stanford_alpaca
1.0.0

นี่คือ repo สำหรับโครงการ Stanford Alpaca ซึ่งมีวัตถุประสงค์เพื่อสร้างและแบ่งปันแบบจำลอง Llama ตามคำแนะนำ repo ประกอบด้วย:
หมายเหตุ: เราขอขอบคุณชุมชนสำหรับข้อเสนอแนะเกี่ยวกับ Stanford-Alpaca และสนับสนุนการวิจัยของเรา การสาธิตสดของเราถูกระงับจนกว่าจะมีการแจ้งให้ทราบต่อไป
ประกาศการใช้งานและใบอนุญาต : Alpaca มีวัตถุประสงค์และได้รับใบอนุญาตสำหรับการใช้งานวิจัยเท่านั้น ชุดข้อมูลคือ CC โดย NC 4.0 (อนุญาตให้ใช้งานที่ไม่ใช่เชิงพาณิชย์เท่านั้น) และแบบจำลองที่ผ่านการฝึกอบรมโดยใช้ชุดข้อมูลไม่ควรใช้นอกวัตถุประสงค์ในการวิจัย ความแตกต่างของน้ำหนักคือ CC โดย NC 4.0 (อนุญาตให้ใช้งานที่ไม่ใช่เชิงพาณิชย์เท่านั้น)
โมเดล ALPACA ปัจจุบันได้รับการปรับแต่งจากรุ่น 7B LLAMA [1] บนข้อมูลที่ตามคำสั่ง 52K ที่สร้างขึ้นโดยเทคนิคในกระดาษ Instruct [2] ด้วยการปรับเปลี่ยนบางอย่างที่เราพูดถึงในส่วนถัดไป ในการประเมินผลของมนุษย์เบื้องต้นเราพบว่าโมเดล Alpaca 7B มีพฤติกรรมคล้ายกับแบบจำลอง text-davinci-003 ในชุดการประเมินผลการเรียนการสอนด้วยตนเองที่ตามมา [2]
Alpaca ยังอยู่ระหว่างการพัฒนาและมีข้อ จำกัด มากมายที่ต้องได้รับการแก้ไข ที่สำคัญเรายังไม่ได้ปรับโมเดล Alpaca ให้ปลอดภัยและไม่เป็นอันตราย ดังนั้นเราจึงสนับสนุนให้ผู้ใช้ระมัดระวังเมื่อมีปฏิสัมพันธ์กับ Alpaca และรายงานพฤติกรรมใด ๆ ที่เกี่ยวข้องเพื่อช่วยปรับปรุงความปลอดภัยและการพิจารณาทางจริยธรรมของแบบจำลอง
การเปิดตัวครั้งแรกของเราประกอบด้วยขั้นตอนการสร้างข้อมูลชุดข้อมูลและสูตรการฝึกอบรม เราตั้งใจที่จะปลดปล่อยน้ำหนักแบบจำลองหากเราได้รับอนุญาตให้ทำเช่นนั้นโดยผู้สร้าง Llama สำหรับตอนนี้เราได้เลือกที่จะเป็นเจ้าภาพการสาธิตสดเพื่อช่วยให้ผู้อ่านเข้าใจความสามารถและขีด จำกัด ของ Alpaca ได้ดีขึ้นรวมถึงวิธีที่จะช่วยให้เราประเมินประสิทธิภาพของ Alpaca ได้ดีขึ้น
โปรดอ่านโพสต์บล็อกรุ่นของเราสำหรับรายละเอียดเพิ่มเติมเกี่ยวกับรูปแบบการอภิปรายของเราเกี่ยวกับอันตรายที่อาจเกิดขึ้นและข้อ จำกัด ของโมเดล Alpaca และกระบวนการคิดของเราในการปล่อยโมเดลที่ทำซ้ำได้
[1]: Llama: แบบเปิดและเปิดกว้างแบบจำลองภาษาพื้นฐาน Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez https://arxiv.org/abs/2302.13971v1
[2]: Instruct ตัวเอง: จัดแนวโมเดลภาษากับคำแนะนำที่สร้างขึ้นด้วยตนเอง Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi https://arxiv.org/abs/2212.10560
alpaca_data.json มีข้อมูลตามคำสั่ง 52K ที่เราใช้สำหรับการปรับแต่งโมเดล Alpaca ไฟล์ JSON นี้เป็นรายการพจนานุกรมแต่ละพจนานุกรมมีฟิลด์ต่อไปนี้:
instruction : str อธิบายงานที่โมเดลควรดำเนินการ แต่ละคำแนะนำ 52K นั้นไม่ซ้ำกันinput : str , บริบททางเลือกหรืออินพุตสำหรับงาน ตัวอย่างเช่นเมื่อคำสั่งคือ "สรุปบทความต่อไปนี้" อินพุตเป็นบทความ ประมาณ 40% ของตัวอย่างมีอินพุตoutput : str คำตอบของคำสั่งที่สร้างโดย text-davinci-003เราใช้พรอมต์ต่อไปนี้สำหรับการปรับแต่งรุ่น Alpaca:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
ในระหว่างการอนุมาน (เช่นสำหรับการสาธิตเว็บ) เราใช้คำสั่งผู้ใช้กับฟิลด์อินพุตว่าง (ตัวเลือกที่สอง)
OPENAI_API_KEY เป็นคีย์ OpenAI API ของคุณpip install -r requirements.txtpython -m generate_instruction generate_instruction_following_data เพื่อสร้างข้อมูลเราสร้างขึ้นบนท่อส่งข้อมูลจาก Instruct ตัวเองและทำการปรับเปลี่ยนต่อไปนี้:
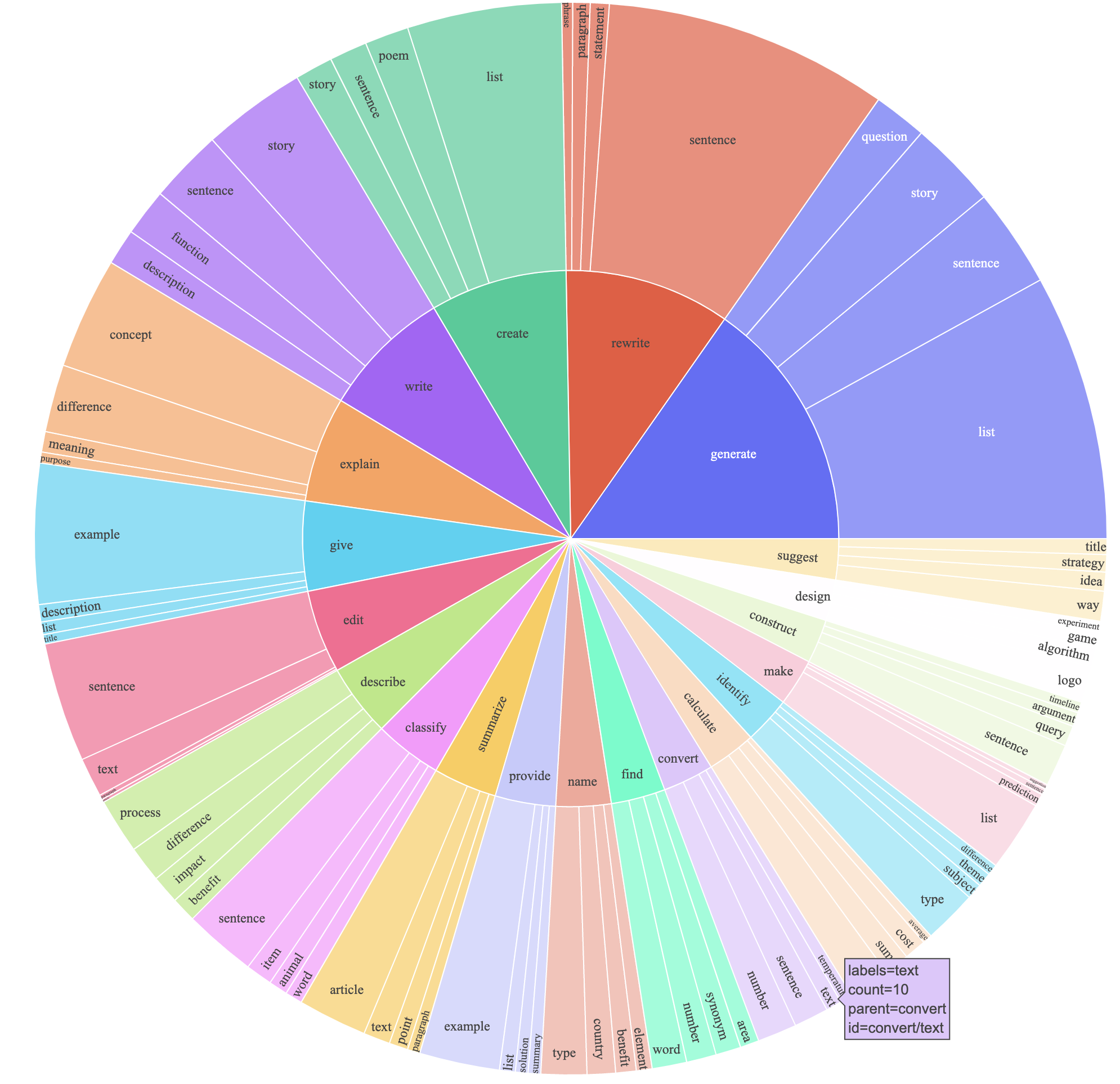
text-davinci-003 เพื่อสร้างข้อมูลคำสั่งแทน davinciprompt.txt ) ที่ให้ข้อกำหนดของการสร้างคำสั่งอย่างชัดเจนกับ text-davinci-003 หมายเหตุ: มีข้อผิดพลาดเล็กน้อยในพรอมต์ที่เราใช้และผู้ใช้ในอนาคตควรรวมการแก้ไขใน #24สิ่งนี้ผลิตชุดข้อมูลตามคำสั่งพร้อมตัวอย่าง 52K ที่ได้รับในราคาที่ต่ำกว่ามาก (น้อยกว่า $ 500) ในการศึกษาเบื้องต้นเรายังพบว่าข้อมูลที่สร้างขึ้น 52K ของเรามีความหลากหลายมากกว่าข้อมูลที่เผยแพร่โดย Instruct ด้วยตนเอง เราพล็อตรูปด้านล่าง (ในรูปแบบของรูปที่ 2 ในกระดาษ Instruct เพื่อแสดงให้เห็นถึงความหลากหลายของข้อมูลของเราวงกลมด้านในของพล็อตแสดงถึงคำกริยารากของคำแนะนำและวงกลมด้านนอกแสดงถึงวัตถุโดยตรง
เราปรับแต่งโมเดลของเราโดยใช้รหัสการฝึกอบรมการกอดมาตรฐาน เราปรับแต่ง LLAMA-7B และ LLAMA-13B ด้วย hyperparameters ต่อไปนี้:
| พารามิเตอร์ไฮเปอร์ | LLAMA-7B | llama-13b |
|---|---|---|
| ขนาดแบทช์ | 128 | 128 |
| อัตราการเรียนรู้ | 2e-5 | 1E-5 |
| ยุค | 3 | 5 |
| ความยาวสูงสุด | 512 | 512 |
| การสลายตัวของน้ำหนัก | 0 | 0 |
ในการทำซ้ำการปรับจูนของเราสำหรับ Llama ให้ติดตั้งข้อกำหนดก่อน
pip install -r requirements.txt ด้านล่างนี้เป็นคำสั่งที่ปรับแต่ง LLAMA-7B พร้อมชุดข้อมูลของเราบนเครื่องที่มี 4 A100 80G GPU ในโหมด FSDP full_shard เราสามารถทำซ้ำรูปแบบคุณภาพที่คล้ายกันกับที่เราโฮสต์ในการสาธิตของเราด้วยคำสั่งต่อไปนี้โดยใช้ Python 3.10 แทนที่ <your_random_port> ด้วยพอร์ตของคุณเอง <your_path_to_hf_converted_llama_ckpt_and_tokenizer> ด้วยเส้นทางไปยังจุดตรวจสอบและโท <your_output_dir> นที่แปลงแล้ว
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' LlamaDecoderLayer '
--tf32 Trueสคริปต์เดียวกันยังใช้งานได้สำหรับการปรับแต่งการเลือก นี่คือตัวอย่างสำหรับการปรับแต่งอย่างละเอียด -6.7b
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path " facebook/opt-6.7b "
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 1
--fsdp " full_shard auto_wrap "
--fsdp_transformer_layer_cls_to_wrap ' OPTDecoderLayer '
--tf32 True หมายเหตุสคริปต์การฝึกอบรมที่กำหนดนั้นง่ายและใช้งานง่ายและไม่ได้รับการปรับให้เหมาะสมเป็นพิเศษ ในการทำงานกับ GPU มากขึ้นคุณอาจต้องการลดระดับการไล่ gradient_accumulation_steps เพื่อรักษาขนาดแบทช์ทั่วโลกที่ 128 ขนาดแบทช์ทั่วโลกยังไม่ได้รับการทดสอบเพื่อการปรับให้เหมาะสม
อย่างไร้เดียงสาการปรับแต่งรุ่น 7B ต้องใช้ VRAM ประมาณ 7 x 4 x 4 = 112 GB คำสั่งที่ให้ไว้ข้างต้นเปิดใช้งานพารามิเตอร์การให้ข้อมูลดังนั้นจึงไม่มีสำเนาโมเดลซ้ำซ้อนที่เก็บไว้ใน GPU ใด ๆ หากคุณต้องการลดรอยเท้าหน่วยความจำต่อไปนี้เป็นตัวเลือกบางอย่าง:
--fsdp "full_shard auto_wrap offload" สิ่งนี้จะช่วยประหยัด VRAM ด้วยค่าใช้จ่ายของรันไทม์ที่ยาวนานขึ้นpip install deepspeed
torchrun --nproc_per_node=4 --master_port= < your_random_port > train.py
--model_name_or_path < your_path_to_hf_converted_llama_ckpt_and_tokenizer >
--data_path ./alpaca_data.json
--bf16 True
--output_dir < your_output_dir >
--num_train_epochs 3
--per_device_train_batch_size 4
--per_device_eval_batch_size 4
--gradient_accumulation_steps 8
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 2000
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 Trueน้ำหนักความแตกต่างระหว่าง Alpaca-7b และ Llama-7b ตั้งอยู่ที่นี่ หากต้องการกู้คืนน้ำหนัก Alpaca-7b ดั้งเดิมให้ทำตามขั้นตอนเหล่านี้:
1. Convert Meta's released weights into huggingface format. Follow this guide:
https://huggingface.co/docs/transformers/main/model_doc/llama
2. Make sure you cloned the released weight diff into your local machine. The weight diff is located at:
https://huggingface.co/tatsu-lab/alpaca-7b/tree/main
3. Run this function with the correct paths. E.g.,
python weight_diff.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
เมื่อขั้นตอนที่ 3 เสร็จสมบูรณ์คุณควรมีไดเรกทอรีที่มีน้ำหนักที่กู้คืนซึ่งคุณสามารถโหลดโมเดลได้ดังต่อไปนี้
import transformers
alpaca_model = transformers . AutoModelForCausalLM . from_pretrained ( "<path_to_store_recovered_weights>" )
alpaca_tokenizer = transformers . AutoTokenizer . from_pretrained ( "<path_to_store_recovered_weights>" )นักเรียนระดับบัณฑิตศึกษาทุกคนด้านล่างมีส่วนร่วมอย่างเท่าเทียมกันและคำสั่งจะถูกกำหนดโดยการจับแบบสุ่ม
ทั้งหมดได้รับคำแนะนำจาก Tatsunori B. Hashimoto Yann ยังได้รับคำแนะนำจาก Percy Liang และ Xuechen โดย Carlos Guestrin
โปรดอ้างอิง repo หากคุณใช้ข้อมูลหรือรหัสใน repo นี้
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/tatsu-lab/stanford_alpaca}},
}
โดยธรรมชาติแล้วคุณควรอ้างถึงกระดาษ Llama ต้นฉบับ [1] และกระดาษที่นำด้วยตนเอง [2]
เราขอขอบคุณ Yizhong Wang สำหรับความช่วยเหลือของเขาในการอธิบายท่อส่งข้อมูลในการควบคุมตนเองและจัดหารหัสสำหรับพล็อตการวิเคราะห์แยกวิเคราะห์ เราขอขอบคุณ Yifan Mai สำหรับการสนับสนุนที่เป็นประโยชน์และสมาชิกของกลุ่ม Stanford NLP รวมถึงศูนย์วิจัยโมเดลมูลนิธิ (CRFM) สำหรับข้อเสนอแนะที่เป็นประโยชน์


