stanford_alpaca
1.0.0

هذا هو ريبو لمشروع ستانفورد الألباكا ، الذي يهدف إلى بناء ومشاركة نموذج لاما يتبع التعليمات. الريبو يحتوي على:
ملاحظة: نشكر المجتمع على ملاحظات على Stanford-Alpaca ودعم أبحاثنا. يتم تعليق العرض التجريبي المباشر حتى إشعار آخر.
إشعارات الاستخدام والترخيص : الألبكة مخصصة ومرخص للبحث فقط. مجموعة البيانات هي CC بواسطة NC 4.0 (مما يسمح فقط بالاستخدام غير التجاري) ويجب عدم استخدام النماذج المدربة باستخدام مجموعة البيانات خارج أغراض البحث. DEFF للوزن هو أيضا CC بواسطة NC 4.0 (مما يسمح فقط الاستخدام غير التجاري).
يتم ضبط نموذج Alpaca الحالي من نموذج 7B Llama [1] على بيانات متابعة التعليمات 52K التي تم إنشاؤها بواسطة التقنيات في الورقة الذاتية [2] ، مع بعض التعديلات التي نناقشها في القسم التالي. في التقييم الإنساني الأولي ، وجدنا أن نموذج الألبكة 7B يتصرف بشكل مشابه لنموذج text-davinci-003 على جناح تقييم تعليمات البنية الذاتي [2].
الألبكة لا تزال قيد التطوير ، وهناك العديد من القيود التي يجب معالجتها. الأهم من ذلك ، لم ننفذ نموذج الألبكة حتى يكون آمنًا وغير ضار. وبالتالي ، نشجع المستخدمين على توخي الحذر عند التفاعل مع الألبكة ، والإبلاغ عن أي سلوك يتعلق بالمساعدة في تحسين السلامة والاعتبارات الأخلاقية للنموذج.
يحتوي الإصدار الأولي الخاص بنا على إجراء توليد البيانات ومجموعة البيانات وصفة التدريب. نعتزم إطلاق الأوزان النموذجية إذا تم منحنا إذنًا للقيام بذلك من قبل منشئي Llama. في الوقت الحالي ، اخترنا استضافة عرض تجريبي مباشر لمساعدة القراء على فهم قدرات وحدود الألبكة بشكل أفضل ، بالإضافة إلى طريقة لمساعدتنا على تقييم أداء الألباكا بشكل أفضل على جمهور أوسع.
يرجى قراءة منشور مدونة الإصدار لدينا للحصول على مزيد من التفاصيل حول النموذج ، ومناقشتنا حول الضرر والقيود المحتملة لنماذج الألبكة ، وعملية التفكير لدينا لإصدار نموذج قابل للتكرار.
[1]: لاما: نماذج لغة الأساس المفتوحة والفعالة. Hugo Touvron ، Thibaut Lavril ، Gautier Izacard ، Xavier Martinet ، Marie-Anne Lachaux ، Timothée Lacroix ، Baptiste Rozière ، Naman Goyal ، Eric Hambro ، Faisal Azhar ، Aurelien Rodriguez ، Armand Joulin ، Edouard Graint. https://arxiv.org/abs/2302.13971v1
[2]: بنية الذات: مواءمة نموذج اللغة مع تعليمات تم إنشاؤها ذاتيا. Yizhong Wang ، Yeganeh Kordi ، Swaroop Mishra ، Alisa Liu ، Noah A. Smith ، Daniel Khashabi ، Hannaneh Hajishirzi. https://arxiv.org/abs/2212.10560
يحتوي alpaca_data.json على 52 ألف بيانات متابعة للتعليمات التي استخدمناها في صياغة نموذج الألبكة. ملف JSON هذا هو قائمة القواميس ، كل قاموس يحتوي على الحقول التالية:
instruction : str ، يصف المهمة التي يجب أن يؤديها النموذج. كل من تعليمات 52K فريدة من نوعها.input : str ، سياق اختياري أو إدخال للمهمة. على سبيل المثال ، عندما تكون التعليمات "تلخص المقالة التالية" ، فإن المدخلات هي المقالة. حوالي 40 ٪ من الأمثلة لديها مدخلات.output : str ، إجابة التعليمات كما تم إنشاؤها بواسطة text-davinci-003 .استخدمنا المطالبات التالية لضبط نموذج الألبكة:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
أثناء الاستدلال (على سبيل المثال بالنسبة لتوضيح الويب) ، نستخدم تعليمات المستخدم مع حقل إدخال فارغ (الخيار الثاني).
OPENAI_API_KEY على مفتاح Openai API الخاص بك.pip install -r requirements.txt .python -m generate_instruction generate_instruction_following_data لإنشاء البيانات.لقد بنينا على خط أنابيب توليد البيانات من البنية الذاتية وقمنا بالتعديلات التالية:
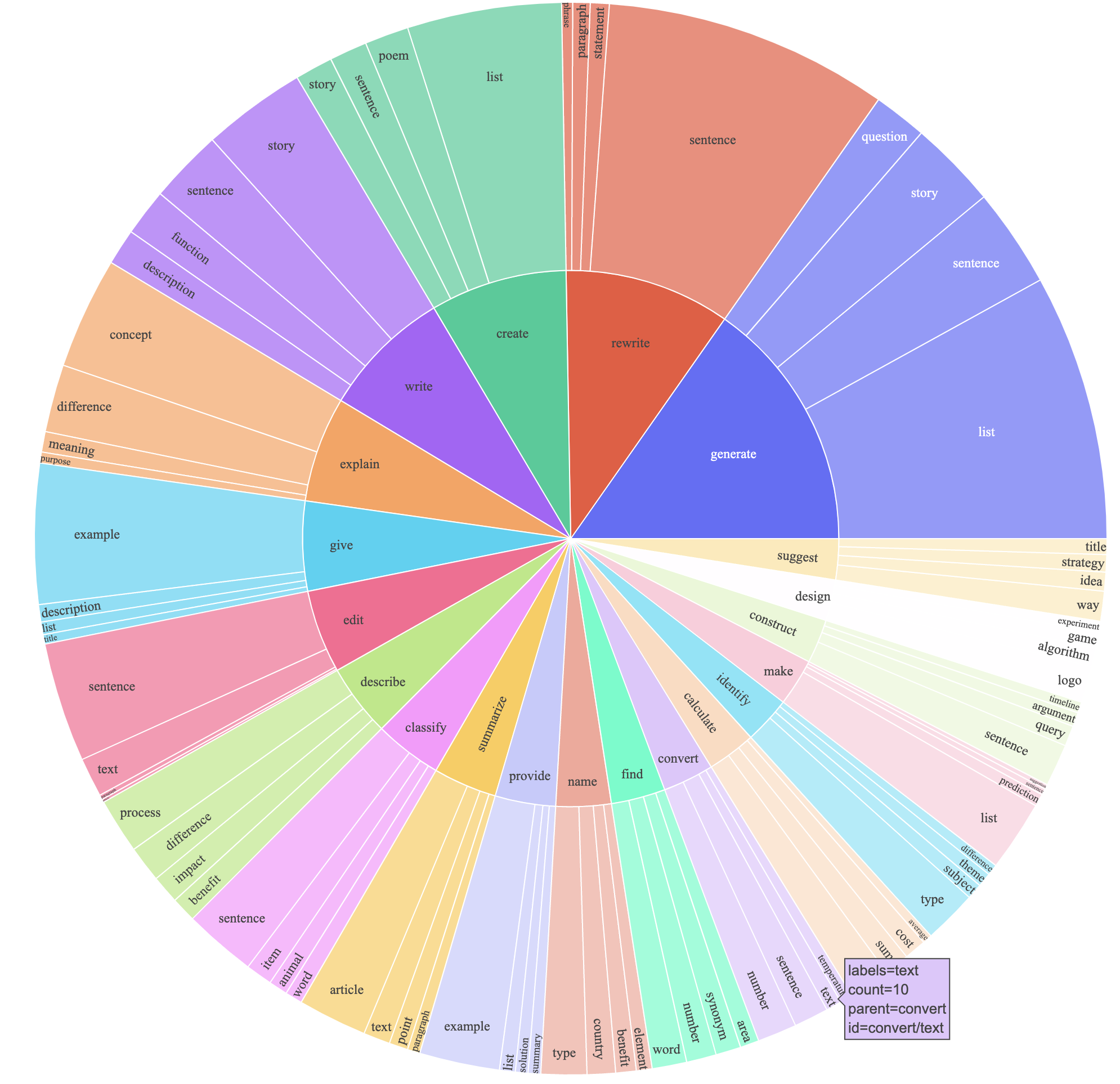
text-davinci-003 لإنشاء بيانات التعليمات بدلاً من davinci .prompt.txt ) أعطى بشكل صريح متطلبات توليد التعليمات إلى text-davinci-003 . ملاحظة: هناك خطأ بسيط في المطالبة التي استخدمناها ، ويجب على المستخدمين في المستقبل دمج التحرير في #24أنتج هذا مجموعة بيانات متابعة التعليمات مع الحصول على 52 ألف أمثلة تم الحصول عليها بتكلفة أقل بكثير (أقل من 500 دولار). في دراسة أولية ، نجد أيضًا أن بياناتنا التي تم إنشاؤها 52 ألفًا أكثر تنوعًا من البيانات الصادرة عن البنية الذاتية. نرسم الشكل أدناه (في نمط الشكل 2 في ورقة التبعية الذاتية لإظهار تنوع بياناتنا. تمثل الدائرة الداخلية للمؤامرة الفعل الجذر للتعليمات ، والدائرة الخارجية تمثل الكائنات المباشرة.
نحن نتحمل طرزنا باستخدام رمز التدريب المعانقة القياسية. نحن نتحمل llama-7b و llama-13b مع فرط البرارامات التالية:
| مقياس البارامير | لاما -7 ب | لاما -13 ب |
|---|---|---|
| حجم الدُفعة | 128 | 128 |
| معدل التعلم | 2E-5 | 1E-5 |
| الحقبة | 3 | 5 |
| الحد الأقصى طول | 512 | 512 |
| انحلال الوزن | 0 | 0 |
لإعادة إنتاج عمليات التثبيت الخاصة بنا لـ Llama ، قم أولاً بتثبيت المتطلبات
pip install -r requirements.txt فيما يلي أمر ينطلق LLAMA-7B مع مجموعة البيانات الخاصة بنا على جهاز مع 4 A100 80G وحدات معالجة الرسومات في وضع FSDP full_shard . تمكنا من إعادة إنتاج نموذج ذي جودة مماثلة حيث استضفناها في العرض التوضيحي مع الأمر التالي باستخدام Python 3.10 . استبدل <your_random_port> بمنفذ خاص بك ، <your_path_to_hf_converted_llama_ckpt_and_tokenizer> بالمسار إلى نقطة التفتيش المحولة والرمز المميز (بعد الإرشادات في العلاقات العامة) ، و <your_output_dir> مع مكان تخزين مخرجاتك.
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 Trueنفس البرنامج النصي يعمل أيضًا للاختراف. إليك مثال على صقل OPT-6.7B
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True لاحظ أن البرنامج النصي التدريبي المعطى هو بسيط وسهل الاستخدام ، وليس تحسينه بشكل خاص. لتشغيل المزيد من وحدات معالجة الرسومات ، قد تفضل رفض gradient_accumulation_steps للحفاظ على حجم الدفعة العالمي 128. لم يتم اختبار حجم الدُفعة العالمية لتحقيق الأمثل.
بسذاجة ، يتطلب صقل طراز 7B حوالي 7 × 4 × 4 = 112 جيجابايت من VRAM. الأوامر المذكورة أعلاه تمكين Sharding ، لذلك لا يتم تخزين نسخة نموذجية زائدة على أي وحدة معالجة الرسومات. إذا كنت ترغب في تقليل بصمة الذاكرة ، فإليك بعض الخيارات:
--fsdp "full_shard auto_wrap offload" . هذا يوفر VRAM على حساب وقت التشغيل الأطول.pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 Trueيوجد فرق الوزن بين الألباكا -7 ب و LLAMA-7B هنا. لاستعادة أوزان الألباكا -7B الأصلية ، اتبع هذه الخطوات:
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
بمجرد اكتمال الخطوة 3 ، يجب أن يكون لديك دليل مع الأوزان المستردة ، والتي يمكنك من خلالها تحميل النموذج مثل ما يلي
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )ساهم جميع طلاب الدراسات العليا أدناه بالتساوي ويتم تحديد الطلب عن طريق السحب العشوائي.
كل نصح من قبل Tatsunori B. Hashimoto. ينصح يان من قبل بيرسي ليانغ و Xuechen ينصحه كارلوس غوسترين أيضًا.
يرجى الاستشهاد بالربط إذا كنت تستخدم البيانات أو الرمز في هذا الريبو.
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
وبطبيعة الحال ، يجب أن تستشهد أيضًا بورقة Llama الأصلية [1] وورقة البنية الذاتية [2].
نشكر Yizhong Wang على مساعدته في شرح خط أنابيب توليد البيانات في البنية الذاتية وتقديم الكود لمؤامرة تحليل Parse. نشكر Yifan Mai على الدعم المفيد ، وأعضاء مجموعة Stanford NLP وكذلك مركز الأبحاث حول نماذج الأساس (CRFM) على ملاحظاتهم المفيدة.


