relational rnn pytorch
1.0.0
تنفيذ الشبكات العصبية المتكررة العلائقية لـ DeepMind (Santoro et al. 2018) في Pytorch.
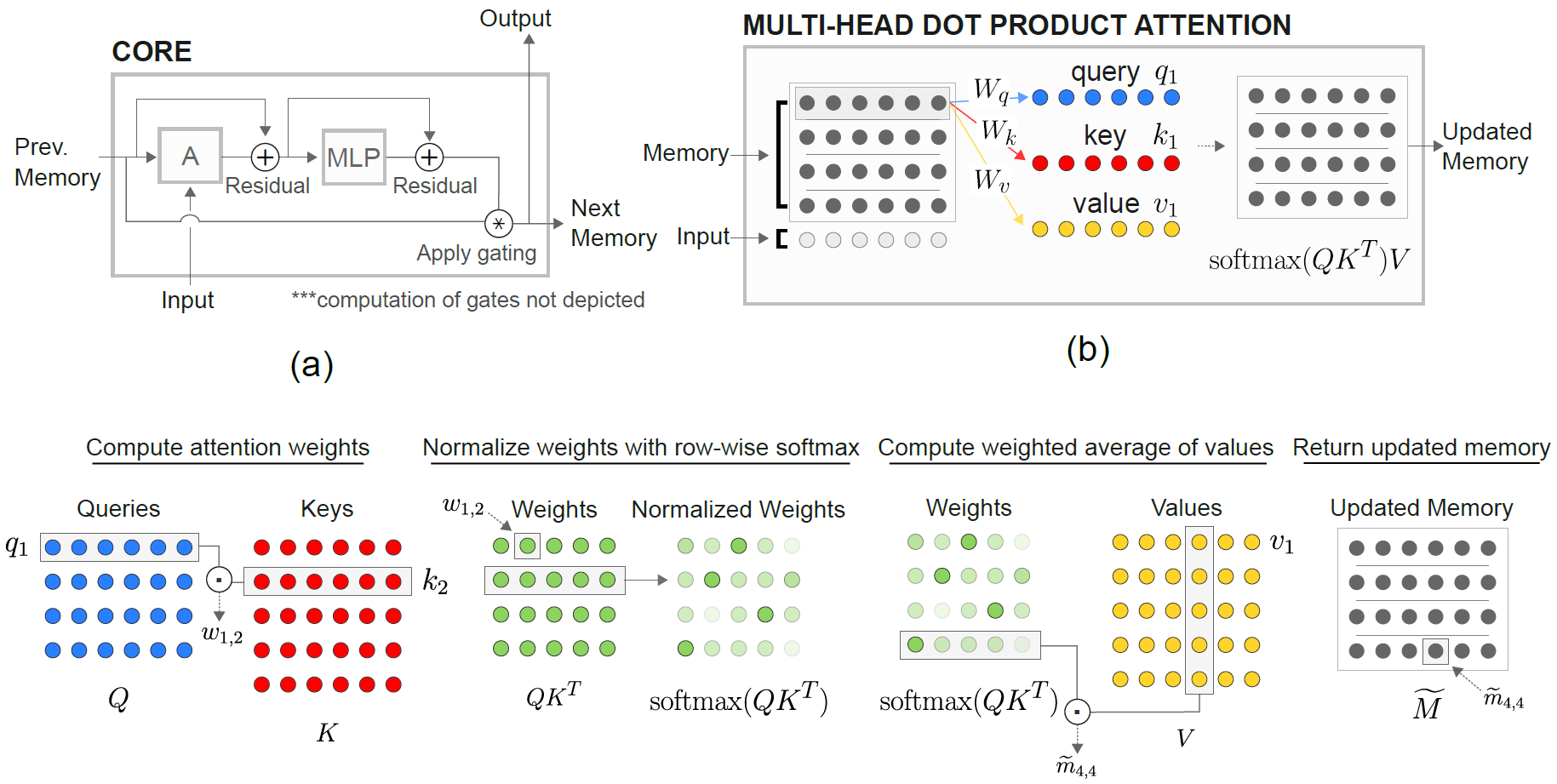
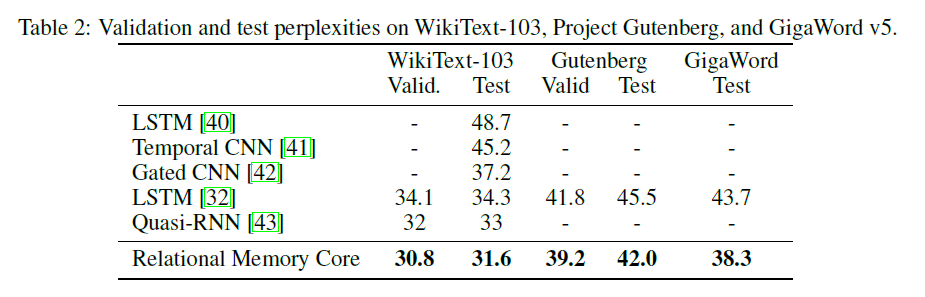
وحدة الذاكرة العلائقية Core (RMC) هي في الأصل من تنفيذ السوناتة الرسمية. ومع ذلك ، فهي لا توفر حاليًا رمزًا مؤشرًا للنمذجة الكاملة.
هذا الريبو هو منفذ RMC مع تعليقات إضافية. إنه يتميز بمعيار نمذجة لغة الكلمات الكاملة مقابل LSTM التقليدية.
وهو يدعم أي مجموعة بيانات نصية مستندة إلى رمز الكلمات ، بما في ذلك Wikitext-2 و Wikitext-103.
يدعم كل من طرازات RMC و LSTM SoftMax التكيفي لاستخدام ذاكرة أقل بكثير لمجموعة بيانات المفردات الكبيرة. تدعم RMC DataParallel من Pytorch ، بحيث يمكنك بسهولة تجربة إعداد متعدد GPU.
الرموز القياسية هي شديدة الصدفة من مثال على شكل كلمة pytorch
كما أنه يتميز بمهمة N-Th البعيدة عن الورقة (انظر أدناه).
Pytorch 0.4.1 أو أحدث (تم اختباره على 1.0.0) و Python 3.6
python train_rmc.py --cuda للتدريب الكامل واختبار RMC مع GPU.
python train_rmc.py --cuda --adaptivesoftmax --cutoffs 1000 5000 20000 إذا كنت تستخدم مجموعة بيانات كبيرة للمفردات (مثل wikitext-103) لتناسب جميع الموترات في VRAM.
python generate_rmc.py --cuda لإنشاء جمل من النموذج المدرب.
python train_rnn.py --cuda للتدريب الكامل واختبار RNN التقليدية مع وحدة معالجة الرسومات.
جميع المقاييس الفائقة الافتراضية لـ RMC و LSTM هي نتائج من تجربة مدتها أسبوعين باستخدام Wikitext-2.
تم اختباره مع Wikitext-2 و Wikitext-103. Wikitext-2 مجمعة.
train.txt valid.txt مقلع فرعي test.txt الداخل ./data
حدد --data=(subfolder name) وأنت على ما يرام.
يقوم الرمز بتنفيذ الرمز المميز في المدى التدريبي الأول ، ويتم حفظ المجموعة pickle . سيقوم الرمز بتحميل ملف pickle بعد التشغيل الأول.
كل من RMC و LSTM لديها ~ 11M معلمات. يرجى الرجوع إلى رمز التدريب للحصول على تفاصيل عن المقاييس المفرطة.
| النماذج | الحيرة الصالحة | اختبار الحيرة | الأمام تمريرة MS/Batch (Titan XP) | الأمام تمريرة MS/Batch (Titan V) |
|---|---|---|---|---|
| LSTM (CUDNN) | 111.31 | 105.56 | 26 ~ 27 | 40 ~ 41 |
| LSTM (للحلقة) | مثل كودن | مثل كودن | 30 ~ 31 | 60 ~ 61 |
| RMC | 112.77 | 107.21 | 110 ~ 130 | 220 ~ 230 |
يمكن أن تصل RMC إلى أداء مماثل لـ LSTM (مع البحث الفائق الثقيل) ، ولكن اتضح أن RMC بطيئة للغاية. قد يكون الاهتمام الذاتي متعدد الرأس في كل خطوة هو الجاني هنا. إن استخدام LSTMCELL مع LOOP (وهو المعيار "العادل" ل RMC) يبطئ الممر الأمامي ، لكنه لا يزال أسرع بكثير.
يرجى أيضًا الإشارة إلى أن المتقلب المفرط لـ RMC هو سيناريو أسوأ الحالات من حيث السرعة ، لأنه استخدم فتحة ذاكرة واحدة (كما هو موضح في الورقة) ولم تستفيد من مشاركة الوزن من خلال الذاكرة متعددة الفتحات.
من المثير للاهتمام أن نلاحظ هنا هو أن السرعة أبطأ في Titan V من Titan XP. قد يكون السبب هو أن النماذج صغيرة نسبيًا وأن النموذج يستدعي العمليات الخطية الصغيرة بشكل متكرر.
ربما تستفيد Titan XP (حوالي 1900 ميجا هرتز مسببة CUDA على مدار الساعة مقابل Titan V's 1،335 ميجا هرتز) من هذا النوع من عبء العمل. أو ربما يكون زمن انطلاق إطلاق Kernel من Titan V أعلى بالنسبة للعمليات في النموذج.
أنا لست خبيرًا في تفاصيل CUDA. يرجى مشاركة نتائجك!
تميل معلمات الانتباه إلى التغلب على wikitext -2. يمكن أن يقلل تقليل المفرطات المفرطة للانتباه (key_size) محاربة التورط.
ساعد تطبيق التسرب على سجل الإخراج قبل أن يساعد SoftMax (مثل LSTM One) في منع التورط.
| التضمين وحجم الرأس | # رؤساء | انتباه طبقات MLP | حجم المفتاح | التسرب في الإخراج | فتحات الذاكرة | اختبار PPL |
|---|---|---|---|---|---|---|
| 128 | 4 | 3 | 128 | لا | 1 | 128.81 |
| 128 | 4 | 3 | 128 | لا | 1 | 128.81 |
| 128 | 8 | 3 | 128 | لا | 1 | 141.84 |
| 128 | 4 | 3 | 32 | لا | 1 | 123.26 |
| 128 | 4 | 3 | 32 | نعم | 1 | 112.4 |
| 128 | 4 | 3 | 64 | لا | 1 | 124.44 |
| 128 | 4 | 3 | 64 | نعم | 1 | 110.16 |
| 128 | 4 | 2 | 64 | نعم | 1 | 111.67 |
| 64 | 4 | 3 | 64 | نعم | 1 | 133.68 |
| 64 | 4 | 3 | 32 | نعم | 1 | 135.93 |
| 64 | 4 | 3 | 64 | نعم | 4 | 137.93 |
| 192 | 4 | 3 | 64 | نعم | 1 | 107.21 |
| 192 | 4 | 3 | 64 | نعم | 4 | 114.85 |
| 256 | 4 | 3 | 256 | لا | 1 | 194.73 |
| 256 | 4 | 3 | 64 | نعم | 1 | 126.39 |
تقدم ورقة RMC الأصلية نتائج Wikitext-103 مع حجم أكبر ودُفعات (6 Tesla P100 ، لكل منها 64 حجمًا ، وبالتالي ما مجموعه 384. OUCH).
باستخدام softmax الكامل ينفخ بسهولة VRAM. يوصى بشدة باستخدام --adaptivesoftmax . إذا كنت تستخدم --adaptivesoftmax ، -يجب توفير --cutoffs بشكل صحيح. يرجى الرجوع إلى وصف API الأصلي
ليس لدي مثل هذه الأجهزة ومورد بلدي يقتصر جدًا على إجراء التجارب. النتيجة القياسية ، أو أي مساهمات أخرى مرحب بها للغاية!
الهدف من المهمة هو: إعطاء k المسمى بشكل عشوائي (من 1 إلى k) d-dimensal dectors ، تحديد ما هو المتجه الأبعد من المتجه M. (الجواب هو عدد صحيح من 1 إلى k.)
المهمة المحددة في الورقة هي: بالنظر إلى 8 متجهات ذات علامات 16-الأبعاد ، والتي هي المتجه الأبعد من المتجه M؟ يتم تصنيف المتجهات بشكل عشوائي بحيث يتعين على النموذج أن يدرك أن متجه MTH هو المتجه المسمى M على عكس المتجه في موضع MTH في المدخلات.
يشتمل المدخلات على النموذج على 8 ناقلات 40-الأبعاد لكل مثال. يتم تنظيم كل من هذه المتجهات ذات الأبعاد الأربعين على هذا النحو:
[(vector 1) (label: which vector is it, from 1 to 8, one-hot encoded) (N, one-hot encoded) (M, one-hot encoded)]
python train_nth_farthest.py --cuda للتدريب والاختبار على المهمة الأبعد مع GPU (S).
يستخدم هذا فئة RelationalMemory في relational_rnn_general.py ، وهو إصدار من relational_rnn_models.py بدون رمز محدد للنموذج.
يرجى الرجوع إلى train_nth_farthest.py للحصول على تفاصيل عن قيم الفائقة. هذه مأخوذة من الملحق A1 في الورقة ومن تطبيق Sonnet عندما لا يتم إعطاء قيم الفائق في الورقة.
ملاحظة: يتم إنشاء أمثلة جديدة لكل فترة كما في تنفيذ Sonnet. يبدو أن هذا يتماشى مع الورقة ، والتي لا تحدد عدد الأمثلة المستخدمة.
تم تدريب النموذج باستخدام وحدة معالجة الرسومات Titan XP واحدة إلى الأبد حتى تصل إلى دقة اختبار 91 ٪. فيما يلي النتائج مع 3 أشواط مستقلة: 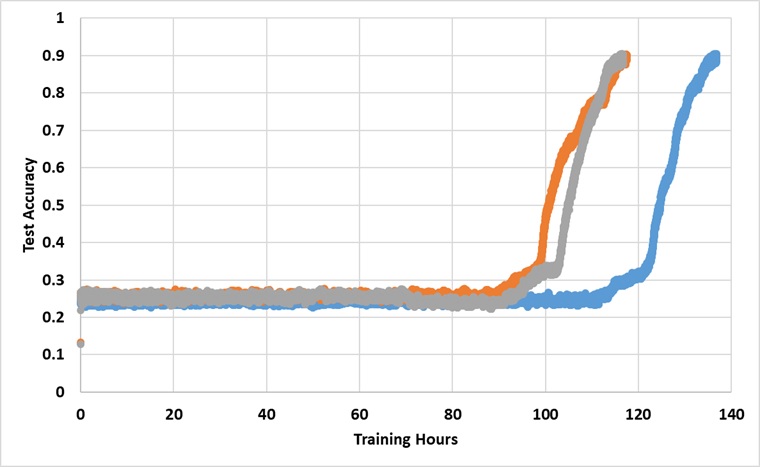
لا يكسر النموذج حاجز 25 ٪ إذا تم تدريبه لفترة كافية ، لكن وقت ساعة الحائط يزيد عن 2 ~ 3x أطول من تلك الموجودة في الورقة.
تجربة مع فرط البرارمامترات المختلفة


