relational rnn pytorch
1.0.0
PytorchにおけるDeepmindのリレーショナルリピュラーニューラルネットワーク(Santoro etal。2018)の実装。
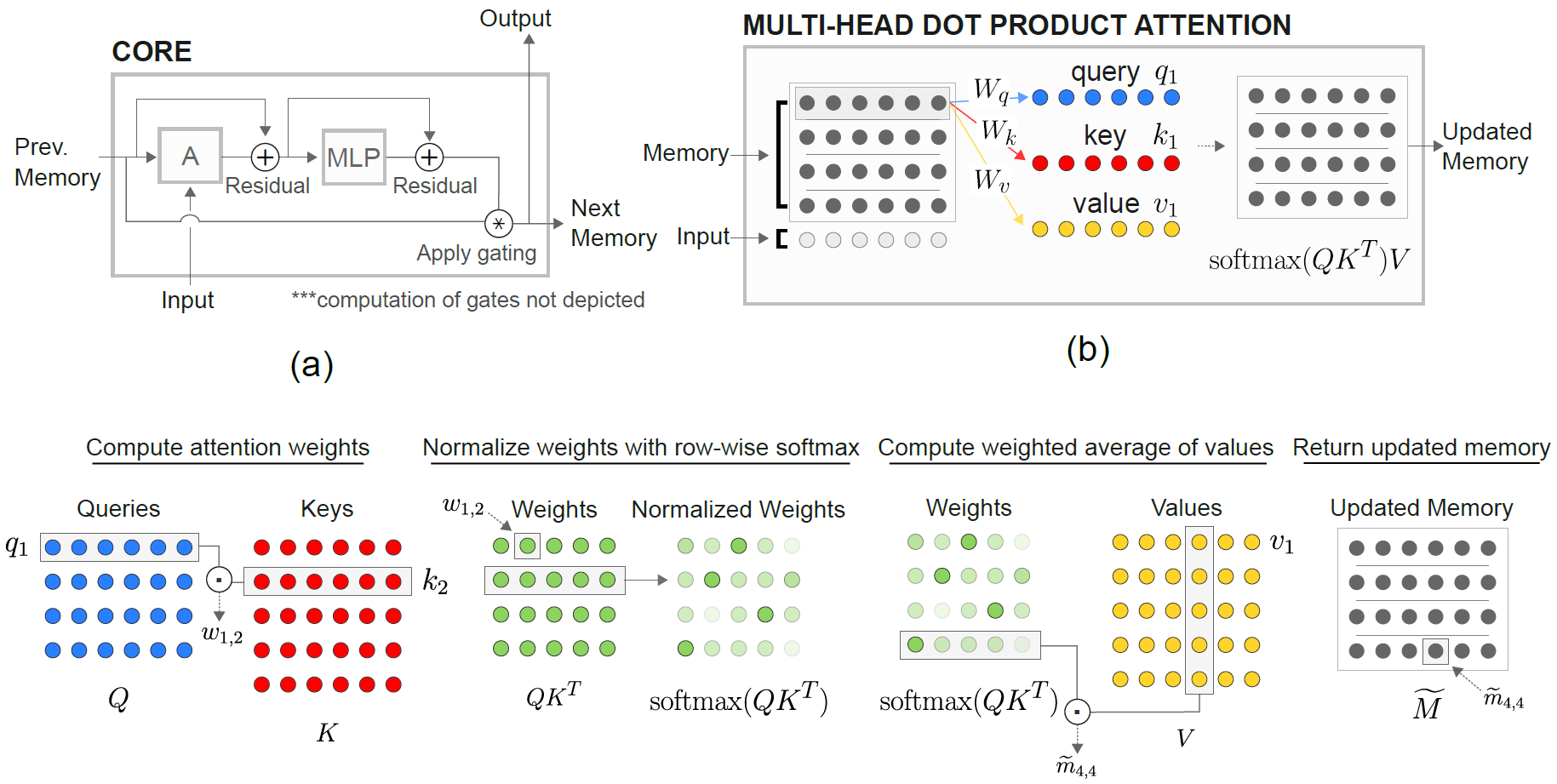
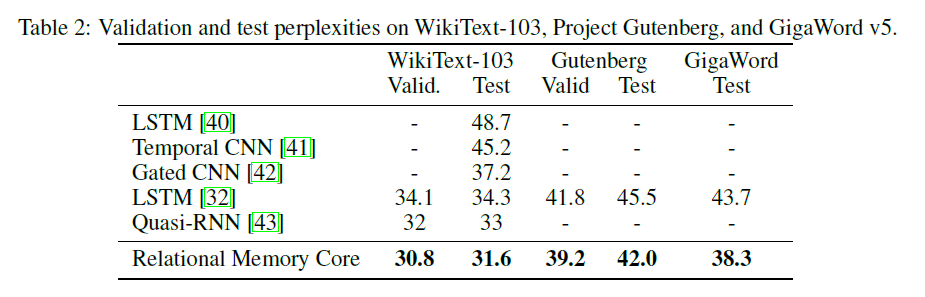
リレーショナルメモリコア(RMC)モジュールは、もともと公式のSonnet実装からのものです。ただし、現在、フル言語モデリングベンチマークコードを提供していません。
このレポは、追加のコメントがあるRMCのポートです。本格的な単語言語モデリングベンチマーク対従来のLSTMを備えています。
wikitext-2&wikitext-103を含む任意の単語トークンベースのテキストデータセットをサポートしています。
両方のRMCおよびLSTMモデルは、大規模な語彙データセットのメモリ使用量がはるかに低いため、適応型ソフトマックスをサポートしています。 RMCはPytorchのDataParallelをサポートするため、Multi-GPUセットアップを簡単に実験できます。
ベンチマークコードは、公式のPytorch Word-Language-Modelの例からハードフォークされています
また、論文からのN番目に遠い合成タスクも備えています(以下を参照)。
Pytorch 0.4.1以降(1.0.0でテスト)&Python 3.6
python train_rmc.py --cuda 。
python train_rmc.py --cuda --adaptivesoftmax --cutoffs 1000 5000 20000
python generate_rmc.py --cuda 。
python train_rnn.py --cuda 。
RMC&LSTMのすべてのデフォルトハイパーパラメーターは、Wikitext-2を使用した2週間の実験の結果です。
wikitext-2およびwikitext-103でテストしました。 wikitext-2がバンドルされています。
./data内にサブフォルダーを作成し、サブフォルダー内にWord-Level train.txt 、 valid.txt 、およびtest.txt配置します。
--data=(subfolder name)を指定すると、行ってもいいです。
コードは最初のトレーニングランでトークン化を実行し、コーパスはpickleとして保存されます。コードは、最初の実行後にpickleファイルをロードします。
RMCとLSTMには両方とも〜11mパラメーターを持っています。ハイパーパラメーターの詳細については、トレーニングコードを参照してください。
| モデル | 有効な困惑 | 困惑をテストします | フォワードパスMS/バッチ(Titan XP) | フォワードパスMS/バッチ(Titan V) |
|---|---|---|---|---|
| LSTM(cudnn) | 111.31 | 105.56 | 26〜27 | 40〜41 |
| LSTM(ループ用) | cudnnと同じです | cudnnと同じです | 30〜31 | 60〜61 |
| RMC | 112.77 | 107.21 | 110〜130 | 220〜230 |
RMCはLSTMに匹敵するパフォーマンスに到達することができます(ハイパーパラメーター検索が重い)が、RMCは非常に遅いことがわかります。ここでの段階でのマルチヘッドの自己関節が犯人かもしれません。 forループ(RMCの「より公平な」ベンチマーク)でLSTMCellを使用すると、フォワードパスが遅くなりますが、それでもはるかに高速です。
また、RMCのハイパーパラメーターは、単一のメモリスロット(論文で説明されているように)を使用し、マルチスロットメモリからの列の重量共有の恩恵を受けなかったため、速度の面で最悪のシナリオであることに注意してください。
ここで注目すべき興味深いのは、タイタンVの速度がタイタンXPよりも遅いことです。その理由は、モデルが比較的小さく、モデルが頻繁に小さな線形操作を呼び出すためかもしれません。
たぶん、Titan XP(〜1,900MHzロック解除されたCUDAクロック速度対タイタンVの1,335MHzリミット)は、この種のワークロードから利益を得ています。または、Titan VのCuda Kernelの起動レイテンシは、モデルのOPSの方が高くなるかもしれません。
私はcudaの詳細の専門家ではありません。結果を共有してください!
注意パラメーターは、wikitext-2に過剰にでもきつけがあります。注意のためにハイパーパーメーターを減らすこと(key_size)は、過剰フィットと戦うことができます。
SoftMax(LSTM Oneのように)の前に出力ロジットでドロップアウトを適用すると、過剰適合を防ぐことができました。
| 埋め込みとヘッドサイズ | #ヘッド | 注意MLPレイヤー | キーサイズ | 出力でのドロップアウト | メモリスロット | テストppl |
|---|---|---|---|---|---|---|
| 128 | 4 | 3 | 128 | いいえ | 1 | 128.81 |
| 128 | 4 | 3 | 128 | いいえ | 1 | 128.81 |
| 128 | 8 | 3 | 128 | いいえ | 1 | 141.84 |
| 128 | 4 | 3 | 32 | いいえ | 1 | 123.26 |
| 128 | 4 | 3 | 32 | はい | 1 | 112.4 |
| 128 | 4 | 3 | 64 | いいえ | 1 | 124.44 |
| 128 | 4 | 3 | 64 | はい | 1 | 110.16 |
| 128 | 4 | 2 | 64 | はい | 1 | 111.67 |
| 64 | 4 | 3 | 64 | はい | 1 | 133.68 |
| 64 | 4 | 3 | 32 | はい | 1 | 135.93 |
| 64 | 4 | 3 | 64 | はい | 4 | 137.93 |
| 192 | 4 | 3 | 64 | はい | 1 | 107.21 |
| 192 | 4 | 3 | 64 | はい | 4 | 114.85 |
| 256 | 4 | 3 | 256 | いいえ | 1 | 194.73 |
| 256 | 4 | 3 | 64 | はい | 1 | 126.39 |
元のRMCペーパーでは、より大きなモデルとバッチサイズ(6テスラP100、それぞれ64バッチサイズのテスラP100なので、合計384。
完全なソフトマックスを使用すると、VRAMが簡単に吹き飛ばされます。 --adaptivesoftmaxを使用することを強くお勧めします。 --adaptivesoftmaxを使用している場合、 --cutoffs適切に提供する必要があります。元のAPI説明を参照してください
私はそのようなハードウェアを持っていません、そして私のリソースは限られすぎて、実験をすることができません。ベンチマークの結果、またはその他の貢献は大歓迎です!
タスクの目的は、次のとおりです。Kをランダムにラベル付け(1からk)D次元ベクトルを示すと、ベクターMから最も遠いベクトルであるものを識別します(答えは1からkまでの整数です。)
論文の特定のタスクは次のとおりです。16次元ベクトルとラベル付けされた8つのラベルが付いています。ベクトルはランダムに標識されているため、モデルは、MTHベクトルが入力のMTH位置のベクトルとは対照的に、Mとラベル付けされたベクトルであることを認識する必要があります。
モデルへの入力は、各例の8つの40次元ベクトルを含む。これらの40次元ベクトルのそれぞれは、次のように構成されています。
[(vector 1) (label: which vector is it, from 1 to 8, one-hot encoded) (N, one-hot encoded) (M, one-hot encoded)]
python train_nth_farthest.py --cuda gpu(s)で最も遠いタスクでトレーニングとテストのためのクーダ。
これは、 relational_rnn_general.pyのRelationalMemoryクラスを使用します。これは、言語をモデル化する特定のコードなしでrelational_rnn_models.pyのバージョンです。
HyperParameter値の詳細については、 train_nth_farthest.pyを参照してください。これらは、論文の付録A1と、ハイパーパラメーターの値が論文で示されていない場合のSonnet実装から取得されます。
注:ソネットの実装のように、エポックごとに新しい例が生成されます。これは、使用される例の数を指定していない論文と一致しているようです。
このモデルは、91%のテスト精度に達するまで、1つのタイタンXP GPUで永久にトレーニングされています。以下は、3つの独立した実行の結果です。 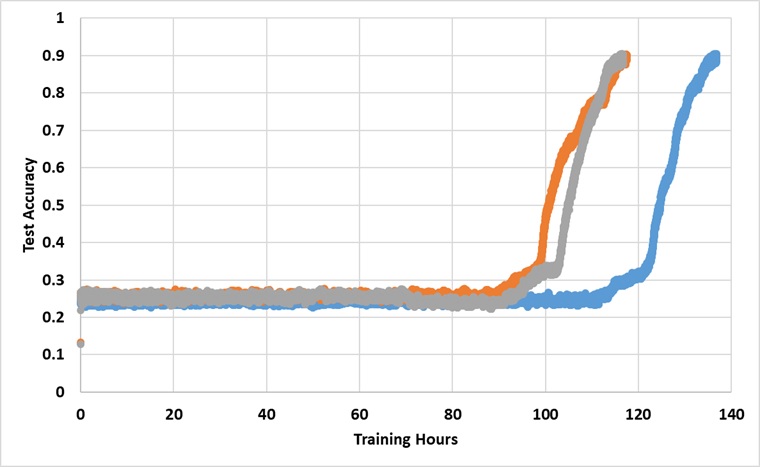
このモデルは、十分に長く訓練されている場合、25%の障壁を破りますが、壁の時計時間は、論文で報告されているものよりも約2〜3倍以上長くなります。
さまざまなハイパーパラメーターを試してください


