stanford_alpaca
1.0.0

Ceci est le dépôt du projet Alpaca Stanford, qui vise à construire et à partager un modèle LLAMA suivant les instructions. Le repo contient:
Remarque: Nous remercions la communauté pour les commentaires sur Stanford-Alpaca et soutenons nos recherches. Notre démo en direct est suspendue jusqu'à nouvel ordre.
Avis d'utilisation et de licence : l'alpaga est destiné et conçue pour une utilisation de la recherche uniquement. L'ensemble de données est CC par NC 4.0 (ne permettant qu'une utilisation non commerciale) et les modèles formés à l'aide de l'ensemble de données ne doivent pas être utilisés en dehors des fins de recherche. Le difficulté de poids est également CC par NC 4.0 (ne permettant qu'une utilisation non commerciale).
Le modèle ALPACA actuel est affiné à partir d'un modèle LLAMA 7B [1] sur des données de suivi des instructions 52k générées par les techniques du papier auto-instructeur [2], avec quelques modifications dont nous discutons dans la section suivante. Dans une évaluation humaine préliminaire, nous avons constaté que le modèle Alpaca 7B se comporte de la même manière que le modèle text-davinci-003 sur la suite d'évaluation de suivi de l'instruction d'auto-instruction [2].
L'Alpaga est toujours en cours de développement et il y a de nombreuses limitations qui doivent être abordées. Surtout, nous n'avons pas encore affiné le modèle alpaga pour être sûr et inoffensif. Nous encourageons donc les utilisateurs à être prudents lors de l'interaction avec l'alpaga et à signaler tout comportement concernant pour améliorer la sécurité et les considérations éthiques du modèle.
Notre version initiale contient la procédure de génération de données, l'ensemble de données et la recette de formation. Nous avons l'intention de libérer les poids du modèle si nous avons la permission de le faire par les créateurs de Llama. Pour l'instant, nous avons choisi d'organiser une démo en direct pour aider les lecteurs à mieux comprendre les capacités et les limites de l'alpaga, ainsi qu'un moyen de nous aider à mieux évaluer les performances d'Alpaga sur un public plus large.
Veuillez lire notre article de blog de version pour plus de détails sur le modèle, notre discussion sur les dommages potentiels et les limites des modèles alpaga et notre processus de réflexion pour publier un modèle reproductible.
[1]: LLAMA: modèles de langue de base ouverts et efficaces. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. https://arxiv.org/abs/2302.13971v1
[2]: Auto-instructeur: Alignez le modèle de langue avec des instructions auto-générées. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi. https://arxiv.org/abs/2212.10560
alpaca_data.json contient des données de suivi de l'instruction 52k que nous avons utilisées pour affiner le modèle alpaca. Ce fichier JSON est une liste de dictionnaires, chaque dictionnaire contient les champs suivants:
instruction : str , décrit la tâche que le modèle doit effectuer. Chacune des instructions 52k est unique.input : str , contexte facultatif ou entrée pour la tâche. Par exemple, lorsque l'instruction est "Résumez l'article suivant", l'entrée est l'article. Environ 40% des exemples ont une entrée.output : str , la réponse à l'instruction générée par text-davinci-003 .Nous avons utilisé les invites suivantes pour affiner le modèle alpaga:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
Pendant l'inférence (par exemple pour la démo Web), nous utilisons l'instruction utilisateur avec un champ de saisie vide (deuxième option).
OPENAI_API_KEY sur votre clé API OpenAI.pip install -r requirements.txt .python -m generate_instruction generate_instruction_following_data pour générer les données.Nous avons construit sur le pipeline de génération de données à partir de l'auto-instruction et apporté les modifications suivantes:
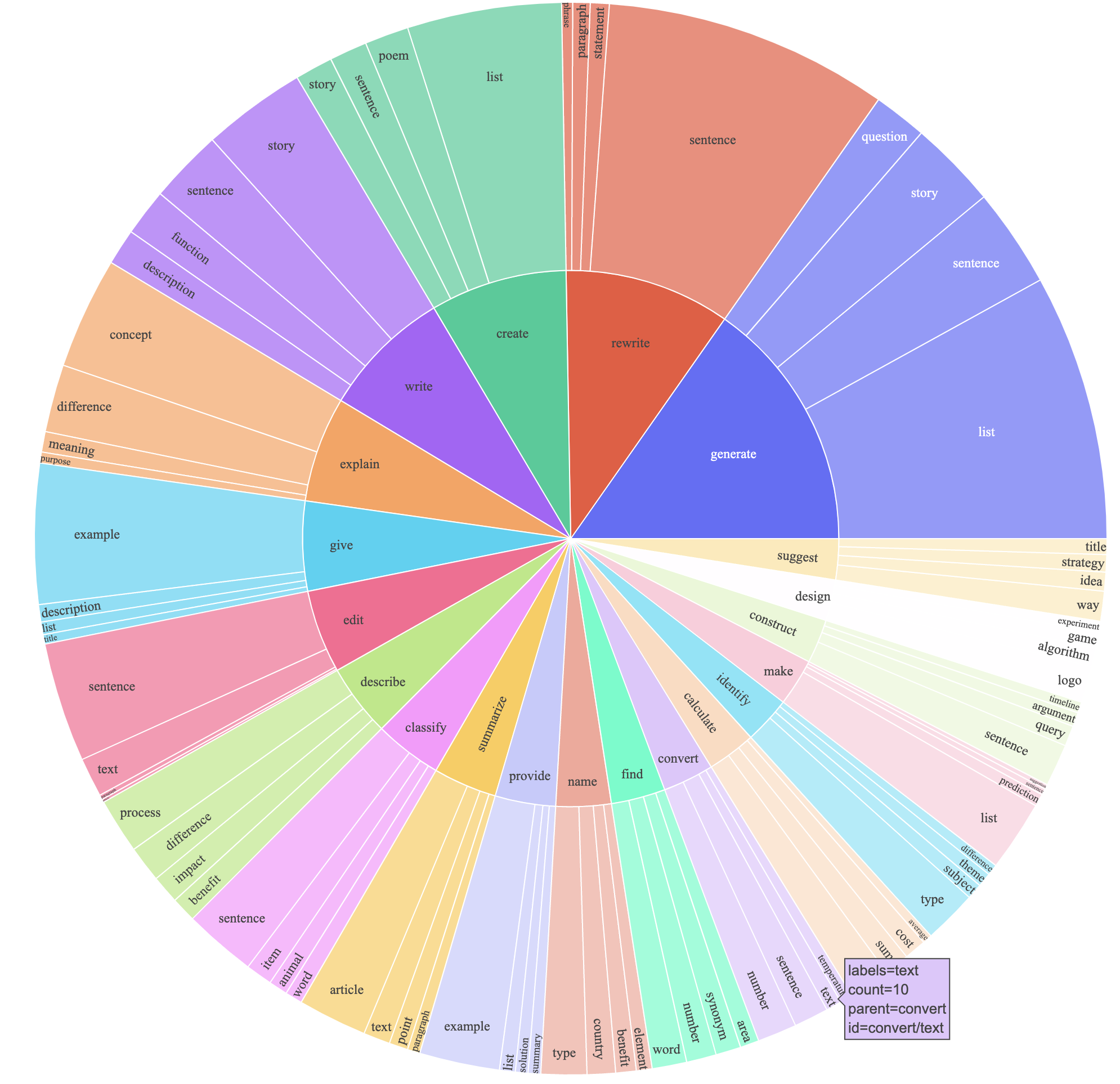
text-davinci-003 pour générer les données d'instructions au lieu de davinci .prompt.txt ) qui a explicitement donné l'exigence de génération d'instructions à text-davinci-003 . Remarque: il y a une légère erreur dans l'invite que nous avons utilisée, et les futurs utilisateurs devraient incorporer le montage dans # 24Cela a produit un ensemble de données suivant les instructions avec 52k exemples obtenus à un coût beaucoup plus faible (moins de 500 $). Dans une étude préliminaire, nous constatons également que nos données générées par 52k sont beaucoup plus diverses que les données publiées par l'auto-instruction. Nous traçons la figure ci-dessous (dans le style de la figure 2 dans le papier d'auto-instruction pour démontrer la diversité de nos données. Le cercle intérieur du tracé représente le verbe racine des instructions, et le cercle extérieur représente les objets directs.
Nous affinons nos modèles en utilisant le code de formation en visage standard. Nous affinons LLAMA-7B et LLAMA-13B avec les hyperparamètres suivants:
| Hyperparamètre | Lama-7b | Lama-13b |
|---|---|---|
| Taille de lot | 128 | 128 |
| Taux d'apprentissage | 2E-5 | 1E-5 |
| Époques | 3 | 5 |
| Longueur maximale | 512 | 512 |
| Décomposition du poids | 0 | 0 |
Pour reproduire nos courses de réglage fin pour Llama, installez d'abord les exigences
pip install -r requirements.txt Vous trouverez ci-dessous une commande selon laquelle Fine Tunes Llama-7b avec notre ensemble de données sur une machine avec 4 GPU A100 80G en mode FSDP full_shard . Nous avons pu reproduire un modèle de qualité similaire à celui que nous avons hébergé dans notre démo avec la commande suivante en utilisant Python 3.10 . Remplacez <your_random_port> par votre propre port, <your_path_to_hf_converted_llama_ckpt_and_tokenizer> par le chemin de votre point de contrôle converti et de votre tokenizer (les instructions suivantes dans le PR), et <your_output_dir> par où vous souhaitez stocker vos sorties.
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 TrueLe même script fonctionne également pour le réglage fin OPT. Voici un exemple pour le réglage fin OPT-6.7B
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True Remarque Le script d'entraînement donné est destiné à être simple et facile à utiliser, et n'est pas particulièrement optimisé. Pour fonctionner sur plus de GPU, vous préférez peut-être refuser gradient_accumulation_steps pour conserver une taille de lot globale de 128. La taille globale du lot n'a pas été testée pour l'optimalité.
Naïvement, le réglage fin d'un modèle 7b nécessite environ 7 x 4 x 4 = 112 Go de VRAM. Les commandes indiquées ci-dessus permettent de permettre le paramètre, de sorte qu'aucune copie de modèle redondante n'est stockée sur un GPU. Si vous souhaitez réduire davantage l'empreinte de la mémoire, voici quelques options:
--fsdp "full_shard auto_wrap offload" . Cela permet d'économiser VRAM au prix d'un temps d'exécution plus long.pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 TrueLe poids diff entre alpaca-7b et llama-7b est situé ici. Pour récupérer les poids d'alpaca-7b d'origine, suivez ces étapes:
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
Une fois l'étape 3 terminée, vous devriez avoir un répertoire avec les poids récupérés, à partir de laquelle vous pouvez charger le modèle comme celui qui suit
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )Tous les étudiants diplômés ci-dessous ont contribué également et l'ordre est déterminé par un tirage aléatoire.
Tous avisés par Tatsunori B. Hashimoto. Yann est également conseillé par Percy Liang et Xuechen est également conseillé par Carlos Guestrin.
Veuillez citer le dépôt si vous utilisez les données ou le code dans ce dépôt.
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
Naturellement, vous devez également citer le papier lama d'origine [1] et le papier d'auto-instruction [2].
Nous remercions Yizhong Wang pour son aide à expliquer le pipeline de génération de données dans l'auto-instruction et à fournir le code pour le tracé d'analyse de l'analyse. Nous remercions Yifan Mai pour son soutien utile et les membres du groupe NLP de Stanford ainsi que le Center for Research on Foundation Models (CRFM) pour leurs commentaires utiles.


