stanford_alpaca
1.0.0

Este é o repositório do projeto Stanford Alpaca, que visa construir e compartilhar um modelo de lhama que segue instruções. O repo contém:
Nota: Agradecemos à comunidade pelo feedback sobre Stanford-Alpaca e apoiando nossa pesquisa. Nossa demonstração ao vivo é suspensa até novo aviso.
Avisos de uso e licença : a Alpaca é destinada e licenciada apenas para uso em pesquisa. O conjunto de dados é CC pelo NC 4.0 (permitindo apenas uso não comercial) e os modelos treinados usando o conjunto de dados não devem ser usados fora dos fins de pesquisa. O diferencial de peso também é CC por NC 4.0 (permitindo apenas uso não comercial).
O modelo atual da ALPACA é ajustado a partir de um modelo de llama 7B [1] em dados que seguem os dados que seguem de instrução gerados pelas técnicas no artigo de auto-estrutura [2], com algumas modificações que discutimos na próxima seção. Em uma avaliação humana preliminar, descobrimos que o modelo ALPACA 7B se comporta de maneira semelhante ao modelo text-davinci-003 no conjunto de avaliação que segue a instrução de auto-estrutura [2].
A Alpaca ainda está em desenvolvimento e há muitas limitações que devem ser abordadas. É importante ressaltar que ainda não ajustamos o modelo de alpaca para ser seguro e inofensivo. Assim, incentivamos os usuários a serem cautelosos ao interagir com a Alpaca e a relatar qualquer comportamento preocupante para ajudar a melhorar as considerações éticas e de segurança do modelo.
Nossa versão inicial contém o procedimento de geração de dados, o conjunto de dados e a receita de treinamento. Pretendemos liberar os pesos do modelo se tivermos permissão para fazê -lo pelos criadores da llama. Por enquanto, optamos por sediar uma demonstração ao vivo para ajudar os leitores a entender melhor as capacidades e limites da Alpaca, bem como uma maneira de nos ajudar a avaliar melhor o desempenho da Alpaca em um público mais amplo.
Leia nossa postagem no blog de lançamento para obter mais detalhes sobre o modelo, nossa discussão sobre os possíveis danos e limitações dos modelos Alpaca e nosso processo de pensamento para liberar um modelo reproduzível.
[1]: LLAMA: Modelos de linguagem de fundação abertos e eficientes. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Jouland Joulin, Faisal Azhar, Aurelien Rodriguez, Jouland Joulin, Faisal Azhar, Aurelien Rodriguez, Jouland Joulin, Faisal Azhar, Aurelien Rodriguez, Jouland Joulin, Faisal Azhar, Aurelien Rodriguez, Jouland Joulin, Faisal Azhar, Aurelien Rodriguez, Jouland Joulin, Faisal Azhar, Aurelien Rodriguez, Jouland Joulin, Edou Azar, Aurelien Rodriguez, Joulin. https://arxiv.org/abs/2302.13971v1
[2]: Auto-instrução: alinhando o modelo de linguagem com instruções auto-geradas. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi. https://arxiv.org/abs/2212.10560
alpaca_data.json contém 52k de seguidores de instruções que usamos para ajustar o modelo Alpaca. Este arquivo json é uma lista de dicionários, cada dicionário contém os seguintes campos:
instruction : str , descreve a tarefa que o modelo deve executar. Cada uma das instruções de 52k é única.input : str , contexto opcional ou entrada para a tarefa. Por exemplo, quando a instrução é "resumir o artigo a seguir", a entrada é o artigo. Cerca de 40% dos exemplos têm uma entrada.output : str , a resposta para a instrução gerada pelo text-davinci-003 .Usamos os seguintes prompts para ajustar o modelo de alpaca:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
Durante a inferência (por exemplo, a demonstração da web), usamos a instrução do usuário com um campo de entrada vazio (segunda opção).
OPENAI_API_KEY para sua chave de API OpenAI.pip install -r requirements.txt .python -m generate_instruction generate_instruction_following_data para gerar os dados.Construímos o pipeline de geração de dados a partir da auto-estrutura e fizemos as seguintes modificações:
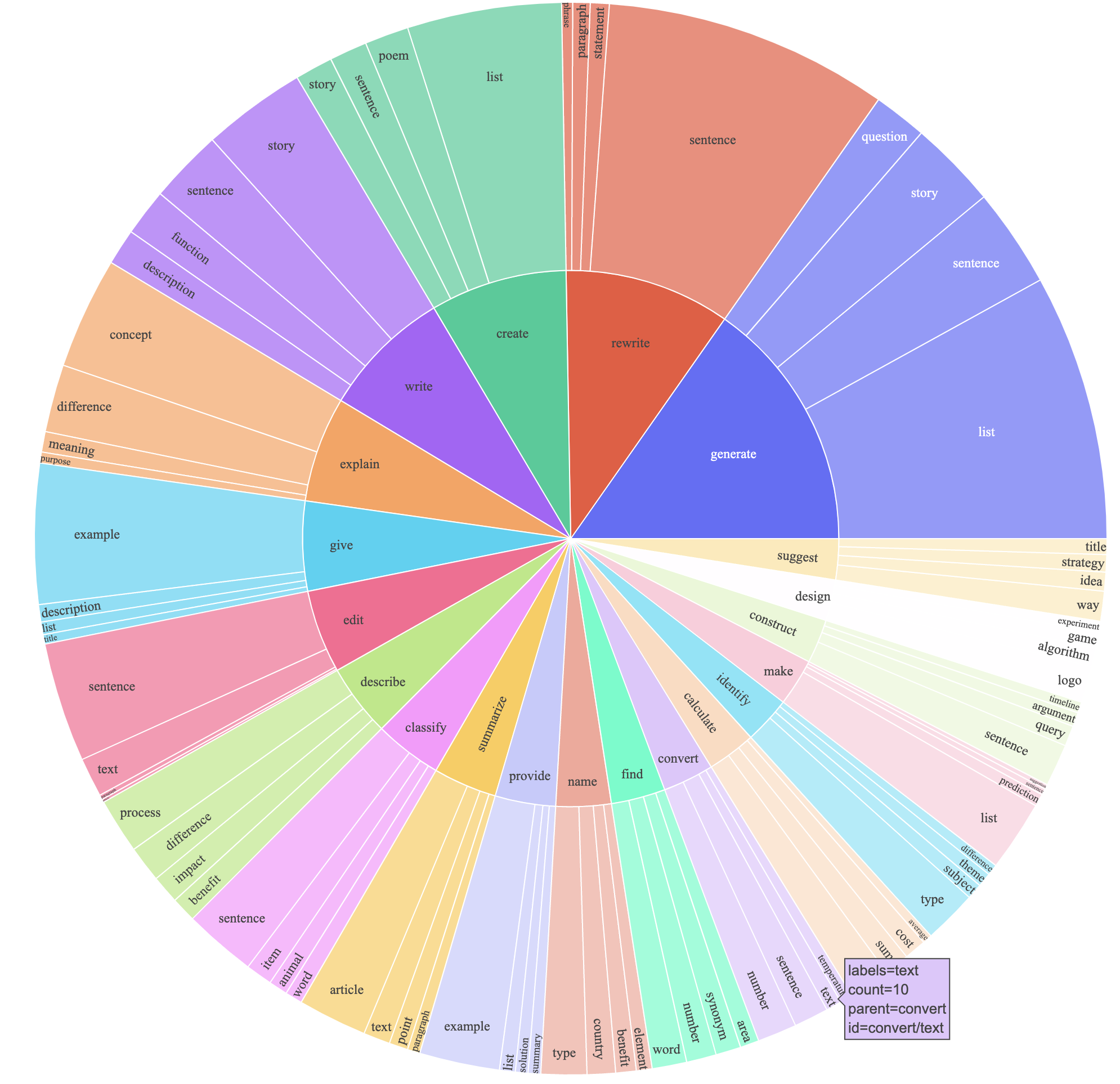
text-davinci-003 para gerar os dados de instruções em vez de davinci .prompt.txt ) que deu explicitamente o requisito de geração de instruções para text-davinci-003 . NOTA: Há um pequeno erro no prompt que usamos, e futuros usuários devem incorporar a edição no #24Isso produziu um conjunto de dados que segue a instrução com 52k exemplos obtidos a um custo muito menor (menos de US $ 500). Em um estudo preliminar, também achamos que nossos 52k geraram dados muito mais diversos do que os dados divulgados pela auto-estrutura. Plotamos a figura abaixo (no estilo da Figura 2 no papel de auto-estrutura para demonstrar a diversidade de nossos dados. O círculo interno do gráfico representa o verbo raiz das instruções e o círculo externo representa os objetos diretos.
Nós ajustamos nossos modelos usando o código de treinamento de face de abraço padrão. Nós tune tune llama-7b e llama-13b com os seguintes hiperparâmetros:
| Hiperparâmetro | Llama-7b | LLAMA-13B |
|---|---|---|
| Tamanho do lote | 128 | 128 |
| Taxa de aprendizado | 2E-5 | 1e-5 |
| Épocas | 3 | 5 |
| Comprimento máximo | 512 | 512 |
| Decaimento de peso | 0 | 0 |
Para reproduzir nossas execuções de ajuste fino para a llama, primeiro instale os requisitos
pip install -r requirements.txt Abaixo está um comando que fino tunes llama-7b com nosso conjunto de dados em uma máquina com 4 GPUs A100 80g no modo FSDP full_shard . Conseguimos reproduzir um modelo de qualidade semelhante ao que hospedamos em nossa demonstração com o seguinte comando usando o Python 3.10 . Substitua <your_random_port> por uma porta própria, <your_path_to_hf_converted_llama_ckpt_and_tokenizer> com o caminho para o seu ponto de verificação convertido e o tokenizer (seguindo as instruções no PR) e <your_output_dir> por onde você deseja armazenar suas saídas.
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 TrueO mesmo script também funciona para optar o ajuste fino. Aqui está um exemplo para o ajuste fino opt-6.7b
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True Observe que o script de treinamento fornecido deve ser simples e fácil de usar e não é particularmente otimizado. Para executar mais GPUs, você pode preferir recusar gradient_accumulation_steps para manter um tamanho global de 128 anos. O tamanho do lote global não foi testado quanto à otimização.
Ingênuo, ajuste fino Um modelo 7b requer cerca de 7 x 4 x 4 = 112 GB de VRAM. Os comandos fornecidos acima Ativam o sharding do parâmetro, portanto, nenhuma cópia do modelo redundante é armazenada em qualquer GPU. Se você deseja reduzir ainda mais a pegada da memória, aqui estão algumas opções:
--fsdp "full_shard auto_wrap offload" . Isso salva o VRAM ao custo de tempo de execução mais longo.pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 TrueO diferencial de peso entre o ALPACA-7B e o LLAMA-7B está localizado aqui. Para recuperar os pesos originais da ALPACA-7B, siga estas etapas:
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
Depois que a etapa 3 é concluída, você deve ter um diretório com os pesos recuperados, dos quais você pode carregar o modelo como o seguinte
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )Todos os estudantes de graduação abaixo contribuíram igualmente e o pedido é determinado pelo sorteio aleatório.
Tudo aconselhado por Tatsunori B. Hashimoto. Yann também é aconselhado por Percy Liang e Xuechen também é aconselhado por Carlos Guestrin.
Cite o repositório se você usar os dados ou código neste repositório.
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
Naturalmente, você também deve citar o papel de llama original [1] e o artigo de auto-estrutura [2].
Agradecemos a Yizhong Wang por sua ajuda para explicar o pipeline de geração de dados na auto-estrutura e fornecer o código para o gráfico de análise Parse. Agradecemos a Yifan Mai pelo apoio útil e aos membros do Grupo Stanford NLP, bem como ao Center for Research on Foundation Models (CRFM) por seu feedback útil.


