relational rnn pytorch
1.0.0
Une mise en œuvre des réseaux de neurones récurrents relationnels de DeepMind (Santoro et al. 2018) dans Pytorch.
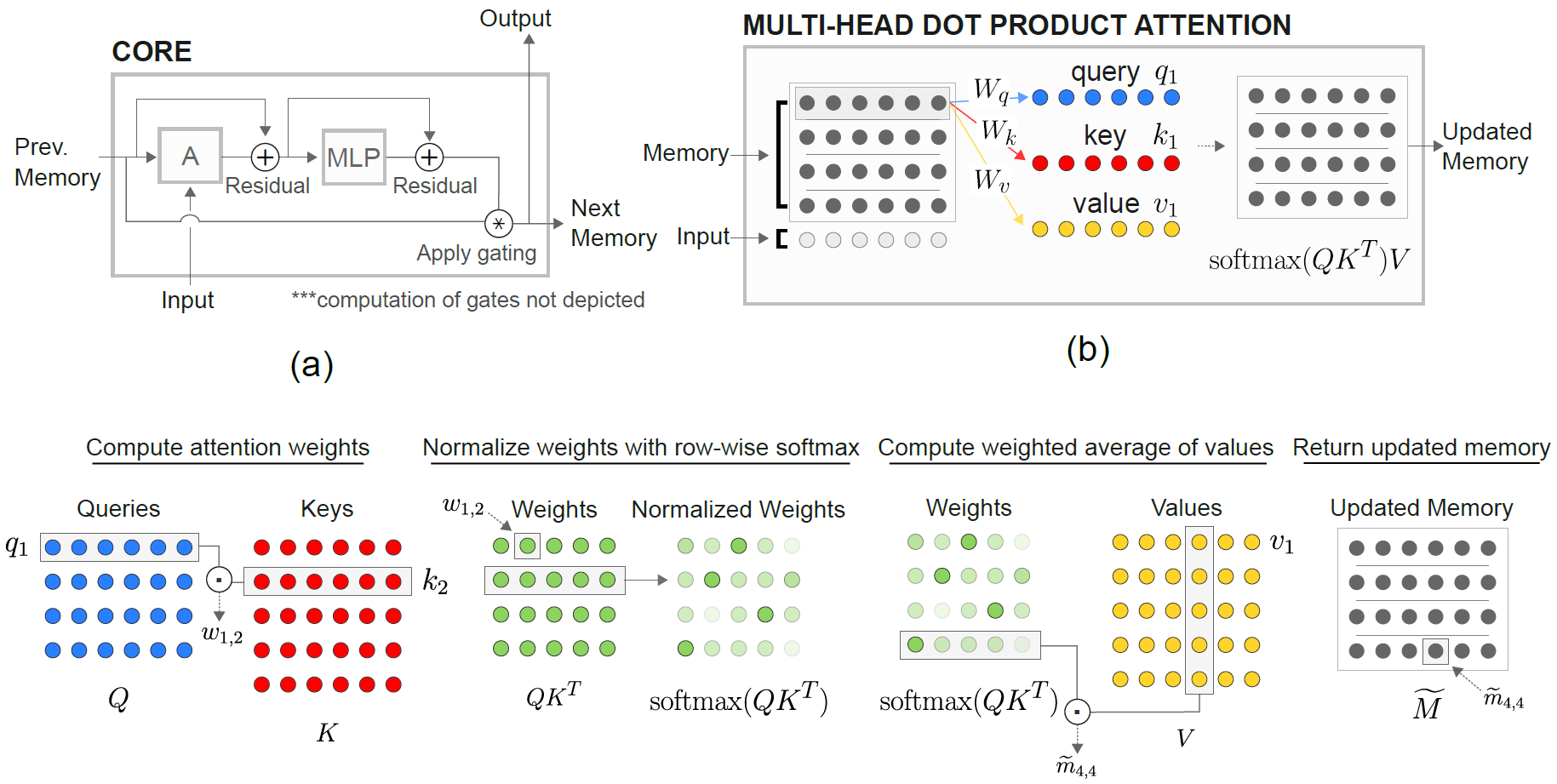
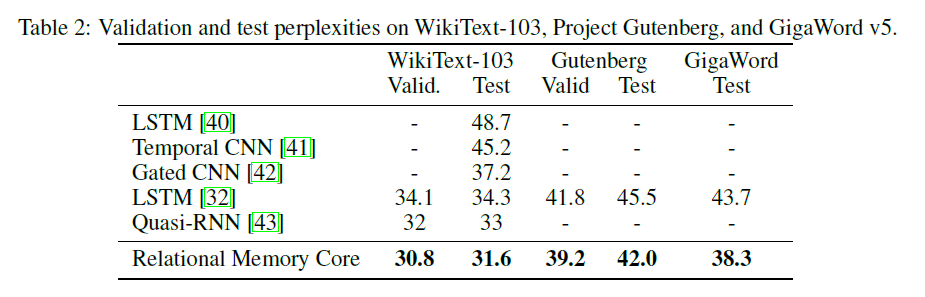
Le module RMA de mémoire relationnelle (RMC) est originaire de la mise en œuvre officielle du sonnet. Cependant, ils ne fournissent actuellement pas de code de référence de modélisation de la langue complète.
Ce repo est un port de RMC avec des commentaires supplémentaires. Il dispose d'une référence de modélisation de langage de mots à part entière par rapport à LSTM traditionnel.
Il prend en charge tout ensemble de données de texte basé sur des jetons de jeton arbitraire, y compris WikiteXt-2 et Wikitext-103.
Les modèles RMC et LSTM prennent en charge Adaptive Softmax pour une utilisation de la mémoire beaucoup plus faible de l'ensemble de données de vocabulaire grand. RMC prend en charge DataParallel de Pytorch, vous pouvez donc facilement expérimenter une configuration multi-GPU.
Les codes de référence sont en fourche dure à partir de l'exemple officiel du modèle de langage de mots pytorch
Il dispose également d'une tâche synthétique la plus éloignée de l'article (voir ci-dessous).
Pytorch 0.4.1 ou ultérieure (testé sur 1.0.0) et Python 3.6
python train_rmc.py --cuda pour la formation complète et le test de RMC avec GPU.
python train_rmc.py --cuda --adaptivesoftmax --cutoffs 1000 5000 20000 Si vous utilisez un grand ensemble de données de vocabulaire (comme WikiteXt-103) pour s'adapter à tous les tenseurs du VRAM.
python generate_rmc.py --cuda pour générer des phrases à partir du modèle formé.
python train_rnn.py --cuda pour la formation complète et le test de RNN traditionnel avec GPU.
Tous les hyperparamètres par défaut de RMC & LSTM sont des résultats d'une expérience de deux semaines utilisant Wikitext-2.
Testé avec wikitext-2 et wikitext-103. Wikitext-2 est regroupé.
Créez un sous-dossier à l'intérieur ./data et placez Word-Level train.txt , valid.txt et test.txt à l'intérieur du sous-dossier.
Spécifiez --data=(subfolder name) et vous êtes prêt à y aller.
Le code effectue la tokenisation lors de la première course d'entraînement, et le corpus est enregistré en pickle . Le code chargera le fichier pickle après la première exécution.
RMC et LSTM ont des paramètres ~ 11M. Veuillez vous référer au code de formation pour plus de détails sur les hyperparamètres.
| Modèles | Perplexité valide | Tester la perplexité | Forward Pass MS / Lot (Titan XP) | Forward Pass MS / Lot (Titan V) |
|---|---|---|---|---|
| Lstm (cudnn) | 111.31 | 105.56 | 26 ~ 27 | 40 ~ 41 |
| LSTM (pour Loop) | Identique à Cudnn | Identique à Cudnn | 30 ~ 31 | 60 ~ 61 |
| RMC | 112.77 | 107.21 | 110 ~ 130 | 220 ~ 230 |
Le RMC peut atteindre une performance comparable à LSTM (avec une recherche hyperparamètre lourde), mais il s'avère que le RMC est très lent. L'auto-atténuer de l'auto-tête à chaque pas peut être le coupable ici. L'utilisation de LSTMCell avec pour Loop (qui est plus "juste" pour RMC) ralentit la passe avant, mais c'est toujours beaucoup plus rapide.
Veuillez également noter que l'hyperparamètre de RMC est un pire scénario en termes de vitesse, car il a utilisé un seul emplacement de mémoire (comme décrit dans l'article) et n'a pas bénéficié d'un partage de poids au niveau de la ligne à partir de la mémoire multi-employés.
Il est intéressant de noter ici que la vitesse est plus lente dans Titan V que Titan XP. La raison pourrait être que les modèles sont relativement petits et que le modèle appelle fréquemment de petites opérations linéaires.
Peut-être que Titan XP (~ 1 900 MHz la vitesse d'horloge CUDA déverrouillée par rapport à la limite de 1 335 MHz de Titan V) profite de ce type de charge de travail. Ou peut-être que la latence de lancement du noyau CUDA de Titan V est plus élevée pour les OP dans le modèle.
Je ne suis pas un expert en détail de Cuda. Veuillez partager vos résultats!
Les paramètres d'attention ont tendance à sur-adapter le wikitext-2. La réduction des hyperparmers pour l'attention (key_size) peut combattre le sur-ajustement.
L'application de dépôt à la logit de sortie avant le softmax (comme le LSTM) a aidé à prévenir le sur-ajustement.
| Embed et taille de tête | # têtes | Attention MLP Couches | taille clé | Dépannage à la sortie | emplacements de mémoire | tester les ppl |
|---|---|---|---|---|---|---|
| 128 | 4 | 3 | 128 | Non | 1 | 128.81 |
| 128 | 4 | 3 | 128 | Non | 1 | 128.81 |
| 128 | 8 | 3 | 128 | Non | 1 | 141.84 |
| 128 | 4 | 3 | 32 | Non | 1 | 123.26 |
| 128 | 4 | 3 | 32 | Oui | 1 | 112.4 |
| 128 | 4 | 3 | 64 | Non | 1 | 124.44 |
| 128 | 4 | 3 | 64 | Oui | 1 | 110.16 |
| 128 | 4 | 2 | 64 | Oui | 1 | 111.67 |
| 64 | 4 | 3 | 64 | Oui | 1 | 133.68 |
| 64 | 4 | 3 | 32 | Oui | 1 | 135.93 |
| 64 | 4 | 3 | 64 | Oui | 4 | 137,93 |
| 192 | 4 | 3 | 64 | Oui | 1 | 107.21 |
| 192 | 4 | 3 | 64 | Oui | 4 | 114.85 |
| 256 | 4 | 3 | 256 | Non | 1 | 194.73 |
| 256 | 4 | 3 | 64 | Oui | 1 | 126.39 |
Le papier RMC d'origine présente Wikitext-103 en résultats avec un modèle et une taille de lot plus grands (6 Tesla P100, chacun avec 64 taille de lot, donc un total de 384. Ouch).
L'utilisation d'un softmax complet souffle facilement le VRAM. L'utilisation --adaptivesoftmax est fortement recommandée. Si vous utilisez --adaptivesoftmax , --cutoffs doit être correctement fourni. Veuillez vous référer à la description de l'API d'origine
Je n'ai pas un tel matériel et ma ressource est trop limitée pour faire les expériences. Le résultat de référence, ou toute autre contribution est la bienvenue!
L'objectif de la tâche est: étant donné k étiqueté au hasard (de 1 à k) les vecteurs D-dimensionnaires, identifiez qui est le nième vecteur le plus éloigné du vecteur M. (La réponse est un entier de 1 à k.)
La tâche spécifique dans l'article est: étant donné 8 vecteurs 16 dimensions étiquetés, qui est le nième vecteur le plus éloigné du vecteur m? Les vecteurs sont étiquetés au hasard afin que le modèle doit reconnaître que le vecteur MTH est le vecteur étiqueté comme M par opposition au vecteur en position MTH dans l'entrée.
L'entrée du modèle comprend 8 vecteurs à 40 dimensions pour chaque exemple. Chacun de ces vecteurs 40 dimensions est structuré comme ceci:
[(vector 1) (label: which vector is it, from 1 to 8, one-hot encoded) (N, one-hot encoded) (M, one-hot encoded)]
python train_nth_farthest.py --cuda pour la formation et les tests sur la nième tâche la plus éloignée avec GPU (s).
Ceci utilise la classe RelationalMemory dans relational_rnn_general.py , qui est une version de relational_rnn_models.py sans le code spécifique de modélisation de la langue.
Veuillez vous référer à train_nth_farthest.py pour plus de détails sur les valeurs d'hyperparamètre. Ceux-ci sont tirés de l'annexe A1 dans le document et de la mise en œuvre du sonnet lorsque les valeurs d'hyperparamètre ne sont pas données dans le document.
Remarque: De nouveaux exemples sont générés par époque comme dans l'implémentation Sonnet. Cela semble être cohérent avec l'article, qui ne spécifie pas le nombre d'exemples utilisés.
Le modèle a été formé avec un seul GPU Titan XP pour toujours jusqu'à ce qu'il atteigne la précision de test de 91%. Vous trouverez ci-dessous les résultats avec 3 courses indépendantes: 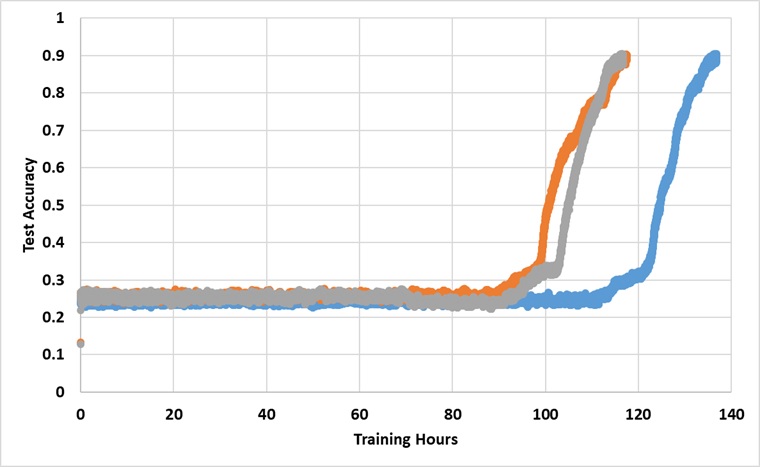
Le modèle brise la barrière de 25% s'il est entraîné assez longtemps, mais le temps d'horloge mural est à peu près de 2 à 3 fois plus long que ceux rapportés dans le document.
Expérimentez avec différents hyperparamètres


