relational rnn pytorch
1.0.0
Implementasi Jaringan Saraf Berulang Relasional DeepMind (Santoro et al. 2018) di Pytorch.
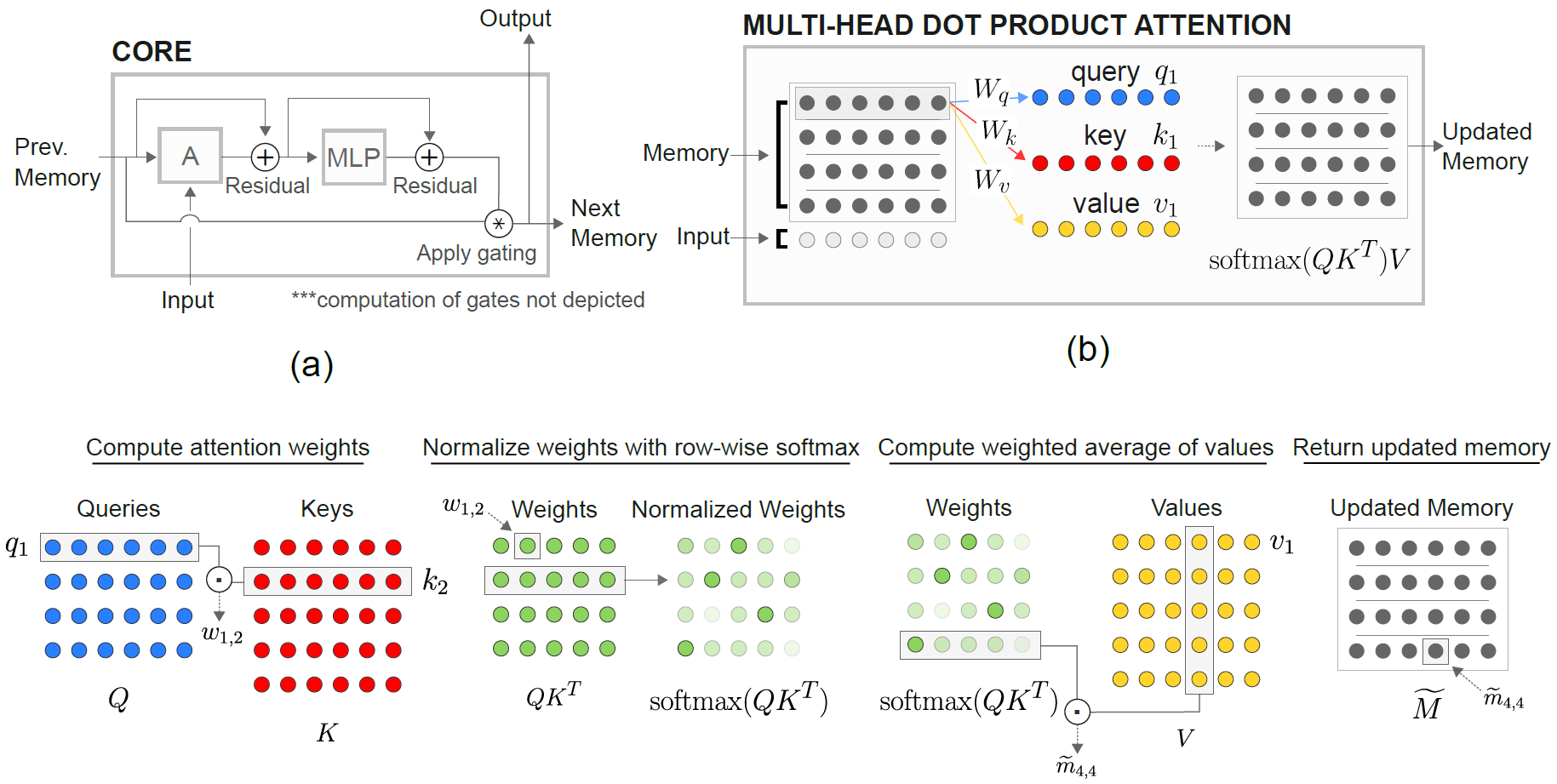
Modul Relational Memory Core (RMC) berasal dari implementasi soneta resmi. Namun, saat ini mereka tidak memberikan kode tolok ukur pemodelan bahasa penuh.
Repo ini adalah port RMC dengan komentar tambahan. Ini fitur patokan pemodelan bahasa kata penuh vs LSTM tradisional.
Ini mendukung dataset teks berbasis token yang sewenang-wenang, termasuk Wikitext-2 & Wikitext-103.
Kedua model RMC & LSTM mendukung softmax adaptif untuk penggunaan memori yang jauh lebih rendah dari dataset kosakata besar. RMC mendukung DataParallel Pytorch, sehingga Anda dapat dengan mudah bereksperimen dengan pengaturan multi-GPU.
Kode Benchmark dipalsukan keras dari contoh model bahasa-kata Pytorch resmi
Ini juga memiliki tugas sintetis terjauh ke-n dari kertas (lihat di bawah).
Pytorch 0.4.1 atau lebih baru (diuji pada 1.0.0) & Python 3.6
python train_rmc.py --cuda untuk pelatihan penuh & uji run RMC dengan GPU.
python train_rmc.py --cuda --adaptivesoftmax --cutoffs 1000 5000 20000 Jika menggunakan dataset kosakata besar (seperti wikuxt-103) agar sesuai dengan semua tensor di VRAM.
python generate_rmc.py --cuda untuk menghasilkan kalimat dari model terlatih.
python train_rnn.py --cuda untuk pelatihan penuh & uji coba RNN tradisional dengan GPU.
Semua hyperparameter default RMC & LSTM adalah hasil dari percobaan dua minggu menggunakan Wikuxt-2.
Diuji dengan Wikuxt-2 dan Wikuxt-103. Wikuxt-2 dibundel.
Buat subfolder di dalam ./data dan tempatkan level-level train.txt , valid.txt , dan test.txt di dalam subfolder.
Tentukan --data=(subfolder name) dan Anda siap melakukannya.
Kode ini melakukan tokenisasi pada pelatihan pertama, dan corpus disimpan sebagai pickle . Kode akan memuat file pickle setelah menjalankan pertama.
Baik RMC & LSTM memiliki parameter ~ 11m. Silakan merujuk ke kode pelatihan untuk detail tentang hyperparameters.
| Model | Kebingungan yang valid | Uji kebingungan | Forward Pass MS/Batch (Titan XP) | Forward Pass MS/Batch (Titan V) |
|---|---|---|---|---|
| LSTM (CUDNN) | 111.31 | 105.56 | 26 ~ 27 | 40 ~ 41 |
| LSTM (untuk loop) | Sama seperti Cudnn | Sama seperti Cudnn | 30 ~ 31 | 60 ~ 61 |
| RMC | 112.77 | 107.21 | 110 ~ 130 | 220 ~ 230 |
RMC dapat mencapai kinerja yang sebanding dengan LSTM (dengan pencarian hiperparameter berat), tetapi ternyata RMC sangat lambat. Perhatian multi-head pada setiap langkah waktu mungkin adalah pelakunya di sini. Menggunakan LSTMCell dengan untuk loop (yang lebih "adil" untuk RMC) memperlambat umpan ke depan, tetapi masih jauh lebih cepat.
Harap perhatikan juga bahwa hiperparameter untuk RMC adalah skenario terburuk dalam hal kecepatan, karena menggunakan slot memori tunggal (seperti yang dijelaskan dalam makalah) dan tidak mendapat manfaat dari berbagi berat baris dari memori multi-slot.
Menarik untuk dicatat di sini adalah bahwa kecepatannya lebih lambat di Titan V daripada Titan XP. Alasannya mungkin karena modelnya relatif kecil dan modelnya sering memanggil operasi linier kecil.
Mungkin Titan XP (~ 1.900MHz Kecepatan Jam Cuda yang tidak terkunci vs. Batas 1.335MHz Titan V) manfaat dari beban kerja semacam ini. Atau mungkin latensi peluncuran kernel CUDA Titan V lebih tinggi untuk OPS dalam model.
Saya bukan ahli dalam detail CUDA. Tolong bagikan hasil Anda!
Parameter perhatian cenderung overfit wikuxt-2. Mengurangi hyperparmeter untuk perhatian (KEY_SIZE) dapat memerangi overfitting.
Menerapkan dropout pada logit output sebelum softmax (seperti LSTM) membantu mencegah overfitting.
| embed & ukuran kepala | # kepala | Perhatian Lapisan MLP | Ukuran kunci | Dropout saat output | slot memori | uji ppl |
|---|---|---|---|---|---|---|
| 128 | 4 | 3 | 128 | TIDAK | 1 | 128.81 |
| 128 | 4 | 3 | 128 | TIDAK | 1 | 128.81 |
| 128 | 8 | 3 | 128 | TIDAK | 1 | 141.84 |
| 128 | 4 | 3 | 32 | TIDAK | 1 | 123.26 |
| 128 | 4 | 3 | 32 | Ya | 1 | 112.4 |
| 128 | 4 | 3 | 64 | TIDAK | 1 | 124.44 |
| 128 | 4 | 3 | 64 | Ya | 1 | 110.16 |
| 128 | 4 | 2 | 64 | Ya | 1 | 111.67 |
| 64 | 4 | 3 | 64 | Ya | 1 | 133.68 |
| 64 | 4 | 3 | 32 | Ya | 1 | 135.93 |
| 64 | 4 | 3 | 64 | Ya | 4 | 137.93 |
| 192 | 4 | 3 | 64 | Ya | 1 | 107.21 |
| 192 | 4 | 3 | 64 | Ya | 4 | 114.85 |
| 256 | 4 | 3 | 256 | TIDAK | 1 | 194.73 |
| 256 | 4 | 3 | 64 | Ya | 1 | 126.39 |
Kertas RMC asli menyajikan hasil wikuxt-103 dengan model & ukuran batch yang lebih besar (6 Tesla P100, masing-masing dengan ukuran 64 batch, sehingga total 384. Aduh).
Menggunakan softmax penuh dengan mudah meledakkan vram. Menggunakan --adaptivesoftmax sangat dianjurkan. Jika menggunakan --adaptivesoftmax , --cutoffs harus disediakan dengan benar. Silakan merujuk ke deskripsi API asli
Saya tidak memiliki perangkat keras seperti itu dan sumber daya saya terlalu terbatas untuk melakukan eksperimen. Hasil patokan, atau kontribusi lainnya sangat disambut!
Tujuan dari tugas ini adalah: Diberikan k berlabel acak (dari 1 ke k) vektor D-dimensi, identifikasi mana yang merupakan vektor terjauh ke-n dari vektor M. (jawabannya adalah bilangan bulat dari 1 ke k.)
Tugas khusus dalam makalah ini adalah: Diberikan 8 vektor 16-dimensi berlabel, yang merupakan vektor terjauh ke-n dari vektor M? Vektor diberi label secara acak sehingga model harus mengenali bahwa vektor MTH adalah vektor yang diberi label m yang bertentangan dengan vektor pada posisi MTH dalam input.
Input ke model terdiri dari 8 vektor 40-dimensi untuk setiap contoh. Masing-masing vektor 40 dimensi ini disusun seperti ini:
[(vector 1) (label: which vector is it, from 1 to 8, one-hot encoded) (N, one-hot encoded) (M, one-hot encoded)]
python train_nth_farthest.py --cuda untuk pelatihan dan pengujian pada tugas terjauh ke -n dengan GPU (s).
Ini menggunakan kelas RelationalMemory di relational_rnn_general.py , yang merupakan versi relational_rnn_models.py tanpa kode spesifik pemodelan bahasa.
Silakan merujuk ke train_nth_farthest.py untuk detail tentang nilai hyperparameter. Ini diambil dari Lampiran A1 di koran dan dari implementasi Sonnet ketika nilai hyperparameter tidak diberikan dalam makalah.
Catatan: Contoh baru dihasilkan per zaman seperti dalam implementasi sonnet. Ini tampaknya konsisten dengan kertas, yang tidak menentukan jumlah contoh yang digunakan.
Model ini telah dilatih dengan GPU XP Titan tunggal untuk selamanya sampai mencapai akurasi uji 91%. Di bawah ini adalah hasil dengan 3 berjalan independen: 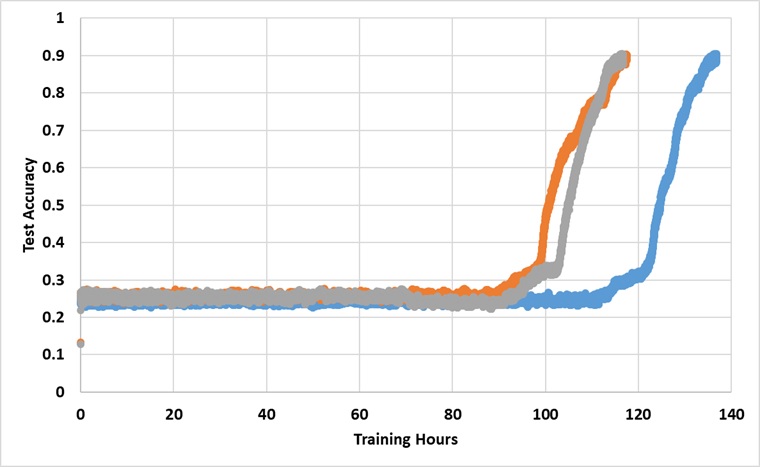
Model ini memang memecahkan penghalang 25% jika dilatih cukup lama, tetapi waktu jam dinding kira -kira lebih dari 2 ~ 3x lebih lama dari yang dilaporkan di koran.
Bereksperimen dengan hiperparameter yang berbeda


