relational rnn pytorch
1.0.0
Pytorch中DeepMind的關係復發性神經網絡的實施(Santoro等人,2018年)。
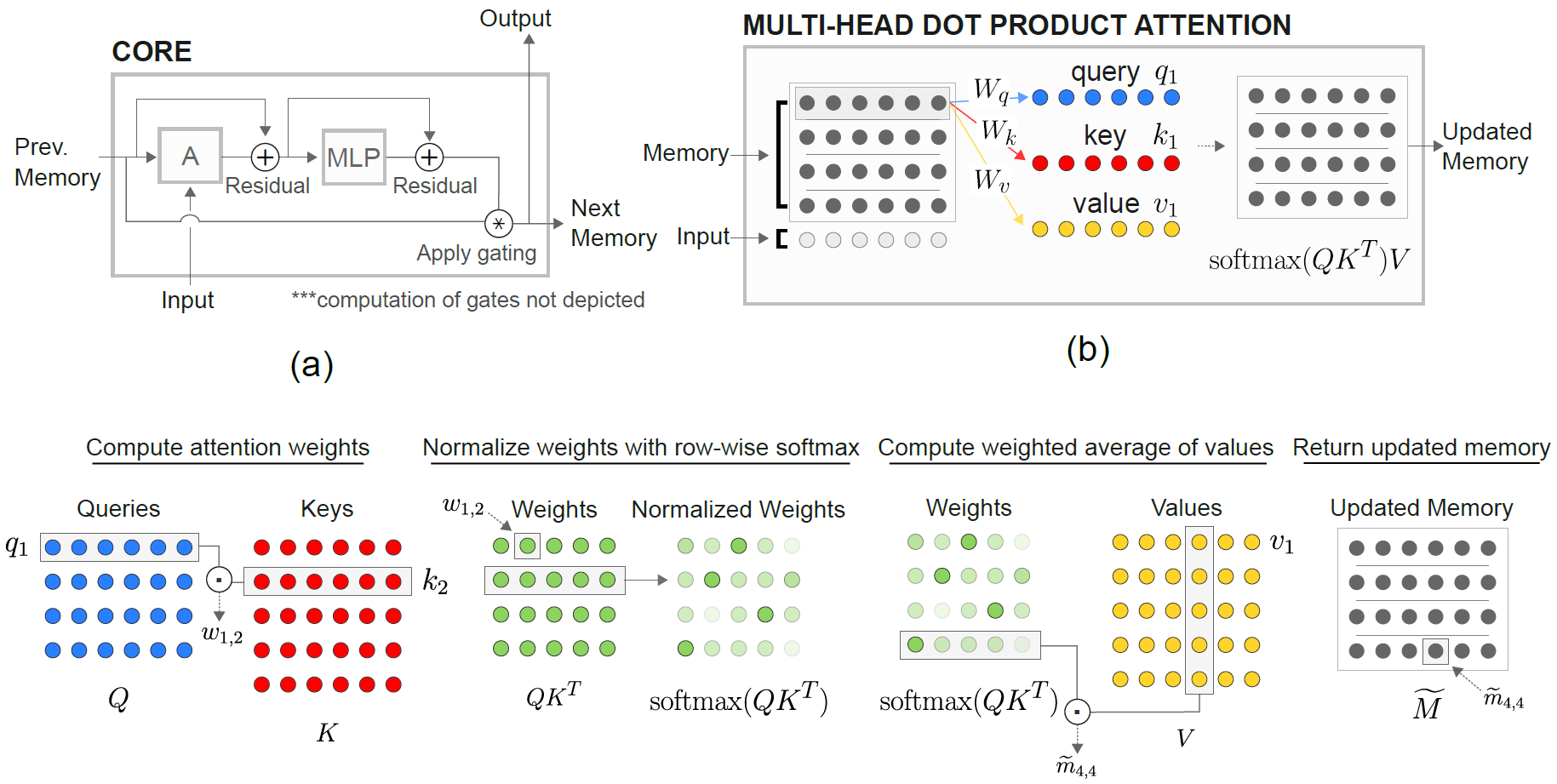
關係內存核心(RMC)模塊最初來自官方十四行詩實現。但是,目前,它們沒有提供完整的語言建模基準代碼。
此存儲庫是RMC的一個港口,並帶有其他評論。它具有成熟的單詞語言建模基準與傳統LSTM。
它支持任何基於單詞令牌的文本數據集,包括Wikitext-2和Wikitext-103。
RMC和LSTM型號都均支持自適應SoftMax,以減少大量詞彙數據集的記憶使用。 RMC支持Pytorch的DataParallel ,因此您可以輕鬆地使用多GPU設置進行實驗。
基準代碼是由官方的pytorch單詞語言模型示例固定的
它還具有紙張中最遠的合成任務(見下文)。
Pytorch 0.4.1或更高版本(在1.0.0測試)&Python 3.6
python train_rmc.py --cuda用於使用GPU進行RMC的全面培訓和測試。
python train_rmc.py --cuda --adaptivesoftmax --cutoffs 1000 5000 20000如果使用大型詞彙數據集(如Wikitext-103)來適合VRAM中的所有啟動器。
python generate_rmc.py --cuda用於從訓練的模型中生成句子。
python train_rnn.py --cuda與GPU一起進行傳統RNN的完整培訓和測試。
RMC和LSTM的所有默認超參數都是使用Wikitext-2進行兩週實驗的結果。
使用Wikitext-2和Wikitext-103測試。 Wikitext-2捆綁在一起。
在./data內部創建一個子文件夾,然後將Word-Level train.txt , valid.txt和test.txt放置在子文件夾中。
指定--data=(subfolder name) ,您可以使用。
該代碼在第一次訓練中執行令牌化,並且該語料庫被保存為pickle 。第一次運行後,代碼將加載pickle文件。
RMC和LSTM都有〜11m參數。有關超參數的詳細信息,請參考培訓代碼。
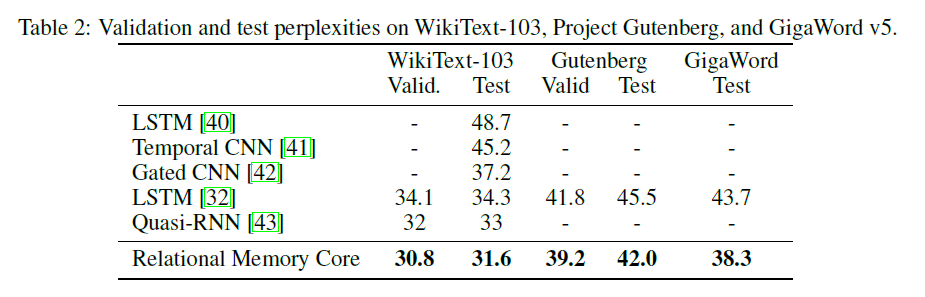
| 型號 | 有效的困惑 | 測試困惑 | 向前通過MS/批次(Titan XP) | 正向通行證MS/批次(Titan V) |
|---|---|---|---|---|
| LSTM(cudnn) | 111.31 | 105.56 | 26〜27 | 40〜41 |
| LSTM(用於循環) | 和cudnn相同 | 和cudnn相同 | 30〜31 | 60〜61 |
| RMC | 112.77 | 107.21 | 110〜130 | 220〜230 |
RMC可以達到與LSTM相當的性能(具有大量的超參數搜索),但事實證明,RMC非常慢。每次步驟的多頭自我注意力可能是這裡的罪魁禍首。使用LSTMCELL進行循環(RMC的更“公平”的基準)會減慢向前傳球,但它仍然更快。
另請注意,就速度而言,RMC的超參數是最糟糕的情況,因為它使用了單個內存插槽(如論文中所述),並且沒有從多插槽內存中的行分享分享中受益。
這裡有趣的是,泰坦V中的速度比泰坦XP慢。原因可能是模型相對較小,並且模型經常調用小型線性操作。
也許Titan XP(〜1,900MHz解鎖的CUDA時鐘速度與Titan V的1,335MHz限制)受益於此類工作量。也許Titan V的CUDA內核發射潛伏期對於模型中的OPS較高。
我不是Cuda細節的專家。請分享您的結果!
注意參數傾向於過度擬合Wikitext-2。減少過度護理器以供注意(key_size)可以打擊過度擬合。
在SoftMax(如LSTM ONE)之前,在輸出logit上塗抹掉落有助於防止過度擬合。
| 嵌入式和頭部尺寸 | #頭 | 注意MLP層 | 鑰匙尺寸 | 輸出處輟學 | 內存插槽 | 測試ppl |
|---|---|---|---|---|---|---|
| 128 | 4 | 3 | 128 | 不 | 1 | 128.81 |
| 128 | 4 | 3 | 128 | 不 | 1 | 128.81 |
| 128 | 8 | 3 | 128 | 不 | 1 | 141.84 |
| 128 | 4 | 3 | 32 | 不 | 1 | 123.26 |
| 128 | 4 | 3 | 32 | 是的 | 1 | 112.4 |
| 128 | 4 | 3 | 64 | 不 | 1 | 124.44 |
| 128 | 4 | 3 | 64 | 是的 | 1 | 110.16 |
| 128 | 4 | 2 | 64 | 是的 | 1 | 111.67 |
| 64 | 4 | 3 | 64 | 是的 | 1 | 133.68 |
| 64 | 4 | 3 | 32 | 是的 | 1 | 135.93 |
| 64 | 4 | 3 | 64 | 是的 | 4 | 137.93 |
| 192 | 4 | 3 | 64 | 是的 | 1 | 107.21 |
| 192 | 4 | 3 | 64 | 是的 | 4 | 114.85 |
| 256 | 4 | 3 | 256 | 不 | 1 | 194.73 |
| 256 | 4 | 3 | 64 | 是的 | 1 | 126.39 |
原始RMC紙呈現Wikitext-103結果,其型號和批量尺寸較大(6 Tesla P100,每個尺寸為64批量,總計384。ouch)。
使用完整的SoftMax很容易吹動VRAM。強烈建議使用--adaptivesoftmax 。如果使用--adaptivesoftmax ,則應正確提供--cutoffs 。請參閱原始API說明
我沒有這樣的硬件,我的資源太有限了,無法進行實驗。基準結果或其他任何貢獻非常歡迎!
該任務的目的是:給定k隨機標記(從1到k)d維向量,確定哪個是向量M的最遠的向量。 (答案是從1到k的整數)。
本文中的具體任務是:給定8個標記為16維向量,這是向量m的第n個最遠的向量?向量被隨機標記,因此模型必須認識到MTH向量是標記為M的向量,而不是輸入中MTH位置中的向量。
該模型的輸入包括每個示例的8個40維向量。這些40維矢量的結構是這樣的:
[(vector 1) (label: which vector is it, from 1 to 8, one-hot encoded) (N, one-hot encoded) (M, one-hot encoded)]
python train_nth_farthest.py --cuda用於訓練和測試GPU最遠的任務。
它使用relational_rnn_general.py中的RelationalMemory類,該類是relational_rnn_models.py的一個版本,而沒有語言模型特定代碼。
有關超參數值的詳細信息,請參考train_nth_farthest.py 。這些是從論文中的附錄A1和十四行詩實施中獲取的。
注意:按照十四行詩的實現,每個時期都會生成新的示例。這似乎與論文一致,該論文未指定所使用的示例數量。
該模型永遠接受了單個Titan XP GPU的培訓,直到達到91%的測試準確性。以下是3個獨立運行的結果: 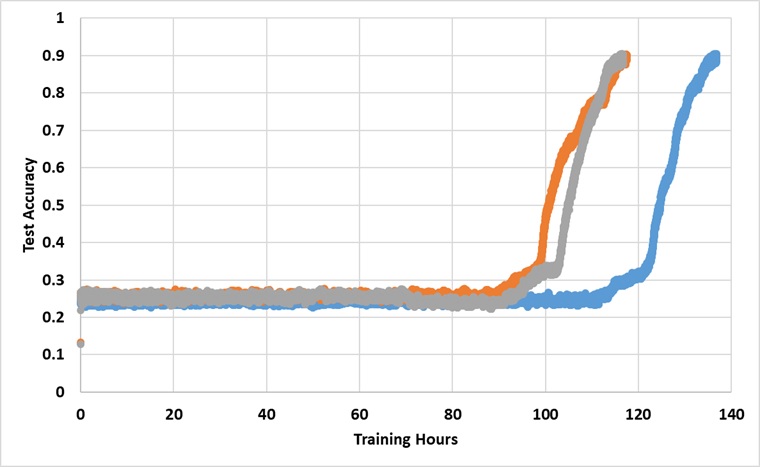
如果訓練足夠長的時間,該模型確實打破了25%的障礙,但是壁時鐘時間大約比論文中報導的時間長2至3倍。
嘗試不同的超參數


