
, ,
61 CD
years NNS
old JJ
, ,
will MD
join VB
the DT
board NN
as IN
a DT
nonexecutive JJ
director NN
Nov. NNP
29 CD
. .
여기서 우리는 두 가지 모델에 대한 구현을 제공합니다. 하나는 LM-LSTM-CRF 이고 다른 하나는 변형 인 LSTM-CRF 이며 단어 수준 구조와 CRF 만 포함합니다. train_wc.py 및 eval_wc.py LM-LSTM-CRF의 스크립트이며 train_w.py 및 eval_w.py LSTM-CRF의 스크립트입니다. 이 스크립트의 사용법은 매개 변수 -h , 즉,
python train_wc.py -h
python train_w.py -h
python eval_wc.py -h
python eval_w.py -h
NER 및 POS 태깅의 기본 실행 명령 및 NP 청크는 다음과 같습니다.
python train_wc.py --train_file ./data/ner/train.txt --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt --checkpoint ./checkpoint/ner_ --caseless --fine_tune --high_way --co_train --least_iters 100
python train_wc.py --train_file ./data/pos/train.txt --dev_file ./data/pos/testa.txt --test_file ./data/pos/testb.txt --eva_matrix a --checkpoint ./checkpoint/pos_ --caseless --fine_tune --high_way --co_train
python train_wc.py --train_file ./data/np/train.txt.iobes --dev_file ./data/np/testa.txt.iobes --test_file ./data/np/testb.txt.iobes --checkpoint ./checkpoint/np_ --caseless --fine_tune --high_way --co_train --least_iters 100
다른 데이터 세트 또는 작업의 경우, 특히 작은 데이터 세트의 경우 다른 중지 매개 변수를 시도 할 수 있습니다. least_iters 더 큰 값으로 설정할 수 있습니다. 그리고 일부 작업의 경우 손실 속도 감소 속도가 너무 느리면 lr 늘릴 수 있습니다.
여기서 우리는 LM-LSTM-CRF를 Conll 2000 청킹 데이터 세트, CONLL 2003 NER 데이터 세트 및 PTB POS 태깅 데이터 세트의 WSJ 부분과 최근 최신 모델과 비교합니다. 모든 실험은 GTX 1080 GPU에서 수행됩니다.
원래 구현에서 bioes_to_span 함수에서 심각한 버그가 발견되었습니다. 다음 숫자를 정확한 성능으로 참조하십시오.
PTB POS 태깅 데이터 세트의 WSJ 부분에 대해서만 모델이 교육을 받으면 결과는 다음과 같이 요약됩니다.
| 모델 | 맥스 (ACC) | 평균 (ACC) | STD (ACC) | 시간 (h) |
|---|---|---|---|---|
| LM-LSTM-CRF | 91.35 | 91.24 | 0.12 | 4 |
| - 고속도로 | 90.87 | 90.79 | 0.07 | 4 |
| -공동 훈련 | 91.23 | 90.95 | 0.34 | 2 |
PTB POS 태깅 데이터 세트의 WSJ 부분에 대해서만 모델이 교육을 받으면 결과는 다음과 같이 요약됩니다.
| 모델 | 맥스 (ACC) | 평균 (ACC) | STD (ACC) | 보고 된 (ACC) | 시간 (h) |
|---|---|---|---|---|---|
| Lample et al. 2016 | 97.51 | 97.35 | 0.09 | N/A | 37 |
| Ma et al. 2016 | 97.46 | 97.42 | 0.04 | 97.55 | 21 |
| LM-LSTM-CRF | 97.59 | 97.53 | 0.03 | 16 |
우리는이 세 가지 작업에서 미리 훈련 된 모델을 발표했습니다. Checkpoint 파일은 다음 링크에서 다운로드 할 수 있습니다. NER 모델 및 청크 모델 (곧 출시)은 교육 세트와 개발 세트 모두에서 교육을 받았습니다.
| WSJ-PTB POS 태깅 | conll03 ner |
|---|---|
| args | args |
| 모델 | 모델 |
또한 eval_wc.py 이러한 체크 포인트를로드 및 실행하도록 제공됩니다. 사용법은 python eval_wc.py -h 명령에 의해 액세스 할 수 있으며 실행중인 명령 예제는 다음과 같습니다.
python eval_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --dev_file ./data/ner/testa.txt --test_file ./data/ner/testb.txt
주석이 달린 원시 텍스트를 위해 seq_wc.py 발표되지 않은 텍스트를 주석을 달 수 있도록 제공됩니다. 사용량은 python seq_wc.py -h 명령에 의해 액세스 할 수 있으며, 실행중인 명령 예제는 다음과 같습니다.
python seq_wc.py --load_arg checkpoint/ner/ner_4_cwlm_lstm_crf.json --load_check_point checkpoint/ner_ner_4_cwlm_lstm_crf.model --gpu 0 --input_file ./data/ner2003/test.txt --output_file output.txt
입력 형식은 Conll과 유사하지만 각 라인에는 하나의 필드 인 토큰 만 포함하면됩니다. 예를 들어 입력 파일은 다음과 같습니다.
-DOCSTART-
But
China
saw
their
luck
desert
them
in
the
second
match
of
the
group
,
crashing
to
a
surprise
2-0
defeat
to
newcomers
Uzbekistan
.
그리고 해당 출력은 다음과 같습니다.
-DOCSTART- -DOCSTART- -DOCSTART-
But <LOC> China </LOC> saw their luck desert them in the second match of the group , crashing to a surprise 2-0 defeat to newcomers <LOC> Uzbekistan </LOC> .
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle={AAAI},
year = 2018,
}


