stanford_alpaca
1.0.0

Dies ist das Repo für das Stanford Alpaca Project, das darauf abzielt, ein Lama-Modell für Anweisungen zu erstellen und zu teilen. Das Repo enthält:
Hinweis: Wir danken der Community für Feedback zu Stanford-Alpaca und der Unterstützung unserer Forschung. Unsere Live -Demo wird bis zu weiteren Ankündigung suspendiert.
Nutzungs- und Lizenzbenachrichtigungen : Alpaka ist nur für die Verwendung von Forschungen beabsichtigt und lizenziert. Der Datensatz ist CC von NC 4.0 (so dass nur nicht kommerzielle Verwendung verwendet werden kann) und Modelle, die mit dem Datensatz trainiert werden, sollten nicht außerhalb der Forschungszwecke verwendet werden. Der Gewichtsdiff beträgt auch CC von NC 4.0 (so dass nur nicht kommerzielle Verwendung verwendet wird).
Das aktuelle Alpaka-Modell stimmt aus einem 7B-Lama-Modell [1] auf 52K-Anweisungsdaten ab, die durch die Techniken im Self-Struktur-Papier erstellt wurden, mit einigen Änderungen, die wir im nächsten Abschnitt diskutieren. In einer vorläufigen menschlichen Bewertung stellten wir fest, dass sich das Alpaca 7B-Modell ähnlich wie das text-davinci-003 -Modell für die Bewertung der Selbststrukturanweisung verhalten [2].
Alpaka befindet sich noch in der Entwicklung, und es gibt viele Einschränkungen, die angegangen werden müssen. Wichtig ist, dass wir das Alpaka-Modell noch nicht geschafft haben, um sicher und harmlos zu sein. Wir ermutigen die Benutzer daher, bei der Interaktion mit Alpaka vorsichtig zu sein und über ein Verhalten zu berichten, um die Sicherheits- und ethischen Überlegungen des Modells zu verbessern.
Unsere erste Version enthält das Datenerzeugungsverfahren, das Datensatz und das Trainingsrezept. Wir beabsichtigen, die Modellgewichte freizugeben, wenn wir die Erlaubnis dazu erhalten, dies von den Schöpfer von Lama zu tun. Im Moment haben wir uns für eine Live -Demo entschieden, um den Lesern zu helfen, die Fähigkeiten und Grenzen von Alpaka besser zu verstehen, sowie eine Möglichkeit, die Leistung von Alpaca bei einem breiteren Publikum besser zu bewerten.
Bitte lesen Sie unseren Release -Blog -Beitrag für weitere Informationen zum Modell, unsere Diskussion über den potenziellen Schaden und die Einschränkungen von Alpaca -Modellen und unseren Denkprozess zur Veröffentlichung eines reproduzierbaren Modells.
[1]: LAMA: Offene und effiziente Fundament -Sprachmodelle. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguz, Armand Joulin, Edouard, Edouard, Edouard, Edouard, Edouard, Edouard, Edouard, Guillaume, Guillaum Lama, Guillumel. https://arxiv.org/abs/2302.13971v1
[2]: Selbststruktur: Sprachmodell mit selbst erzeugten Anweisungen ausrichten. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi. https://arxiv.org/abs/2212.10560
alpaca_data.json enthält 52K-Anweisungen, die wir zur Feinabstimmung des Alpaka-Modells verwendet haben. Diese JSON -Datei ist eine Liste von Wörterbüchern. Jedes Wörterbuch enthält die folgenden Felder:
instruction : str , beschreibt die Aufgabe, die das Modell ausführen sollte. Jede der 52K -Anweisungen ist einzigartig.input : str , optionaler Kontext oder Eingabe für die Aufgabe. Wenn beispielsweise die Anweisung "den folgenden Artikel zusammenfassen" lautet, ist die Eingabe der Artikel. Rund 40% der Beispiele haben einen Eingang.output : str , die Antwort auf die von text-davinci-003 generierte Anweisung.Wir haben die folgenden Eingabeaufforderungen zur Feinabstimmung des Alpaka-Modells verwendet:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
Während der Inferenz (z. B. für die Web -Demo) verwenden wir den Benutzeranweisungen mit einem leeren Eingabefeld (zweite Option).
OPENAI_API_KEY auf Ihren OpenAI -API -Schlüssel.pip install -r requirements.txt .python -m generate_instruction generate_instruction_following_data aus, um die Daten zu generieren.Wir basieren auf der Datenerzeugungspipeline aus dem Selbststruktur und nahmen die folgenden Änderungen vor:
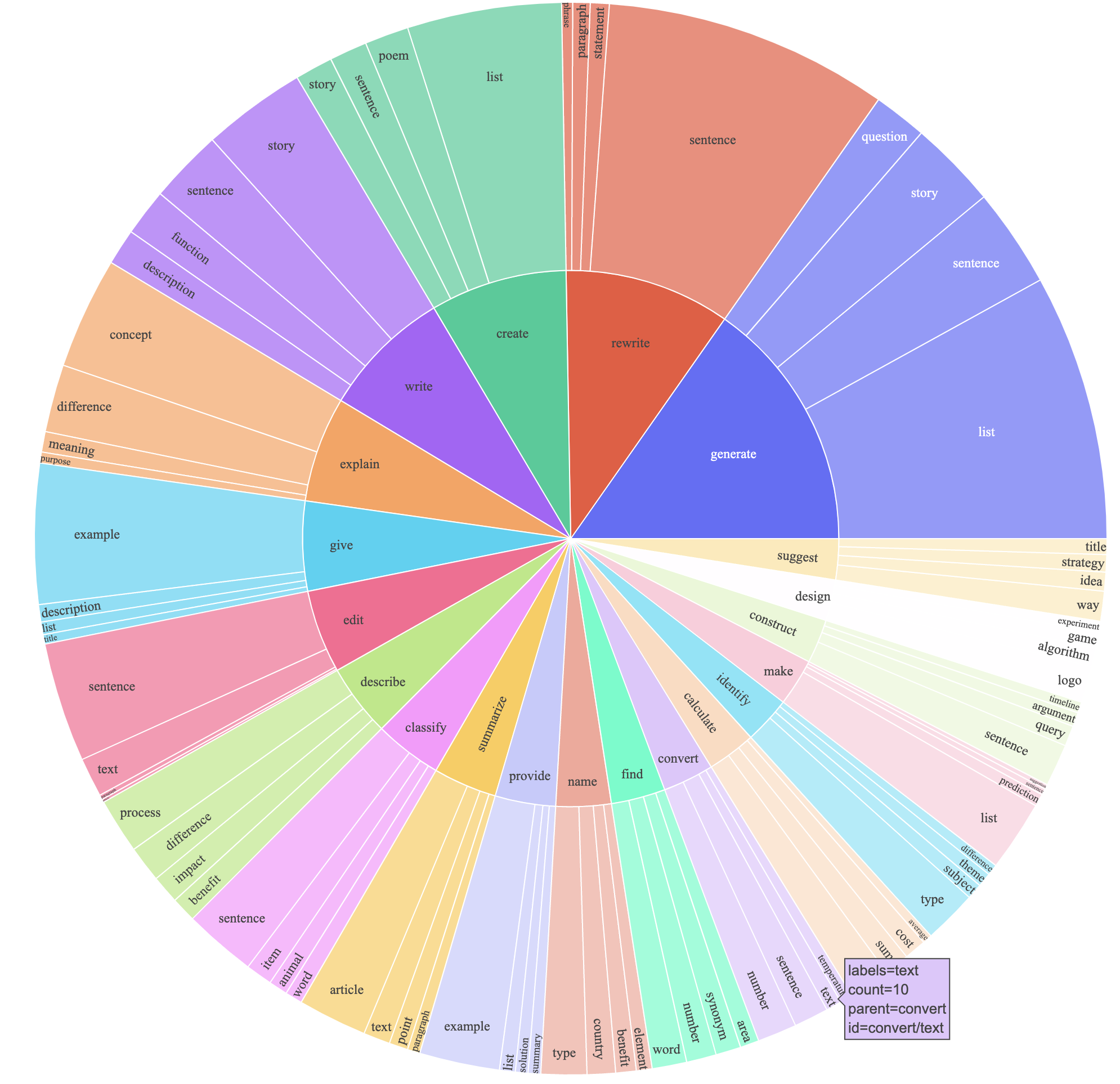
text-davinci-003 verwendet, um die Anweisungsdaten anstelle von davinci zu generieren.prompt.txt ) geschrieben, die text-davinci-003 ausdrücklich die Erfordernis der Anweisungsgenerierung ergab. HINWEIS: Die Eingabeaufforderung, die wir verwendetenDies erzeugte einen Anweisungsverfolgungsdatensatz mit 52K-Beispielen, die zu viel niedrigeren Kosten (weniger als 500 US-Dollar) erhalten wurden. In einer vorläufigen Studie finden wir auch, dass unsere 52K-generierten Daten viel vielfältiger sind als die durch das Selbstversorgungsstaat freigegebenen Daten. Wir zeichnen die folgende Abbildung auf (im Stil von Abbildung 2 im Self-Strukturpapier, um die Vielfalt unserer Daten zu demonstrieren. Der innere Kreis des Diagramms repräsentiert das Wurzelverb der Anweisungen, und der äußere Kreis repräsentiert die direkten Objekte.
Wir stimmen unsere Modelle mit Standard-Umarmungs-Gesichts-Trainingscode gut ab. Wir haben Lama-7b und Lama-13b mit den folgenden Hyperparametern gut abgestimmen:
| Hyperparameter | Lama-7b | LAMA-13B |
|---|---|---|
| Chargengröße | 128 | 128 |
| Lernrate | 2E-5 | 1e-5 |
| Epochen | 3 | 5 |
| Maximale Länge | 512 | 512 |
| Gewichtsverfall | 0 | 0 |
Um unsere Feinabstimmungsläufe für Lama zu reproduzieren, installieren Sie zuerst die Anforderungen
pip install -r requirements.txt Im Folgenden finden Sie einen Befehl, den Fine-Tunes LLAMA-7B mit unserem Datensatz auf einer Maschine mit 4 A100 80G GPUs im FSDP full_shard Modus. Wir konnten ein Modell von ähnlicher Qualität reproduzieren wie das, das wir in unserer Demo mit dem folgenden Befehl mit Python 3.10 veranstalteten. Ersetzen Sie <your_random_port> durch einen eigenen Port, <your_path_to_hf_converted_llama_ckpt_and_tokenizer> mit dem Pfad zu Ihrem konvertierten Checkpoint und Tokenizer (folgende Anweisungen in der PR) sowie <your_output_dir> mit dem, wo Sie Ihre Ausgabe speichern möchten.
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 TrueDas gleiche Skript eignet sich auch für Opt-Fine-Tuning. Hier ist ein Beispiel für die Feinabstimmung opt-6.7b
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True Beachten Sie, dass das angegebene Trainingsskript einfach und einfach zu bedienen ist und nicht besonders optimiert ist. Um mehr GPUs zu betreiben, bevorzugen Sie möglicherweise die globale gradient_accumulation_steps von 128.
Naiv erfordert die Feinabstimmung eines 7B-Modells etwa 7 x 4 x 4 = 112 GB VRAM. Die oben angegebenen Befehle ermöglichen Parameter Sharding, sodass keine redundante Modellkopie für eine GPU gespeichert wird. Wenn Sie den Speicher Fußabdruck weiter reduzieren möchten, finden Sie hier einige Optionen:
--fsdp "full_shard auto_wrap offload" ein. Dies spart VRAM auf Kosten längerer Laufzeit.pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 TrueDer Gewichtsdiff zwischen ALPACA-7B und LAMA-7B befindet sich hier. Befolgen Sie die folgenden Schritte, um die ursprünglichen Alpaca-7b-Gewichte wiederherzustellen:
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
Sobald Schritt 3 abgeschlossen ist, sollten Sie ein Verzeichnis mit den wiederhergestellten Gewichten haben, aus dem Sie das Modell wie das folgende laden können
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )Alle folgenden Studierenden haben gleichermaßen beigetragen und die Reihenfolge wird durch zufällige Ziehung bestimmt.
Alles von Tatsunori B. Hashimoto beraten. Yann wird auch von Percy Liang beraten und Xuechen wird auch von Carlos Guestrin beraten.
Bitte zitieren Sie das Repo, wenn Sie die Daten oder den Code in diesem Repo verwenden.
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
Natürlich sollten Sie auch das ursprüngliche Lama-Papier [1] und das Selbststrukturpapier [2] zitieren.
Wir danken Yizhong Wang für seine Hilfe bei der Erläuterung der Datenerzeugungspipeline im Selbststruktur und zur Bereitstellung des Code für das Parse-Analyse-Diagramm. Wir danken Yifan Mai für die hilfreiche Unterstützung und Mitglieder der Stanford NLP Group sowie des Center for Research on Foundation Models (CRFM) für ihr hilfreiches Feedback.


