stanford_alpaca
1.0.0

これは、スタンフォードアルパカプロジェクトのレポです。これは、指導に従うラマモデルの構築と共有を目的としています。リポジトリには次のものが含まれています。
注:Stanford-Alpacaに関するフィードバックと研究のサポートについてコミュニティに感謝します。私たちのライブデモは、さらなる通知があるまで中断されます。
使用およびライセンス通知:Alpacaは、研究のみを意図し、ライセンスを取得しています。データセットはNC 4.0によるCC(非営利的な使用のみを可能にします)であり、データセットを使用してトレーニングされたモデルは、研究目的以外では使用しないでください。重量diffは、NC 4.0によるCCでもあります(非営利的な使用のみを可能にします)。
現在のALPACAモデルは、自己インストラクション[2]論文の手法によって生成された52K命令フォローデータの7B Llamaモデル[1]から微調整されており、次のセクションで説明するいくつかの変更を加えています。予備的な人間の評価では、Alpaca 7Bモデルが自己インストラクション指導に従う評価スイートでtext-davinci-003モデルと同様に動作することがわかりました[2]。
Alpacaはまだ開発中であり、対処する必要がある多くの制限があります。重要なことに、Alpacaモデルを安全で無害であるとまだ微調整していません。したがって、ユーザーはAlpacaと対話する際に慎重になることを奨励し、モデルの安全性と倫理的考慮事項を改善するために懸念される行動を報告することを奨励します。
最初のリリースには、データ生成手順、データセット、およびトレーニングレシピが含まれています。 Llamaの作成者からそうする許可が与えられた場合、モデルの重みをリリースする予定です。今のところ、読者がアルパカの能力と限界をよりよく理解できるように、ライブデモをホストすることを選択しました。
モデルの詳細については、リリースブログ投稿、Alpacaモデルの潜在的な害と制限に関する議論、再現可能なモデルをリリースするための思考プロセスをお読みください。
[1]:Llama:オープンで効率的な基礎言語モデル。ヒューゴ・トーブロン、ティボー・ラヴリル、ゴーティエ・イザカード、ザビエル・マルティネット、マリー・アン・ラッコー、ティモテ・ラクロア、バプティスト・ロジエール、ナマン・ゴイヤル、エリック・ハンブロ、フェイサル・アズハル、アウレリエン・ロドリゲス、アーマンド・ジュウルン、エドゥーヤード・グラップ、エドゥーヤード・グラップ、 https://arxiv.org/abs/2302.13971v1
[2]:自己intruct:自己生成命令を備えた言語モデルを調整します。 Yizhong Wang、Yeganeh Kordi、Swaroop Mishra、Alisa Liu、Noah A. Smith、Daniel Khashabi、Hannaneh Hajishirzi。 https://arxiv.org/abs/2212.10560
alpaca_data.jsonには、ALPACAモデルの微調整に使用した52K命令フォローのデータが含まれています。このJSONファイルは辞書のリストであり、各辞書には次のフィールドが含まれています。
instruction : str 、モデルが実行するタスクを説明します。 52Kのそれぞれの指示は一意です。input : str 、タスクのオプションのコンテキストまたは入力。たとえば、命令が「次の記事を要約する」場合、入力は記事です。例の約40%に入力があります。output : str 、 text-davinci-003によって生成された命令に対する答え。Alpacaモデルを微調整するために、次のプロンプトを使用しました。
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
推論中(例:Webデモの場合)、空の入力フィールドを使用してユーザー命令を使用します(2番目のオプション)。
OPENAI_API_KEY Openai APIキーに設定します。pip install -r requirements.txtを使用して依存関係をインストールします。python -m generate_instruction generate_instruction_following_dataを実行してデータを生成します。私たちは、自己計測からデータ生成パイプラインに基づいて構築され、次の変更を行いました。
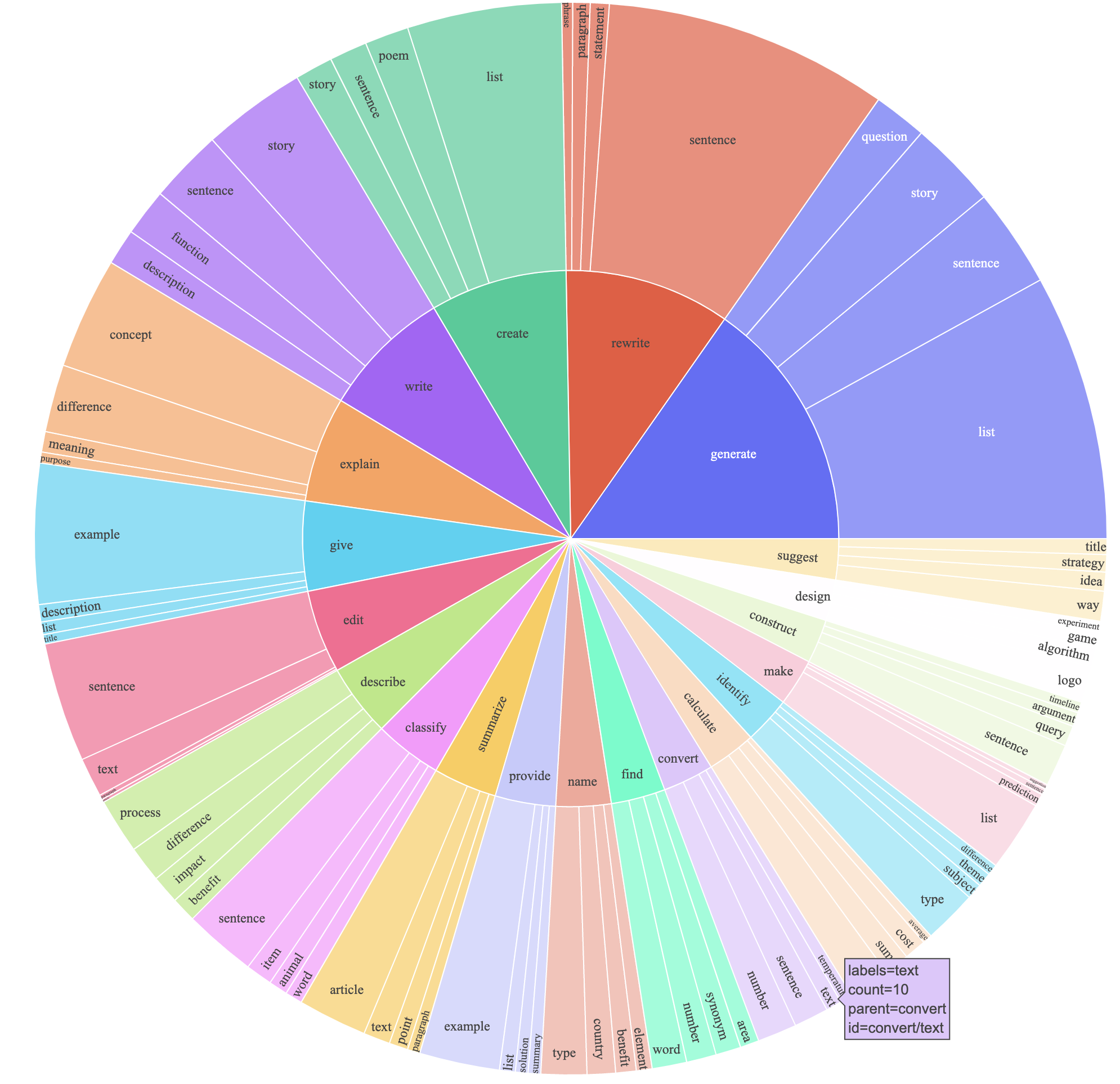
text-davinci-003を使用して、 davinciの代わりに命令データを生成しました。text-davinci-003に命令生成の要件を明示的に与えた新しいプロンプト( prompt.txt )を書きました。注:使用したプロンプトにわずかなエラーがあり、将来のユーザーは#24に編集を組み込む必要があります。これにより、はるかに低いコスト(500ドル未満)で得られた52Kの例を備えた命令に従うデータセットが生成されました。予備調査では、52K生成データも、自己インストラクションによってリリースされたデータよりもはるかに多様であることがわかりました。以下の図をプロットします(データの多様性を示すために、自己インストラクション紙の図2のスタイルで。プロットの内側の円は命令のルート動詞を表し、外側の円は直接オブジェクトを表します。
標準の抱擁フェイストレーニングコードを使用してモデルを微調整します。 Llama-7bとLlama-13bを次のハイパーパラメーターで微調整します。
| ハイパーパラメーター | llama-7b | llama-13b |
|---|---|---|
| バッチサイズ | 128 | 128 |
| 学習率 | 2E-5 | 1E-5 |
| エポック | 3 | 5 |
| 最大長 | 512 | 512 |
| 重量減衰 | 0 | 0 |
Llamaの微調整ランを再現するには、最初に要件をインストールします
pip install -r requirements.txt以下は、FSDP full_shardモードで4 A100 80G GPUを備えたマシンにデータセットを備えたLlama-7Bを微調整するコマンドです。 Python 3.10を使用して、次のコマンドを使用して、デモでホストしたものと同様の品質のモデルを再現することができました。 <your_random_port>独自のポートに置き換えます。 <your_path_to_hf_converted_llama_ckpt_and_tokenizer>変換されたチェックポイントとトークンザーへのパス(PRの指示に従って)、および<your_output_dir>を出力を保存したい場所に<your_output_dir>
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 True同じスクリプトは、OPT微調整にも動作します。微調整opt-6.7bの例を次に示します
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True指定されたトレーニングスクリプトは、シンプルで使いやすいことを意図しており、特に最適化されていません。より多くのGPUで実行するには、 gradient_accumulation_stepsを下げて128のグローバルバッチサイズを維持することをお勧めします。グローバルバッチサイズは最適性についてテストされていません。
素朴に、7Bモデルを微調整するには、約7 x 4 x 4 = 112 GBのVRAMが必要です。上記のコマンドはパラメーターのシャードを有効にするため、GPUに冗長モデルコピーは保存されません。メモリフットプリントをさらに削減したい場合は、いくつかのオプションを次に示します。
--fsdp "full_shard auto_wrap offload"を使用して、FSDPのCPUオフロードをオンにします。これにより、ランタイムが長くなるとVRAMが節約されます。pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 TrueAlpaca-7BとLlama-7Bの間の重量違いはここにあります。元のAlpaca-7Bの重量を回復するには、次の手順に従ってください。
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
ステップ3が完了したら、回復した重量のあるディレクトリが必要です。そこからモデルを次のように読み込むことができます
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )以下のすべての卒業生は均等に貢献し、注文はランダムドローによって決定されます。
Tatsunori B. Hashimotoからアドバイス。 YannはPercy Liangからもアドバイスされており、XuechenはCarlos Guestrinからアドバイスされています。
このレポでデータまたはコードを使用する場合は、レポを引用してください。
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
当然のことながら、元のLlama Paper [1]と自己計算紙[2]も引用する必要があります。
Yizhong Wangは、自己計測におけるデータ生成パイプラインを説明し、Parse Analysis Plotのコードを提供してくれたことに感謝します。有用なサポートをしてくれたYifan Mai、スタンフォードNLPグループのメンバーと、有益なフィードバックについてFoundation Modelsの研究センター(CRFM)に感謝します。


