stanford_alpaca
1.0.0

Ini adalah repo untuk Proyek Stanford Alpaca, yang bertujuan untuk membangun dan berbagi model Llama yang mengikuti instruksi. Repo berisi:
Catatan: Kami berterima kasih kepada komunitas atas umpan balik tentang Stanford-Alpaca dan mendukung penelitian kami. Demo langsung kami ditangguhkan sampai pemberitahuan lebih lanjut.
Pemberitahuan Penggunaan dan Lisensi : Alpaca dimaksudkan dan dilisensikan hanya untuk penggunaan penelitian. Dataset adalah CC oleh NC 4.0 (hanya memungkinkan penggunaan non-komersial) dan model yang dilatih menggunakan dataset tidak boleh digunakan di luar tujuan penelitian. Diff bobot juga CC oleh NC 4.0 (hanya memungkinkan penggunaan non-komersial).
Model ALPACA saat ini disesuaikan dengan model 7B LLAMA [1] pada data pengikut instruksi 52K yang dihasilkan oleh teknik dalam kertas instruktur [2] sendiri, dengan beberapa modifikasi yang kita diskusikan di bagian selanjutnya. Dalam evaluasi manusia awal, kami menemukan bahwa model Alpaca 7B berperilaku mirip dengan model text-davinci-003 pada rangkaian evaluasi pengikut instruksi-mengikuti instruksi-diri [2].
Alpaca masih dalam pengembangan, dan ada banyak keterbatasan yang harus ditangani. Yang penting, kami belum menyempurnakan model alpaca untuk aman dan tidak berbahaya. Dengan demikian, kami mendorong pengguna untuk berhati -hati ketika berinteraksi dengan Alpaca, dan untuk melaporkan perilaku tentang apa pun untuk membantu meningkatkan keselamatan dan pertimbangan etis dari model tersebut.
Rilis awal kami berisi prosedur pembuatan data, dataset, dan resep pelatihan. Kami bermaksud untuk melepaskan bobot model jika kami diberi izin untuk melakukannya oleh pencipta Llama. Untuk saat ini, kami telah memilih untuk menjadi tuan rumah demo langsung untuk membantu pembaca lebih memahami kemampuan dan batas Alpaka, serta cara untuk membantu kami mengevaluasi kinerja Alpaca dengan lebih baik pada audiens yang lebih luas.
Harap baca posting blog rilis kami untuk detail lebih lanjut tentang model, diskusi kami tentang potensi bahaya dan keterbatasan model Alpaca, dan proses pemikiran kami untuk merilis model yang dapat direproduksi.
[1]: Llama: Model Bahasa Yayasan Terbuka dan Efisien. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. https://arxiv.org/abs/2302.13971v1
[2]: Mandiri: Model Bahasa Menyelaraskan dengan instruksi yang dihasilkan sendiri. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hananeh Hajishirzi. https://arxiv.org/abs/2212.10560
alpaca_data.json berisi 52K data mengikuti instruksi yang kami gunakan untuk menyempurnakan model alpaca. File JSON ini adalah daftar kamus, setiap kamus berisi bidang berikut:
instruction : str , menjelaskan tugas yang harus dilakukan model. Masing -masing instruksi 52K unik.input : str , konteks opsional atau input untuk tugas tersebut. Misalnya, ketika instruksi adalah "merangkum artikel berikut", inputnya adalah artikel. Sekitar 40% dari contoh memiliki input.output : str , jawaban untuk instruksi seperti yang dihasilkan oleh text-davinci-003 .Kami menggunakan petunjuk berikut untuk menyempurnakan model alpaca:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
Selama inferensi (misalnya untuk demo web), kami menggunakan instruksi pengguna dengan bidang input kosong (opsi kedua).
OPENAI_API_KEY ke kunci API openai Anda.pip install -r requirements.txt .python -m generate_instruction generate_instruction_following_data untuk menghasilkan data.Kami membangun di atas pipa pembuatan data dari instruktur mandiri dan membuat modifikasi berikut:
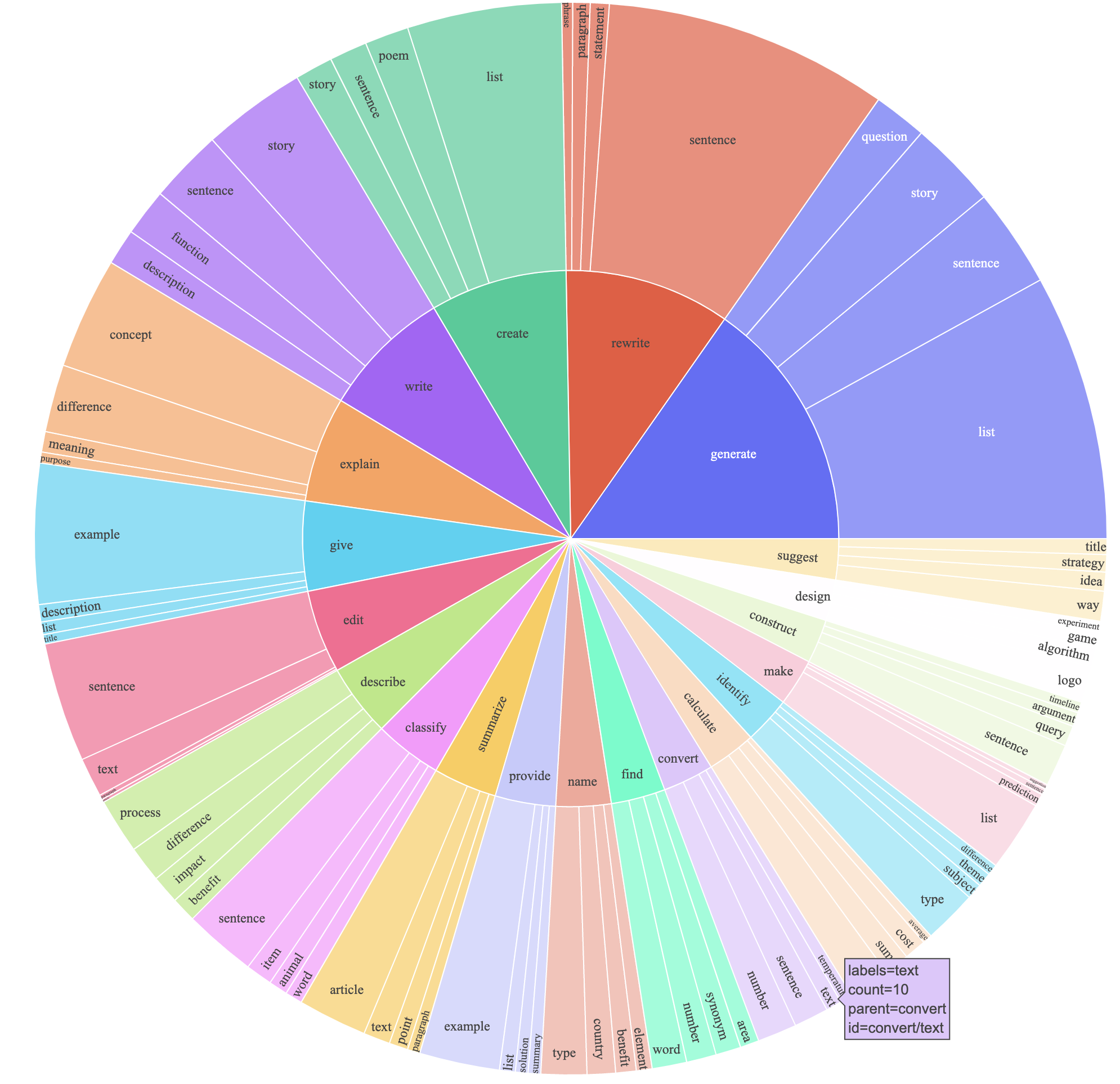
text-davinci-003 untuk menghasilkan data instruksi alih-alih davinci .prompt.txt ) yang secara eksplisit memberikan persyaratan pembuatan instruksi kepada text-davinci-003 . CATATAN: Ada sedikit kesalahan dalam prompt yang kami gunakan, dan pengguna masa depan harus memasukkan edit di #24Ini menghasilkan dataset mengikuti instruksi dengan contoh 52K yang diperoleh dengan biaya yang jauh lebih rendah (kurang dari $ 500). Dalam studi pendahuluan, kami juga menemukan data yang dihasilkan 52K kami jauh lebih beragam daripada data yang dirilis oleh mandiri. Kami memplot gambar di bawah ini (dalam gaya Gambar 2 dalam kertas instruksikan diri untuk menunjukkan keragaman data kami. Lingkaran dalam plot mewakili kata kerja akar dari instruksi, dan lingkaran luar mewakili objek langsung.
Kami menyempurnakan model kami menggunakan kode pelatihan wajah pelukan standar. Kami menyempurnakan llama-7b dan llama-13b dengan hyperparameter berikut:
| Hyperparameter | Llama-7b | Llama-13b |
|---|---|---|
| Ukuran batch | 128 | 128 |
| Tingkat pembelajaran | 2e-5 | 1E-5 |
| Zaman | 3 | 5 |
| Panjang maksimal | 512 | 512 |
| Kerusakan berat badan | 0 | 0 |
Untuk mereproduksi menjalankan fine-tuning kami untuk Llama, pertama-tama pasang persyaratan
pip install -r requirements.txt Di bawah ini adalah perintah yang fine-tunes llama-7b dengan dataset kami pada mesin dengan 4 A100 80G GPU dalam mode FSDP full_shard . Kami dapat mereproduksi model dengan kualitas yang sama dengan yang kami host dalam demo kami dengan perintah berikut menggunakan Python 3.10 . Ganti <your_random_port> dengan port Anda sendiri, <your_path_to_hf_converted_llama_ckpt_and_tokenizer> dengan jalur ke pos pemeriksaan dan tokenizer Anda yang dikonversi (mengikuti instruksi di PR), dan <your_output_dir> dengan di mana Anda ingin menyimpan output Anda.
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 TrueScript yang sama juga berfungsi untuk fine-tuning opt. Berikut contoh untuk menyempurnakan opt-6.7b
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True Perhatikan skrip pelatihan yang diberikan dimaksudkan untuk sederhana dan mudah digunakan, dan tidak dioptimalkan. Untuk menjalankan lebih banyak GPU, Anda dapat lebih suka menolak gradient_accumulation_steps untuk menjaga ukuran batch global 128. Ukuran batch global belum diuji untuk optimalitas.
Naif, menyempurnakan model 7b membutuhkan sekitar 7 x 4 x 4 = 112 GB VRAM. Perintah yang diberikan di atas mengaktifkan parameter sharding, jadi tidak ada salinan model yang berlebihan disimpan pada GPU apa pun. Jika Anda ingin mengurangi jejak memori lebih lanjut, berikut adalah beberapa opsi:
--fsdp "full_shard auto_wrap offload" . Ini menghemat VRAM dengan biaya runtime yang lebih lama.pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 TrueBobot bobot antara ALPACA-7B dan LLAMA-7B terletak di sini. Untuk memulihkan bobot alpaca-7b asli, ikuti langkah-langkah ini:
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
Setelah langkah 3 selesai, Anda harus memiliki direktori dengan bobot yang dipulihkan, dari mana Anda dapat memuat model seperti berikut
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )Semua mahasiswa pascasarjana di bawah ini berkontribusi sama dan pesanan ditentukan oleh undian acak.
Semua yang disarankan oleh Tatsunori B. Hashimoto. Yann juga disarankan oleh Percy Liang dan Xuechen juga disarankan oleh Carlos Guestrin.
Harap kutip repo jika Anda menggunakan data atau kode dalam repo ini.
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
Secara alami, Anda juga harus mengutip kertas llama asli [1] dan kertas instruktur diri [2].
Kami berterima kasih kepada Yizhong Wang atas bantuannya dalam menjelaskan pipa pembuatan data dalam instruksi sendiri dan memberikan kode untuk plot analisis parse. Kami berterima kasih kepada Yifan Mai atas dukungan yang bermanfaat, dan anggota Grup NLP Stanford serta Pusat Penelitian tentang Model Yayasan (CRFM) atas umpan balik mereka yang bermanfaat.


