stanford_alpaca
1.0.0

這是斯坦福羊駝項目的回購,該項目旨在建立和分享關注指導型美洲駝的模型。存儲庫包含:
注意:我們感謝社區對斯坦福 - 阿爾帕卡的反饋並支持我們的研究。我們的現場演示被暫停,直到另行通知。
用法和許可聲明:羊駝僅用於研究用途和許可。該數據集由NC 4.0(僅允許非商業用途)為CC,並且不應在研究目的之外使用使用數據集進行培訓的模型。重量差異也是NC 4.0的CC(僅允許非商業用途)。
當前的羊駝模型是從7B Llama模型[1]微調的,該模型[1]在自我教學[2]論文中的技術生成的52K指令遵循數據上進行了微調,並在下一部分中討論了一些修改。在初步的人類評估中,我們發現羊駝7B模型的行為與自我實施指令評估套件上的text-davinci-003模型相似[2]。
羊駝仍在開發中,必須解決許多局限性。重要的是,我們尚未對羊駝模型進行微調安全和無害。因此,我們鼓勵用戶在與羊駝互動時保持謹慎,並報告有關行為的任何行為,以幫助改善模型的安全性和道德考慮。
我們的初始版本包含數據生成過程,數據集和培訓配方。如果我們獲得了Llama的創建者的許可,我們打算釋放模型權重。目前,我們選擇舉辦現場演示,以幫助讀者更好地了解羊駝的功能和限制,以及一種幫助我們更好地評估羊駝在廣泛受眾中的表現的方法。
請閱讀我們的發行博客文章,以了解有關該模型的更多詳細信息,我們對羊駝模型的潛在危害和局限性的討論以及我們發布可再現模型的思維過程。
[1]:美洲駝:開放有效的基礎語言模型。 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. https://arxiv.org/abs/2302.13971v1
[2]:自我建造:將語言模型與自生成指令保持一致。 Yizhong Wang,Yeganeh Kordi,Swaroop Mishra,Alisa Liu,Noah A. Smith,Daniel Khashabi,Hannaneh Hajishirzi。 https://arxiv.org/abs/2212.10560
alpaca_data.json包含我們用於微調羊駝模型的52K指令遵循數據。該JSON文件是字典列表,每個字典包含以下字段:
instruction : str ,描述模型應執行的任務。 52k說明中的每一個都是唯一的。input : str ,可選上下文或任務輸入。例如,當指令是“總結以下文章”時,輸入就是文章。大約40%的示例具有輸入。output : str , text-davinci-003生成的指令的答案。我們使用以下提示來微調羊駝模型:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
在推理期間(例如,用於Web演示),我們將用戶指令與空輸入字段(第二個選項)一起使用。
OPENAI_API_KEY設置為OpenAI API鍵。pip install -r requirements.txt安裝依賴項。python -m generate_instruction generate_instruction_following_data生成數據。我們建立在自我指導的數據生成管道上,並進行了以下修改:
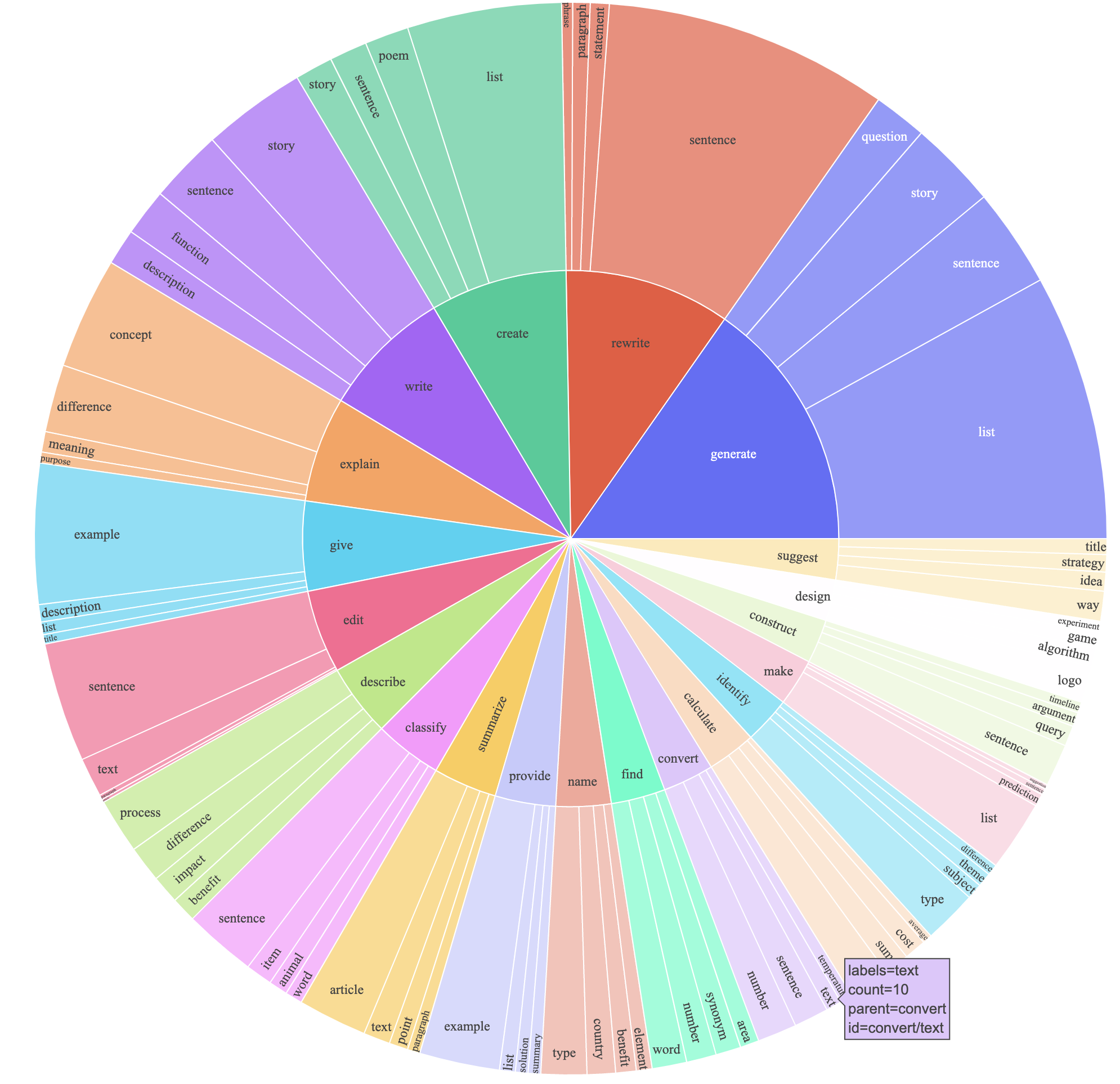
text-davinci-003來生成指令數據,而不是davinci 。prompt.txt ),該提示明確地將指令生成的要求發送給了text-davinci-003 。注意:我們使用的提示中有一個輕微的錯誤,未來的用戶應將編輯合併到#24中這產生了一個以52k示例獲得的指令跟隨數據集,其成本要低得多(低於500美元)。在一項初步研究中,我們還發現我們的52K生成的數據比自我指示發布的數據多得多。我們繪製下圖(以自我教學紙中圖2的樣式以圖2的方式展示了我們數據的多樣性。繪圖的內圓表示指令的根動詞,而外圈表示直接對象。
我們使用標準的擁抱面部訓練代碼微調模型。我們將Llama-7b和Llama-13b微調以下超參數:
| 超參數 | Llama-7b | Llama-13b |
|---|---|---|
| 批量大小 | 128 | 128 |
| 學習率 | 2E-5 | 1E-5 |
| 時代 | 3 | 5 |
| 最大長度 | 512 | 512 |
| 重量衰減 | 0 | 0 |
要重現我們為美洲駝的微調運行,請首先安裝要求
pip install -r requirements.txt以下是在FSDP full_shard模式下使用4 A100 80G GPU的機器上使用我們的數據集微調Llama-7b的命令。我們能夠使用Python 3.10複製與演示中託管的模型相似的模型。 <your_random_port>用自己的端口替換, <your_path_to_hf_converted_llama_ckpt_and_tokenizer>帶有轉換後的檢查點和tokenizer的路徑(PR中的以下說明),以及<your_output_dir> ,以及想要存儲輸出的位置。
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 True同一腳本也適用於選擇微調。這是微調opt-6.7b的示例
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True請注意,給定的培訓腳本旨在簡單易用,並且不是特別優化。要在更多的GPU上運行,您可能更喜歡鍵入gradient_accumulation_steps ,以保持全局批次大小為128。尚未對全局批次大小進行最佳測試。
天真,微調7B模型需要約7 x 4 x 4 = 112 GB的VRAM。上面給出的命令啟用參數碎片,因此在任何GPU上均未存儲冗餘模型副本。如果您想進一步減少內存足跡,這裡有一些選擇:
--fsdp "full_shard auto_wrap offload"打開FSDP的CPU卸載。這樣可以節省VRAM,而運行時間更長。pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 True羊駝-7B和駱駝-7B之間的重量差異在這裡。要恢復原始的羊駝-7b重量,請按照以下步驟:
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
步驟3完成後,您應該有一個帶有恢復權重的目錄,您可以從中加載模型
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )下面的所有研究生均同等貢獻,訂單均由隨機抽籤確定。
所有這些都由Tatsunori B. Hashimoto建議。珀西·梁(Percy Liang)也建議Yann,Carlos Guestrin也建議Xuechen。
如果您在此存儲庫中使用數據或代碼,請引用回購。
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
自然,您還應該引用原始的駱駝紙[1]和自我教學論文[2]。
我們感謝Yizhong Wang在解釋自我教學中的數據生成管道的幫助,並為解析分析圖提供了代碼。我們感謝Yifan Mai的有益支持,Stanford NLP集團以及基礎模型研究中心(CRFM)的成員提供了有益的反饋。


