stanford_alpaca
1.0.0

이것은 Stanford Alpaca Project의 리포지토리이며, 이는 LLAMA 모델을 구축하고 공유하는 것을 목표로합니다. repo에는 다음이 포함됩니다.
참고 : Stanford-Alpaca에 대한 피드백과 연구 지원에 대한 커뮤니티에 감사드립니다. 우리의 라이브 데모는 추가 통지가 될 때까지 정지됩니다.
사용 및 라이센스 통지 : Alpaca는 연구 용도로만 의도되고 라이센스가 부여됩니다. 데이터 세트는 NC 4.0의 CC (비상업적 사용 만 허용)이며 데이터 세트를 사용하여 훈련 된 모델은 연구 목적 외부에서 사용해서는 안됩니다. 중량 차이는 또한 NC 4.0에 의해 CC입니다 (비상업적 사용 만 허용).
현재의 Alpaca 모델은 자체 비율 [2] 논문의 기술에 의해 생성 된 52k 명령을 따르는 데이터에 대한 7B LLAMA 모델 [1]에서 미세 조정되어 있으며 다음 섹션에서 논의 할 수있는 일부 수정입니다. 예비 인간 평가에서, 우리는 Alpaca 7B 모델이 자체 강조 명령어 추종 평가 스위트에 대한 text-davinci-003 모델과 유사하게 행동한다는 것을 발견했다 [2].
Alpaca는 여전히 개발 중이며 해결해야 할 많은 제한 사항이 있습니다. 중요하게도, 우리는 아직 Alpaca 모델을 안전하고 무해하게 조정하지 않았습니다. 따라서 우리는 알파카와 상호 작용할 때 사용자가주의를 기울이고 모델의 안전 및 윤리적 고려 사항을 개선하는 데 도움이되는 행동에 관한 모든 행동을보고하도록 권장합니다.
초기 릴리스에는 데이터 생성 절차, 데이터 세트 및 교육 레시피가 포함되어 있습니다. 우리는 LLAMA 제작자가 그렇게 할 수있는 권한을 부여하면 모델 가중치를 발표 할 계획입니다. 현재, 우리는 독자들이 알파카의 기능과 한계를 더 잘 이해하고 더 넓은 청중에 대한 Alpaca의 성능을 더 잘 평가할 수 있도록 독자들이 라이브 데모를 주최하기로 결정했습니다.
모델에 대한 자세한 내용, 알파카 모델의 잠재적 인 피해 및 한계에 대한 논의 및 재현 가능한 모델을 공개하기위한 사고 과정에 대한 자세한 내용은 릴리스 블로그 게시물을 읽으십시오.
[1] : llama : 개방적이고 효율적인 기초 언어 모델. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. https://arxiv.org/abs/2302.13971v1
[2] : 자체 강조 : 언어 모델을 자체 생성 지침과 정렬합니다. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi. https://arxiv.org/abs/2212.10560
alpaca_data.json 에는 Alpaca 모델을 미세 조정하는 데 사용한 52k 명령어 버전 데이터가 포함되어 있습니다. 이 JSON 파일은 사전 목록이며 각 사전은 다음 필드를 포함합니다.
instruction : str , 모델이 수행 해야하는 작업을 설명합니다. 52k 지침 각각은 독특합니다.input : str , 선택적 컨텍스트 또는 작업에 대한 입력. 예를 들어, 명령이 "다음 기사를 요약"하면 입력은 기사입니다. 예제의 약 40%에 입력이 있습니다.output : str , text-davinci-003 에 의해 생성 된 지시에 대한 답.Alpaca 모델을 미세 조정하기 위해 다음과 같은 프롬프트를 사용했습니다.
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
추론 (예 : 웹 데모의 경우) 동안 빈 입력 필드 (두 번째 옵션)와 함께 사용자 명령어를 사용합니다.
OPENAI_API_KEY OpenAI API 키로 설정하십시오.pip install -r requirements.txt 사용하여 종속성을 설치하십시오.python -m generate_instruction generate_instruction_following_data 실행하여 데이터를 생성합니다.우리는 자체 강조에서 데이터 생성 파이프 라인을 구축하고 다음과 같은 수정을했습니다.
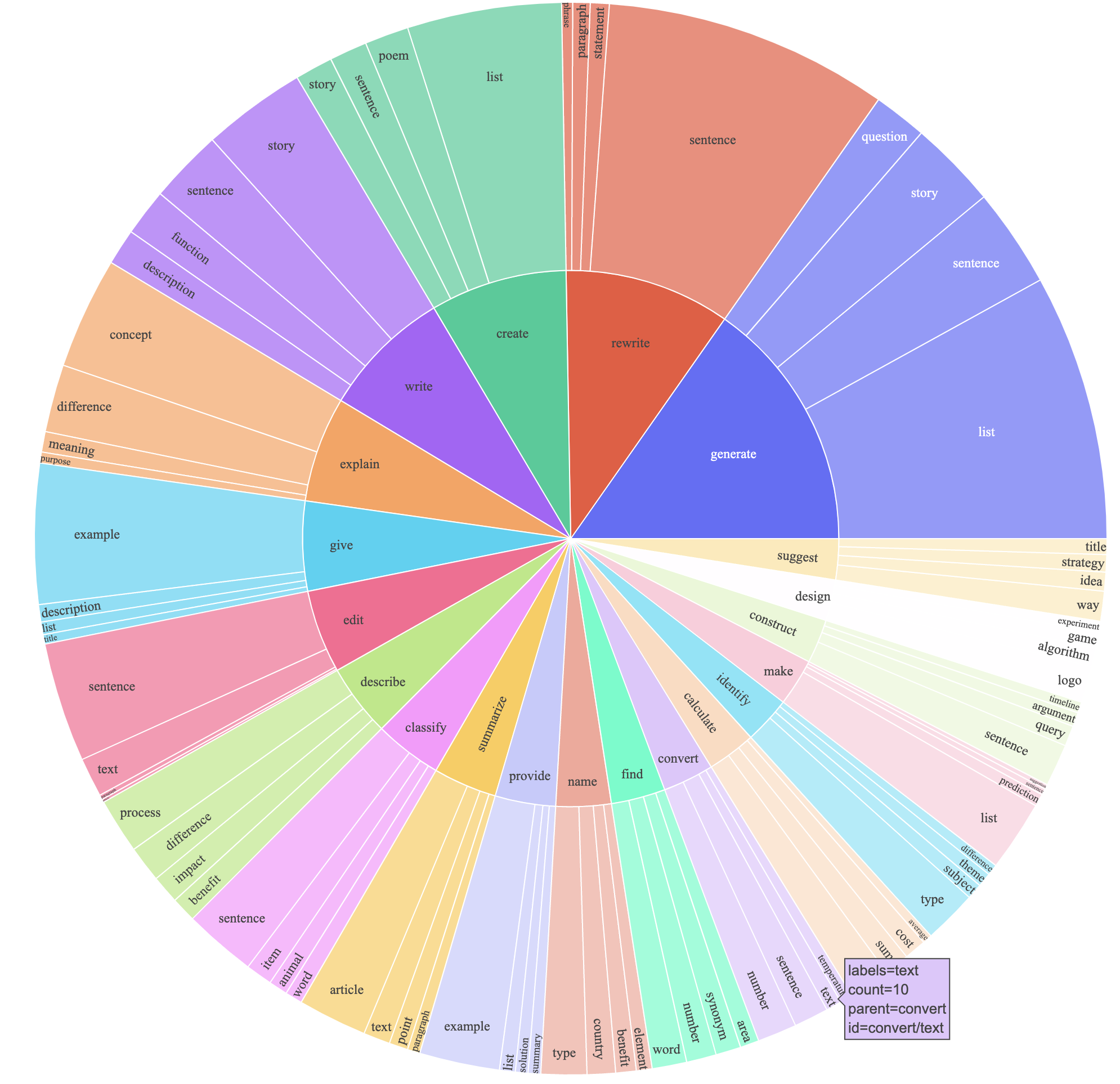
davinci 대신 지침 데이터를 생성하기 위해 text-davinci-003 사용했습니다.text-davinci-003 에 명시 적으로 제공 한 새로운 프롬프트 ( prompt.txt )를 썼습니다. 참고 : 우리가 사용한 프롬프트에는 약간의 오류가 있으며 향후 사용자는 #24에 편집을 통합해야합니다.이로 인해 훨씬 저렴한 비용 (500 달러 미만)으로 52k 예제가 포함 된 지시를 따르는 데이터 세트를 생성했습니다. 예비 연구에서, 우리는 또한 52K 생성 데이터가 자체 강조에 의해 발표 된 데이터보다 훨씬 다양하다는 것을 발견했습니다. 우리는 아래 그림 (데이터의 다양성을 보여주기 위해 자체 강조 용지의 그림 2 스타일로 그림 2의 스타일로 플롯의 내부 원은 지침의 루트 동사를 나타내고 외부 원은 직접 객체를 나타냅니다.
표준 포옹 얼굴 훈련 코드를 사용하여 모델을 미세 조정합니다. 우리는 다음과 같은 하이퍼 파라미터로 llama-7b 및 llama-13b를 미세 조정합니다.
| 초 파라미터 | llama-7b | llama-13b |
|---|---|---|
| 배치 크기 | 128 | 128 |
| 학습 속도 | 2E-5 | 1E-5 |
| 에포크 | 3 | 5 |
| 최대 길이 | 512 | 512 |
| 체중 부패 | 0 | 0 |
Llama의 미세 조정 실행을 재현하려면 먼저 요구 사항을 설치하십시오.
pip install -r requirements.txt 다음은 FSDP full_shard 모드에 4 A100 80g GPU가있는 컴퓨터의 데이터 세트와 함께 LLAMA-7B를 미세 조정하는 명령입니다. Python 3.10을 사용하여 다음 명령으로 데모에서 호스팅 한 것과 유사한 품질의 모델을 재현 할 수있었습니다. <your_random_port> 자신의 포트로 바꾸십시오 <your_path_to_hf_converted_llama_ckpt_and_tokenizer> 변환 된 체크 포인트 및 토큰 화기 (PR의 지침에 따른)로가는 경로로, 출력을 저장하려는 <your_output_dir> 로 바꾸십시오.
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 True동일한 스크립트도 선택한 미세 조정에도 작동합니다. 다음은 미세 조정 OPT-6.7B의 예입니다
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True 주어진 교육 스크립트는 간단하고 사용하기 쉽고 특히 최적화되지 않습니다. 더 많은 GPU를 실행하려면 gradient_accumulation_steps 낮추기 위해 글로벌 배치 크기를 128로 유지하는 것이 좋습니다. 글로벌 배치 크기는 최적 성능에 대해 테스트되지 않았습니다.
순진하게, 7b 모델을 미세 조정하려면 약 7 x 4 x 4 = 112GB의 VRAM이 필요합니다. 위에 주어진 명령은 파라미터 샤딩을 활성화하므로 중복 모델 사본은 모든 GPU에 저장되지 않습니다. 메모리 풋 프린트를 더 줄이려면 몇 가지 옵션이 있습니다.
--fsdp "full_shard auto_wrap offload" 로 FSDP 용 CPU 오프로드를 켜십시오. 이렇게하면 더 긴 런타임 비용으로 VRAM이 절약됩니다.pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 TrueAlpaca-7b와 Llama-7b의 중량 차이는 여기에 있습니다. 원래의 Alpaca-7b 무게를 복구하려면 다음을 수행하십시오.
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
3 단계가 완료되면 회복 된 가중치가있는 디렉토리가 있어야하며, 여기에서 다음과 같은 모델을로드 할 수 있습니다.
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )아래의 모든 대학원생은 동일하게 기여했으며 주문은 무작위 추첨에 의해 결정됩니다.
Tatsunori B. Hashimoto가 조언합니다. Yann은 또한 Percy Liang의 조언을 받고 있으며 Xuechen은 Carlos Guestrin도 조언합니다.
이 repo에서 데이터 또는 코드를 사용하는 경우 저장소를 인용하십시오.
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
당연히, 당신은 또한 원래 라마 논문 [1]과 자체 강조 논문 [2]을 인용해야합니다.
우리는 자체 강조의 데이터 생성 파이프 라인을 설명하고 구문 분석 플롯 코드를 제공하는 데 도움을 준 Yizhong Wang에게 감사드립니다. 유용한 지원에 대해 Yifan Mai와 Stanford NLP 그룹의 회원뿐만 아니라 유용한 피드백에 대해 Foundation Models (CRFM) 센터에 감사드립니다.


