relational rnn pytorch
1.0.0
Pytorch에서 DeepMind의 관계형 재발 신경 네트워크 (Santoro et al. 2018)의 구현.
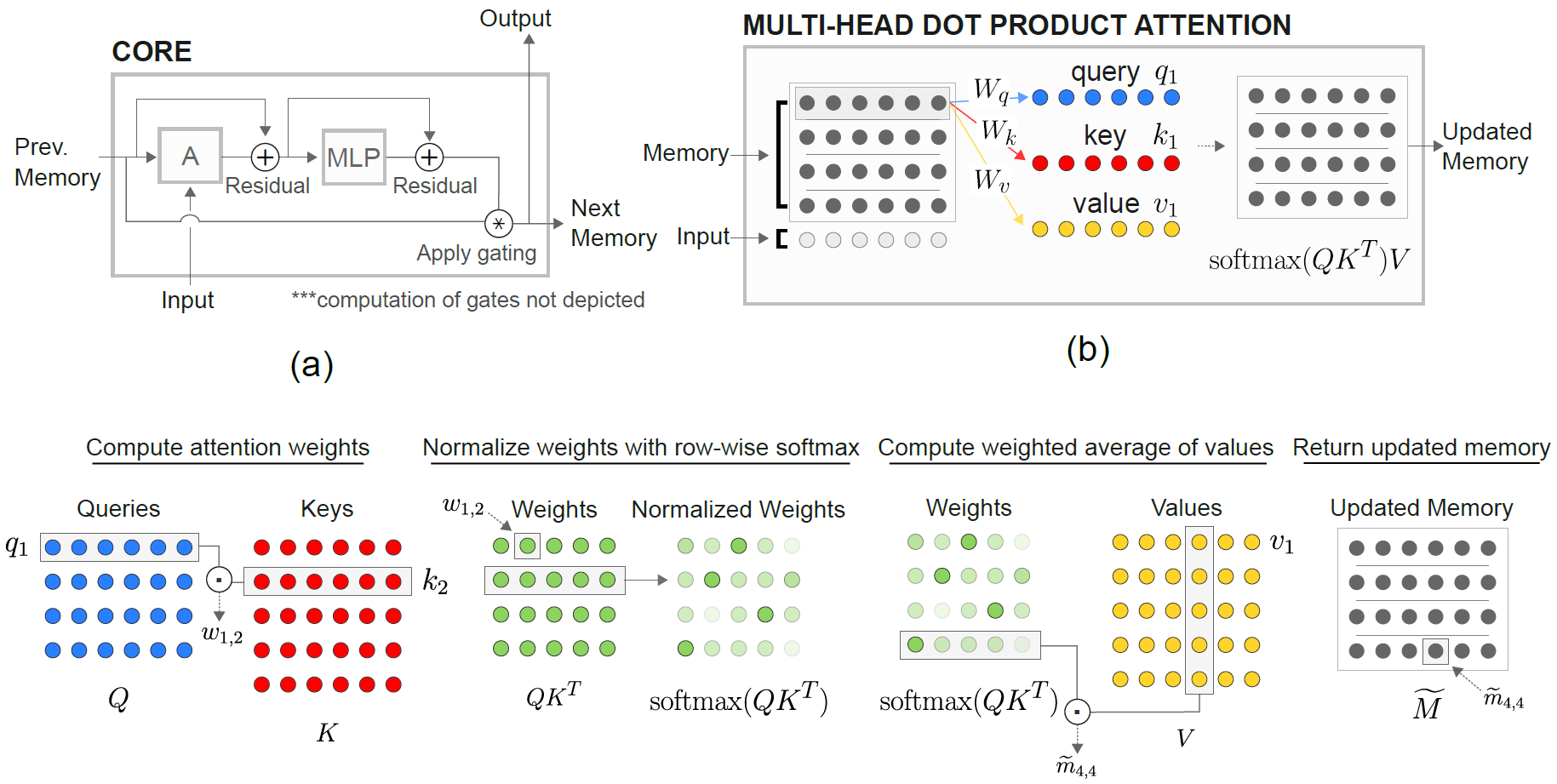
RMC (Relational Memory Core) 모듈은 원래 공식 소네트 구현에서 나온 것입니다. 그러나 현재는 전체 언어 모델링 벤치 마크 코드를 제공하지 않습니다.
이 repo는 추가 의견이있는 RMC 포트입니다. 본격적인 단어 언어 모델링 벤치 마크와 전통적인 LSTM이 특징입니다.
Wikitext-2 및 Wikitext-103을 포함한 임의의 단어 토큰 기반 텍스트 데이터 세트를 지원합니다.
RMC & LSTM 모델 모두 대규모 어휘 데이터 세트의 메모리 사용량이 훨씬 낮은 적응 형 SoftMax를 지원합니다. RMC는 Pytorch의 DataParallel 지원하므로 멀티 GPU 설정으로 쉽게 실험 할 수 있습니다.
벤치 마크 코드는 공식적인 Pytorch Word-Language-Model 예제에서 열심히 고정됩니다
또한 논문에서 가장 먼 합성 작업이 특징입니다 (아래 참조).
Pytorch 0.4.1 이상 (1.0.0에서 테스트) 및 Python 3.6
python train_rmc.py --cuda .
python train_rmc.py --cuda --adaptivesoftmax --cutoffs 1000 5000 20000 대형 어휘 데이터 세트 (Wikitext-103과 같은)를 사용하여 VRAM의 모든 텐서에 맞습니다.
python generate_rmc.py --cuda .
python train_rnn.py --cuda .
RMC & LSTM의 모든 기본 하이퍼 파라미터는 Wikitext-2를 사용한 2 주 실험의 결과입니다.
Wikitext-2 및 Wikitext-103으로 테스트. Wikitext-2가 번들로 제공됩니다.
./data 내부에서 하위 폴더를 만들고 단어 수준 train.txt , valid.txt 및 test.txt 하위 폴더 안에 배치하십시오.
--data=(subfolder name) 를 지정하면 당신은 가기에 좋습니다.
이 코드는 첫 번째 훈련 실행에서 토큰 화를 수행하고 코퍼스는 pickle 로 저장됩니다. 코드는 첫 번째 실행 후 pickle 파일을로드합니다.
RMC & LSTM에는 ~ 11m 매개 변수가 있습니다. 하이퍼 파라미터에 대한 자세한 내용은 교육 코드를 참조하십시오.
| 모델 | 유효한 당황 | 당혹감을 테스트하십시오 | 포워드 패스 MS/배치 (Titan XP) | 포워드 패스 MS/배치 (Titan V) |
|---|---|---|---|---|
| LSTM (CUDNN) | 111.31 | 105.56 | 26 ~ 27 | 40 ~ 41 |
| LSTM (루프 용) | Cudnn과 동일합니다 | Cudnn과 동일합니다 | 30 ~ 31 | 60 ~ 61 |
| RMC | 112.77 | 107.21 | 110 ~ 130 | 220 ~ 230 |
RMC는 LSTM과 비슷한 성능에 도달 할 수 있지만 (과도한 파라미터 검색을 통해) RMC는 매우 느린다는 것이 밝혀졌습니다. 매번 단계에서 멀티 헤드 자체 변환이 여기에서 범인 일 수 있습니다. For Loop (RMC의 "공정한"벤치 마크)와 함께 LSTMCELL을 사용하면 전진 패스가 느려지지만 여전히 훨씬 빠릅니다.
또한 RMC의 하이퍼 파라미터는 속도 측면에서 최악의 시나리오입니다. 단일 메모리 슬롯 (용지에 설명 된 바와 같이)을 사용했으며 멀티 슬롯 메모리의 연속 무게 공유의 혜택을 얻지 못했기 때문입니다.
여기서 흥미로운 것은 Titan XP보다 Titan V에서 속도가 느리다는 것입니다. 그 이유는 모델이 비교적 작고 모델이 작은 선형 작업을 자주 호출하기 때문일 수 있습니다.
아마도 Titan XP (~ 1,900MHz는 CUDA 클럭 속도의 잠금 해제 vs. Titan V의 1,335MHz 제한)는 이러한 종류의 워크로드에서 이점을 얻을 수 있습니다. 또는 Titan V의 Cuda 커널 런칭 대기 시간이 모델의 OPS에 대해 더 높을 수 있습니다.
나는 Cuda의 세부 사항에 대한 전문가가 아닙니다. 결과를 공유하십시오!
주의 매개 변수는 wikitext-2에 과잉 피해를 입는 경향이 있습니다. 주의를 끌기 위해 하이퍼 패터너를 줄이면 (key_size) 과적으로 대항 할 수 있습니다.
SoftMax (LSTM One과 같은) 앞에 출력 로짓에 드롭 아웃을 적용하면 과적으로 적합성을 방지하는 데 도움이되었습니다.
| 포함 및 헤드 크기 | # 헤드 | 주의 MLP 층 | 키 크기 | 출력에서의 드롭 아웃 | 메모리 슬롯 | 테스트 ppl |
|---|---|---|---|---|---|---|
| 128 | 4 | 3 | 128 | 아니요 | 1 | 128.81 |
| 128 | 4 | 3 | 128 | 아니요 | 1 | 128.81 |
| 128 | 8 | 3 | 128 | 아니요 | 1 | 141.84 |
| 128 | 4 | 3 | 32 | 아니요 | 1 | 123.26 |
| 128 | 4 | 3 | 32 | 예 | 1 | 112.4 |
| 128 | 4 | 3 | 64 | 아니요 | 1 | 124.44 |
| 128 | 4 | 3 | 64 | 예 | 1 | 110.16 |
| 128 | 4 | 2 | 64 | 예 | 1 | 111.67 |
| 64 | 4 | 3 | 64 | 예 | 1 | 133.68 |
| 64 | 4 | 3 | 32 | 예 | 1 | 135.93 |
| 64 | 4 | 3 | 64 | 예 | 4 | 137.93 |
| 192 | 4 | 3 | 64 | 예 | 1 | 107.21 |
| 192 | 4 | 3 | 64 | 예 | 4 | 114.85 |
| 256 | 4 | 3 | 256 | 아니요 | 1 | 194.73 |
| 256 | 4 | 3 | 64 | 예 | 1 | 126.39 |
오리지널 RMC 용지는 더 큰 모델 및 배치 크기 (6 개의 Tesla P100, 각각 64 개의 배치 크기, 따라서 총 384. OUCH)를 가진 Wikitext-103 결과를 나타냅니다.
완전한 SoftMax를 사용하면 VRAM을 쉽게 날려 버릴 수 있습니다. --adaptivesoftmax 사용을 적극 권장합니다. --adaptivesoftmax 사용하는 경우 --cutoffs 올바르게 제공해야합니다. 원래 API 설명을 참조하십시오
나는 그러한 하드웨어가없고 내 리소스가 실험을하기에는 너무 제한되어 있습니다. 벤치 마크 결과 또는 기타 기부금은 매우 환영합니다!
작업의 목적은 다음과 같습니다. k가 무작위로 라벨링 된 (1에서 k까지) d 차원 벡터가 주어지면 벡터 M에서 가장 먼 벡터가 무엇인지 식별하십시오 (답은 1에서 k까지의 정수입니다.)
논문의 특정 작업은 다음과 같습니다. 8 개의 라벨링 된 16 차원 벡터가 주어졌으며, 이는 벡터 M에서 가장 먼 벡터입니까? 벡터는 무작위로 라벨링되므로 모델은 MTH 벡터가 입력의 MTH 위치에서 벡터와 달리 M으로 표시되는 벡터임을 인식해야합니다.
모델에 대한 입력은 각 예제에 대해 8 개의 40 차원 벡터로 구성됩니다. 이 40 차원 벡터 각각은 다음과 같이 구성됩니다.
[(vector 1) (label: which vector is it, from 1 to 8, one-hot encoded) (N, one-hot encoded) (M, one-hot encoded)]
python train_nth_farthest.py --cuda .
이것은 relational_rnn_general.py 의 RelationalMemory 클래스를 사용합니다. 이는 언어 모델링 특정 코드가없는 relational_rnn_models.py 버전입니다.
하이퍼 파라미터 값에 대한 자세한 내용은 train_nth_farthest.py 를 참조하십시오. 이들은 논문의 부록 A1과 초 파라미터 값이 논문에 나오지 않을 때 소네트 구현에서 가져옵니다.
참고 : 소네트 구현에서와 같이 새로운 예제가 에포크 당 생성됩니다. 이것은 사용 된 예제의 수를 지정하지 않는 용지와 일치하는 것으로 보입니다.
이 모델은 91%의 테스트 정확도에 도달 할 때까지 영원히 단일 타이탄 XP GPU로 교육을 받았습니다. 다음은 3 개의 독립적 인 실행이있는 결과입니다. 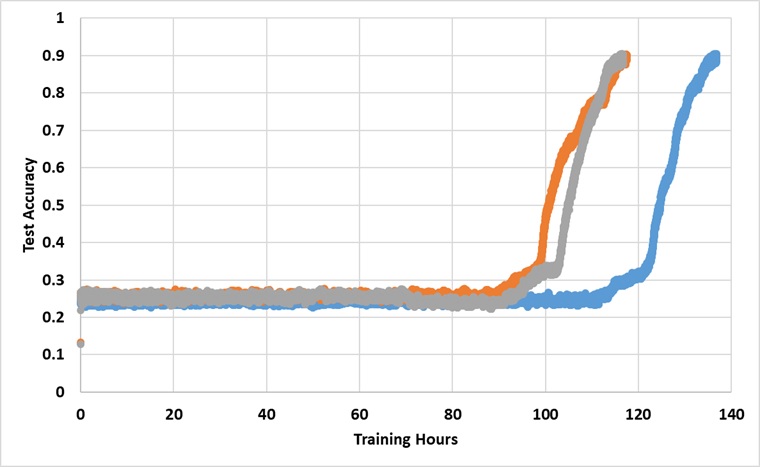
이 모델은 충분히 길게 훈련하면 25% 장벽을 깨뜨리지 만 벽시계 시간은 논문에보고 된 것보다 대략 2 ~ 3 배 이상입니다.
다른 과파리터로 실험하십시오


