stanford_alpaca
1.0.0

Это репо для проекта Стэнфордской альпаки, целью которого является создание и поделиться моделью Llama, посвященной инструкциям. Репо содержит:
Примечание: мы благодарим сообщество за отзыв о Стэнфорде-Альпаке и поддержке наших исследований. Наша живая демонстрация приостановлена до дальнейшего уведомления.
Уведомления об использовании и лицензии : Alpaca предназначена и лицензирована только для исследования. Набор данных CC по NC 4.0 (разрешающий только некоммерческое использование), и модели, обученные с использованием набора данных, не должны использоваться вне целей исследования. Веса дифференциала также является CC по NC 4.0 (позволяя только некоммерческому использованию).
Текущая модель Alpaca точно настроена на модель LLAMA 7B [1] на 52K данных, посвященных инструкциям, генерируемым методами в бумаге для самостоятельной конструкции [2], с некоторыми модификациями, которые мы обсуждаем в следующем разделе. В предварительной оценке человека мы обнаружили, что модель Alpaca 7B ведет себя аналогично модели text-davinci-003 в наборе оценки, посвященной инструкциям, посвященной инструкциям [2].
Альпака все еще находится в стадии разработки, и есть много ограничений, которые необходимо решить. Важно отметить, что мы еще не настроили модель альпаки, чтобы быть безопасной и безвредной. Таким образом, мы призываем пользователей быть осторожными при взаимодействии с Alpaca, и сообщать о любом поведении, чтобы помочь повысить безопасность и этические соображения модели.
Наш первоначальный выпуск содержит процедуру генерации данных, набор данных и учебный рецепт. Мы намерены выпустить веса модели, если нам дано разрешение сделать это создателями ламы. На данный момент мы решили провести живую демонстрацию, чтобы помочь читателям лучше понять возможности и пределы Alpaca, а также способ помочь нам лучше оценить производительность Alpaca на более широкой аудитории.
Пожалуйста, прочитайте наш релиз в блоге для более подробной информации о модели, нашем обсуждении потенциального вреда и ограничений моделей Alpaca и нашего мыслительного процесса для выпуска воспроизводимой модели.
[1]: Лама: открытые и эффективные языковые модели фундамента. Хьюго Тувророн, Тибо Лаврил, Готье Изакард, Ксавье Мартинет, Мари-Энн Лахау, Тимот-Лакруа, Баптист Розьер, Наман Гоял, Эрик Хамбру, Файсал Ажар, Аурелен Родригес, Арманд Джулин, Эдуард Грейв, Гуиллу, Аурелиен Родригес, Арманд Джулин, Эдуард Грейв. https://arxiv.org/abs/2302.13971v1
[2]: Самоубийство: Выравнивающая языковая модель с самого сгенерированными инструкциями. Йижонг Ван, Йегане Корди, Сваруп Мишра, Алиса Лю, Ноа А. Смит, Даниэль Хашаби, Ханнане Хаджисирзи. https://arxiv.org/abs/2212.10560
alpaca_data.json содержит 52K данных, посвященных инструкциям, которые мы использовали для тонкой настройки модели Alpaca. Этот файл JSON представляет собой список словарей, каждый словарь содержит следующие поля:
instruction : str , описывает задачу, которую должна выполнять модель. Каждая из 52 -километровых инструкций уникальна.input : str , необязательный контекст или ввод для задачи. Например, когда инструкция является «суммируйте следующую статью», ввод - это статья. Около 40% примеров имеют вход.output : str , ответ на инструкцию, созданную text-davinci-003 .Мы использовали следующие подсказки для тонкой настройки модели альпаки:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
Во время вывода (например, для веб -демонстрации) мы используем пользовательскую инструкцию с пустым полем ввода (второй вариант).
OPENAI_API_KEY на ваш ключ API OpenAI.pip install -r requirements.txt .python -m generate_instruction generate_instruction_following_data , чтобы генерировать данные.Мы построили на конвейере генерации данных из самостоятельной конструкции и внесли следующие модификации:
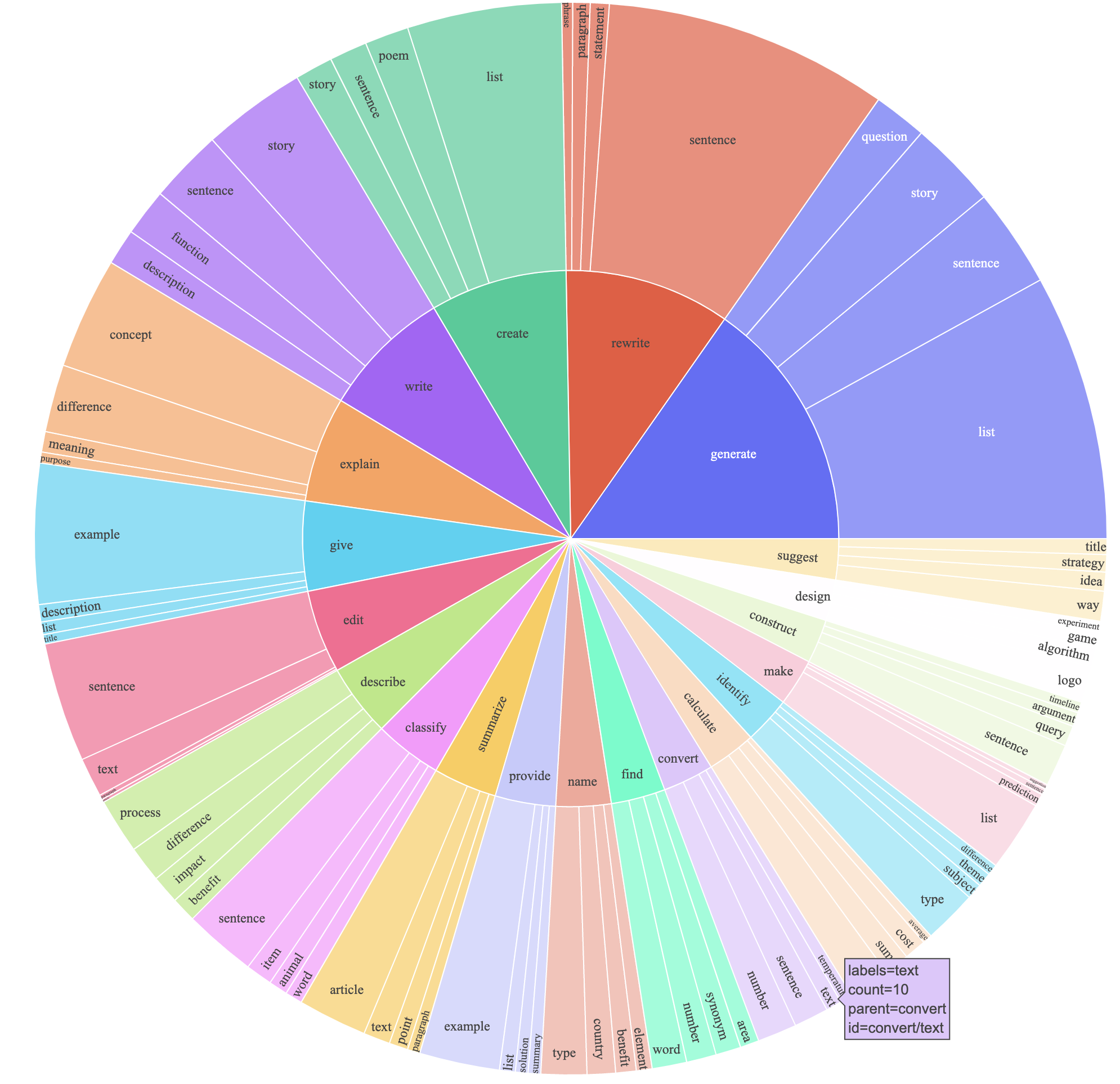
text-davinci-003 для генерации данных инструкции вместо davinci .prompt.txt ), которая явно дала требование генерации инструкций для text-davinci-003 . Примечание. В использованной нами приглашении есть небольшая ошибка, и будущие пользователи должны включить редактирование в #24Это создало набор данных, посвященный инструкции с 52K примерами, полученными по гораздо меньшей стоимости (менее 500 долларов США). В предварительном исследовании мы также считаем, что наши 52K-сгенерированные данные были гораздо более разнообразными, чем данные, опубликованные в результате самостоятельной конструкции. Мы планируем рисунок ниже (в стиле рисунка 2 в бумаге для самостоятельной конструкции, чтобы продемонстрировать разнообразие наших данных. Внутренний круг графика представляет собой корневой глагол инструкций, а внешний круг представляет прямые объекты.
Мы настраиваем наши модели, используя стандартный код обучения обнимающего лица. Мы настраиваем Llama-7b и Llama-13b со следующими гиперпараметрами:
| Гиперпараметр | Лама-7B | Лама-13b |
|---|---|---|
| Размер партии | 128 | 128 |
| Скорость обучения | 2E-5 | 1e-5 |
| Эпохи | 3 | 5 |
| Максимальная длина | 512 | 512 |
| Распад веса | 0 | 0 |
Чтобы воспроизвести наши финальные прогоны для Llama, сначала установите требования
pip install -r requirements.txt Ниже приведена команда, которая тонко настраивает Llama-7B с нашим набором данных на машине с 4 A100 80G GPU в режиме FSDP full_shard . Мы смогли воспроизвести модель такого же качества, что и то, что мы размещали в нашей демонстрации со следующей командой, используя Python 3.10 . Замените <your_random_port> на собственный порт, <your_path_to_hf_converted_llama_ckpt_and_tokenizer> С помощью пути к конвертированной контрольной точке и токенизатора (следующие инструкции в PR) и <your_output_dir> с тем, где вы хотите сохранить свои выходы.
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 TrueТот же сценарий также работает для точной настройки OPT. Вот пример для точной настройки Opt-6.7b
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True Обратите внимание, что данный тренировочный скрипт предназначен для того, чтобы быть простым и простым в использовании, и не особенно оптимизирован. Чтобы запустить больше графических процессоров, вы можете предпочесть отказаться от gradient_accumulation_steps , чтобы сохранить глобальный размер партии 128. Глобальный размер партии не был проверен на оптимальность.
Наивно, тонкая настройка модели 7b требует около 7 x 4 x 4 = 112 ГБ VRAM. Команды, приведенные выше, включают параметры Sharding, поэтому избыточная копия модели не хранится ни на одном графическом процессоре. Если вы хотите еще больше уменьшить площадь памяти, вот несколько вариантов:
--fsdp "full_shard auto_wrap offload" . Это экономит VRAM за счет более длительного времени выполнения.pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 TrueВеса между альпака-7B и Llama-7B расположена здесь. Чтобы восстановить исходные веса Alpaca-7B, выполните следующие действия:
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
Как только шаг 3 завершится, у вас должен быть каталог с восстановленными весами, из которых вы можете загрузить модель, как следующее
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )Все аспиранты ниже внесли свой вклад в равной степени, и порядок определяется случайным рисованием.
Все посоветовано Татсунори Б. Хасимото. Янн также консультируется Перси Лян и Сюйхеном также рекомендуется Карлосом Гестрином.
Пожалуйста, цитируйте репо, если вы используете данные или код в этом репо.
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
Естественно, вы также должны цитировать оригинальную бумагу лама [1] и бумагу для самостоятельной конструкции [2].
Мы благодарим Йижонга Ванга за его помощь в объяснении конвейера генерации данных в самостоятельстве и предоставлении кода для анализа анализа. Мы благодарим Ифана Май за полезную поддержку и членов Стэнфордской группы НЛП, а также Центр исследований моделей фонда (CRFM) за их полезную обратную связь.


