stanford_alpaca
1.0.0

Este es el repositorio para el proyecto Stanford Alpaca, cuyo objetivo es construir y compartir un modelo de llama de seguimiento de instrucciones. El repositorio contiene:
Nota: Agradecemos a la comunidad por sus comentarios sobre Stanford-Alpaca y apoyando nuestra investigación. Nuestra demostración en vivo se suspende hasta nuevo aviso.
Uso y avisos de licencia : Alpaca está destinado y con licencia solo para uso de la investigación. El conjunto de datos es CC por NC 4.0 (que permite solo un uso no comercial) y los modelos capacitados utilizando el conjunto de datos no deben usarse fuera de fines de investigación. La diferencia de peso también es CC por NC 4.0 (que permite solo un uso no comercial).
El modelo actual de Alpaca está ajustado a partir de un modelo 7B LLAMA [1] en los datos de seguimiento de instrucciones de 52k generados por las técnicas en el documento de autoinstructo [2], con algunas modificaciones que discutimos en la siguiente sección. En una evaluación humana preliminar, encontramos que el modelo Alpaca 7B se comporta de manera similar al modelo text-davinci-003 en el conjunto de evaluación de instrucciones de autoinstrucciones [2].
La alpaca todavía está en desarrollo, y hay muchas limitaciones que deben abordarse. Es importante destacar que aún no hemos ajustado al modelo de Alpaca para que sea seguro e inofensivo. Por lo tanto, alentamos a los usuarios a ser cautelosos cuando interactúan con la alpaca, y a informar cualquier comportamiento preocupante para ayudar a mejorar la seguridad y las consideraciones éticas del modelo.
Nuestra versión inicial contiene el procedimiento de generación de datos, el conjunto de datos y la receta de capacitación. Tenemos la intención de lanzar los pesos del modelo si los creadores de LLAMA nos dan permiso para hacerlo. Por ahora, hemos elegido organizar una demostración en vivo para ayudar a los lectores a comprender mejor las capacidades y límites de Alpaca, así como una forma de ayudarnos a evaluar mejor el rendimiento de Alpaca en una audiencia más amplia.
Lea nuestra publicación de blog de lanzamiento para obtener más detalles sobre el modelo, nuestra discusión sobre el daño potencial y las limitaciones de los modelos de Alpaca, y nuestro proceso de pensamiento para lanzar un modelo reproducible.
[1]: LLAMA: modelos de lenguaje de base abierto y eficiente. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lappeum. https://arxiv.org/abs/2302.13971v1
[2]: autoinstructo: alineación del modelo de lenguaje con instrucciones auto-generadas. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi. https://arxiv.org/abs/2212.10560
alpaca_data.json contiene datos de seguimiento de instrucciones de 52k que utilizamos para ajustar el modelo Alpaca. Este archivo JSON es una lista de diccionarios, cada diccionario contiene los siguientes campos:
instruction : str , describe la tarea que debe realizar el modelo. Cada una de las instrucciones de 52k es única.input : str , contexto o entrada opcional para la tarea. Por ejemplo, cuando la instrucción es "resumir el siguiente artículo", la entrada es el artículo. Alrededor del 40% de los ejemplos tienen una entrada.output : str , la respuesta a la instrucción generada por text-davinci-003 .Utilizamos las siguientes indicaciones para ajustar el modelo Alpaca:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
Durante la inferencia (por ejemplo, para la demostración web), utilizamos la instrucción del usuario con un campo de entrada vacío (segunda opción).
OPENAI_API_KEY en su tecla API OpenAI.pip install -r requirements.txt .python -m generate_instruction generate_instruction_following_data para generar los datos.Nos basamos en la tubería de generación de datos a partir de la autoestructura e hicimos las siguientes modificaciones:
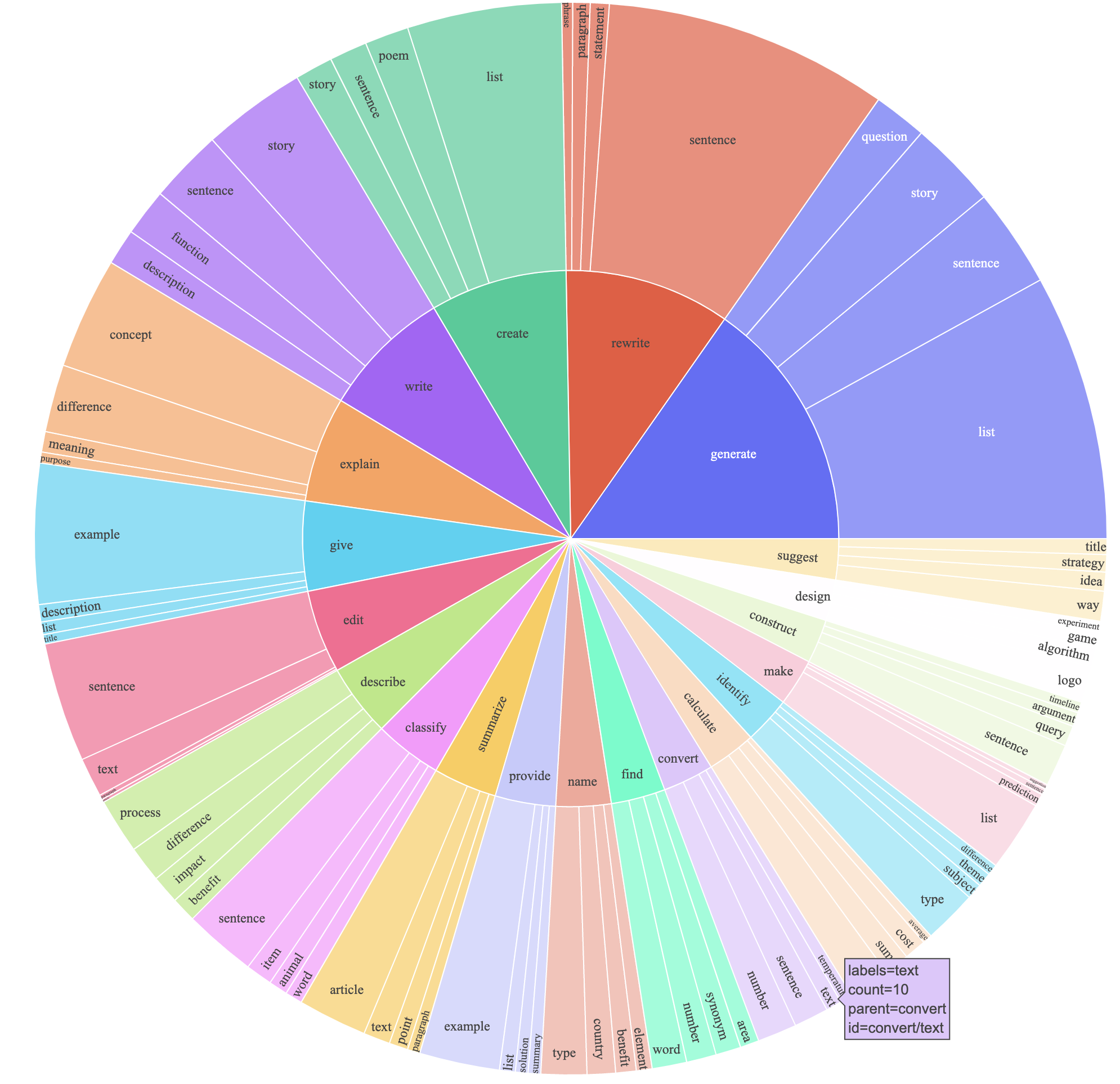
text-davinci-003 para generar los datos de instrucciones en lugar de davinci .prompt.txt ) que dio explícitamente el requisito de generación de instrucciones a text-davinci-003 . Nota: Hay un ligero error en el mensaje que utilizamos, y los usuarios futuros deben incorporar la edición en el #24Esto produjo un conjunto de datos de seguimiento de instrucciones con 52k ejemplos obtenidos a un costo mucho más bajo (menos de $ 500). En un estudio preliminar, también encontramos que nuestros datos generados 52k son mucho más diversos que los datos publicados por el autoestructo. Trazamos la siguiente figura (en el estilo de la Figura 2 en el documento de autoinstrucción para demostrar la diversidad de nuestros datos. El círculo interno de la gráfica representa el verbo raíz de las instrucciones, y el círculo externo representa los objetos directos.
Afinguamos nuestros modelos utilizando el código de entrenamiento facial estándar. Hemos afinado Llama-7B y Llama-13B con los siguientes hiperparámetros:
| Hiperparámetro | Llama-7b | Llama-13b |
|---|---|---|
| Tamaño por lotes | 128 | 128 |
| Tasa de aprendizaje | 2E-5 | 1e-5 |
| Épocas | 3 | 5 |
| Longitud máxima | 512 | 512 |
| Descomposición de peso | 0 | 0 |
Para reproducir nuestras corridas de ajuste para LLAMA, primero instale los requisitos
pip install -r requirements.txt A continuación se muestra un comando que Fine-Tunes Llama-7B con nuestro conjunto de datos en una máquina con 4 GPU de 80G A100 en el modo FSDP full_shard . Pudimos reproducir un modelo de calidad similar al que organizamos en nuestra demostración con el siguiente comando usando Python 3.10 . Reemplace <your_random_port> con un puerto propio, <your_path_to_hf_converted_llama_ckpt_and_tokenizer> con la ruta a su punto de control convertido y tokenizer (siguientes instrucciones en el PR) y <your_output_dir> con dónde desea almacenar sus salidas.
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 TrueEl mismo script también funciona para optar de ajuste. Aquí hay un ejemplo para ajustar la opción de 6.7b
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True Tenga en cuenta que el script de entrenamiento dado está destinado a ser simple y fácil de usar, y no está particularmente optimizado. Para ejecutarse en más GPU, es posible que prefiera rechazar gradient_accumulation_steps para mantener un tamaño de lote global de 128. El tamaño global de lotes no se ha probado para su optimización.
Ingenuamente, el ajuste fino de un modelo 7B requiere aproximadamente 7 x 4 x 4 = 112 GB de VRAM. Los comandos dados anteriormente habilitar el fragmento de parámetros, por lo que no se almacena una copia de modelo redundante en ninguna GPU. Si desea reducir aún más la huella de la memoria, aquí hay algunas opciones:
--fsdp "full_shard auto_wrap offload" . Esto ahorra VRAM a costa de un tiempo de ejecución más largo.pip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 TrueLa diferencia de peso entre Alpaca-7B y Llama-7B se encuentra aquí. Para recuperar los pesos Alpaca-7B originales, siga estos pasos:
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
Una vez que se completa el paso 3, debe tener un directorio con los pesos recuperados, desde el cual puede cargar el modelo como el siguiente
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )Todos los estudiantes graduados a continuación contribuyeron por igual y el orden está determinado por un sorteo aleatorio.
Todos aconsejados por Tatsunori B. Hashimoto. Yann también es aconsejado por Percy Liang y Xuechen también es aconsejado por Carlos Guestrin.
Cite el repositorio si usa los datos o el código en este repositorio.
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
Naturalmente, también debe citar el papel de Llama original [1] y el papel de autoestructura [2].
Agradecemos a Yizhong Wang por su ayuda para explicar la tubería de la generación de datos en autoinstrucción y proporcionar el código para el diagrama de análisis de análisis. Agradecemos a Yifan Mai por su útil apoyo, y miembros del Grupo Stanford NLP, así como del Centro de Investigación sobre Modelos de Fundaciones (CRFM) por sus comentarios útiles.


