relational rnn pytorch
1.0.0
การดำเนินการตามเครือข่ายประสาทที่เกิดขึ้นใหม่ของ DeepMind (Santoro et al. 2018) ใน Pytorch
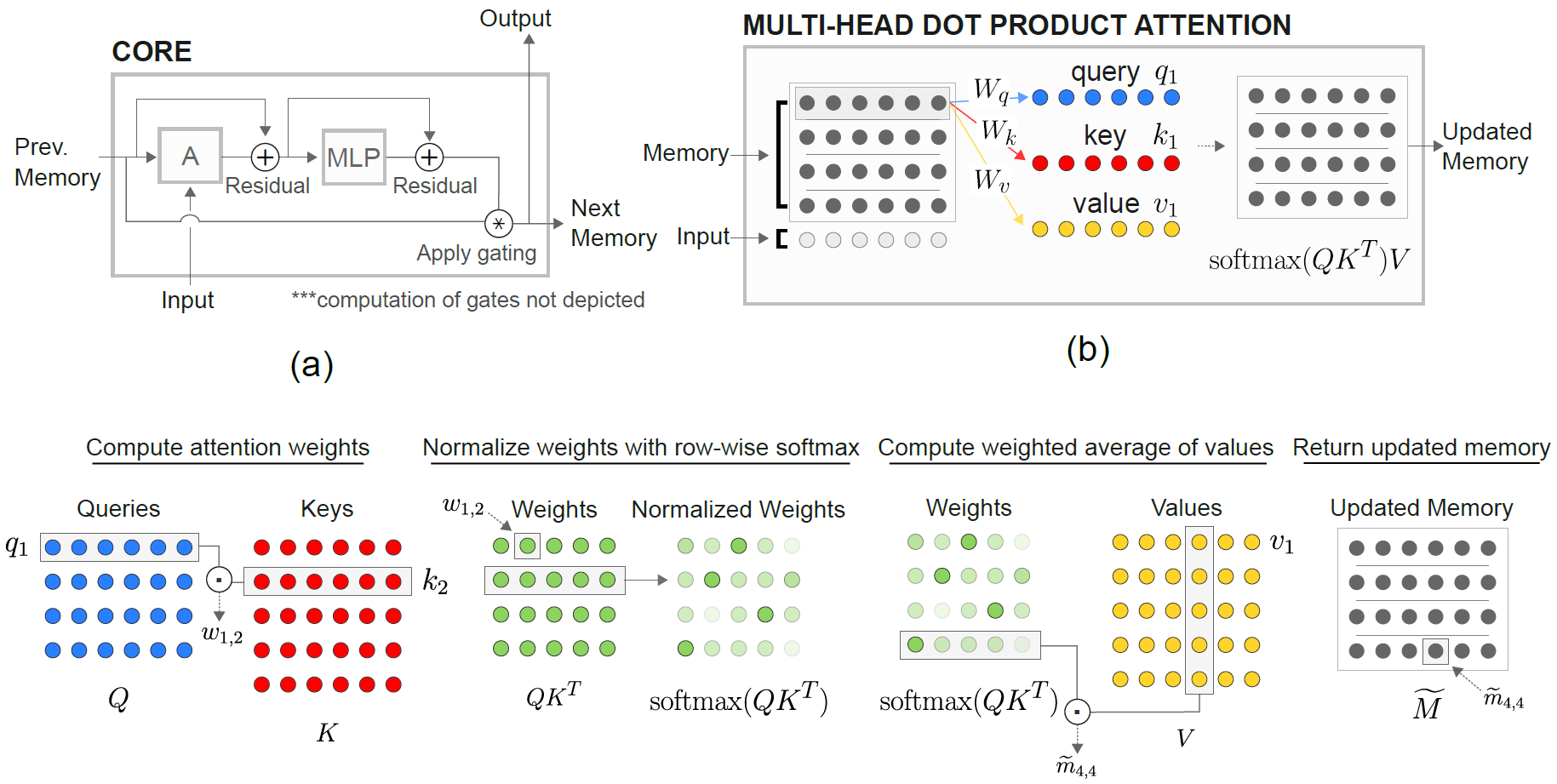
โมดูล Memory Memory Memory (RMC) มีพื้นเพมาจากการใช้งานโคลงอย่างเป็นทางการ อย่างไรก็ตามในปัจจุบันพวกเขาไม่ได้ให้รหัสมาตรฐานการสร้างแบบจำลองภาษาเต็มรูปแบบ
repo นี้เป็นพอร์ตของ RMC พร้อมความคิดเห็นเพิ่มเติม มันมีเกณฑ์มาตรฐานการสร้างแบบจำลองภาษาคำศัพท์เต็มรูปแบบกับ LSTM แบบดั้งเดิม
รองรับชุดข้อมูลข้อความที่ใช้โทเค็นโดยพลการใด ๆ รวมถึง Wikitext-2 & Wikitext-103
ทั้งรุ่น RMC & LSTM รองรับ Softmax Adaptive สำหรับการใช้หน่วยความจำที่ต่ำกว่ามากของชุดข้อมูลคำศัพท์ขนาดใหญ่ RMC รองรับ DataParallel ของ Pytorch ดังนั้นคุณสามารถทดสอบด้วยการตั้งค่าหลาย GPU ได้อย่างง่ายดาย
รหัสเกณฑ์มาตรฐานเป็นตัวอย่างที่ยากมาจากตัวอย่างโมเดลคำพูดภาษาคำพูดอย่างเป็นทางการ
นอกจากนี้ยังมีงานสังเคราะห์ที่ไกลที่สุดจากกระดาษ (ดูด้านล่าง)
Pytorch 0.4.1 หรือใหม่กว่า (ทดสอบบน 1.0.0) & Python 3.6
python train_rmc.py --cuda สำหรับการฝึกอบรมและทดสอบเต็มรูปแบบของ RMC ด้วย GPU
python train_rmc.py --cuda --adaptivesoftmax --cutoffs 1000 5000 20000 หากใช้ชุดข้อมูลคำศัพท์ขนาดใหญ่ (เช่น Wikitext-103) เพื่อให้พอดีกับเทนเซอร์ทั้งหมดใน VRAM
python generate_rmc.py --cuda สำหรับการสร้างประโยคจากโมเดลที่ผ่านการฝึกอบรม
python train_rnn.py --cuda สำหรับการฝึกอบรมเต็มรูปแบบและการทดสอบ RNN แบบดั้งเดิมด้วย GPU
hyperparameters เริ่มต้นทั้งหมดของ RMC & LSTM เป็นผลมาจากการทดลองสองสัปดาห์โดยใช้ Wikitext-2
ทดสอบด้วย Wikitext-2 และ Wikitext-103 Wikitext-2 ถูกรวมเข้าด้วยกัน
สร้างโฟลเดอร์ย่อยภายใน ./data และวาง word-level train.txt , valid.txt และ test.txt ภายในโฟลเดอร์ย่อย
ระบุ --data=(subfolder name) และคุณก็พร้อมที่จะไป
รหัสดำเนินการโทเค็นในการฝึกอบรมครั้งแรกและคลังข้อมูลจะถูกบันทึกเป็น pickle รหัสจะโหลดไฟล์ pickle หลังจากการรันครั้งแรก
ทั้ง RMC & LSTM มีพารามิเตอร์ ~ 11m โปรดดูรหัสการฝึกอบรมสำหรับรายละเอียดเกี่ยวกับพารามิเตอร์ hyperparameters
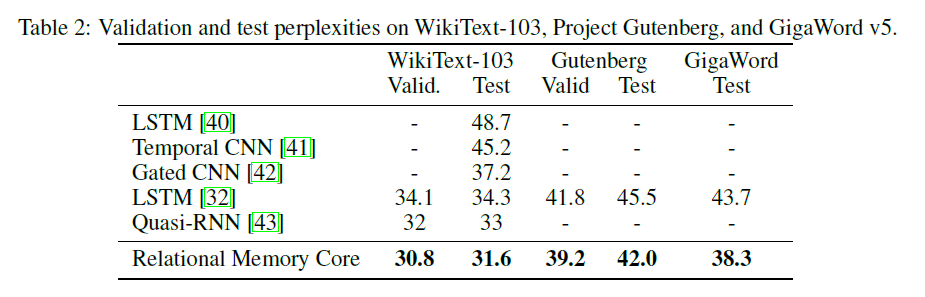
| แบบจำลอง | ถูกต้อง | ทดสอบความงุนงง | Forward Pass MS/Batch (Titan XP) | ส่งต่อ MS/Batch (Titan V) |
|---|---|---|---|---|
| LSTM (CUDNN) | 111.31 | 105.56 | 26 ~ 27 | 40 ~ 41 |
| LSTM (สำหรับลูป) | เหมือนกับ cudnn | เหมือนกับ cudnn | 30 ~ 31 | 60 ~ 61 |
| RMC | 112.77 | 107.21 | 110 ~ 130 | 220 ~ 230 |
RMC สามารถเข้าถึงประสิทธิภาพที่เทียบเคียงได้กับ LSTM (ด้วยการค้นหาพารามิเตอร์ไฮเปอร์พารามิเตอร์หนัก) แต่ปรากฎว่า RMC ช้ามาก ความตั้งใจของตนเองหลายหัวในทุกขั้นตอนอาจเป็นผู้ร้ายที่นี่ การใช้ LSTMCELL กับ Loop (ซึ่งเป็นเกณฑ์มาตรฐาน "ยุติธรรม" สำหรับ RMC) ช้าลงผ่านไปข้างหน้า แต่ก็ยังเร็วกว่ามาก
โปรดทราบว่าไฮเปอร์พารามิเตอร์สำหรับ RMC เป็นสถานการณ์ที่เลวร้ายที่สุดในแง่ของความเร็วเนื่องจากใช้สล็อตหน่วยความจำเดียว (ตามที่อธิบายไว้ในกระดาษ) และไม่ได้รับประโยชน์จากการแบ่งปันน้ำหนักแถวที่ชาญฉลาดจากหน่วยความจำหลายช่อง
ที่น่าสนใจที่จะทราบที่นี่คือความเร็วจะช้าลงใน Titan V กว่า Titan XP เหตุผลอาจเป็นไปได้ว่าแบบจำลองมีขนาดค่อนข้างเล็กและโมเดลเรียกการทำงานเชิงเส้นเล็ก ๆ บ่อยครั้ง
บางที Titan XP (~ 1,900MHz ปลดล็อคความเร็วนาฬิกา CUDA เทียบกับขีด จำกัด 1,335MHz ของ Titan V) จากภาระงานประเภทนี้ หรือบางทีการเปิดตัวเคอร์เนล CUDA ของ Titan V นั้นสูงกว่าสำหรับ OPS ในโมเดล
ฉันไม่ใช่ผู้เชี่ยวชาญในรายละเอียดของ Cuda กรุณาแบ่งปันผลลัพธ์ของคุณ!
พารามิเตอร์ความสนใจมีแนวโน้มที่จะ overfit wikitext-2 การลด Hyperparmeters สำหรับความสนใจ (key_size) สามารถต่อสู้กับการ overfitting
การใช้ดรอปเอาท์ที่เอาต์พุต logit ก่อนที่ Softmax (เช่น LSTM One) ช่วยป้องกันไม่ให้มีการ overfitting
| ขนาดหัวและขนาดหัว | # หัว | ความสนใจเลเยอร์ MLP | ขนาดคีย์ | ออกกลางคันที่เอาต์พุต | ช่องหน่วยความจำ | ทดสอบ ppl |
|---|---|---|---|---|---|---|
| 128 | 4 | 3 | 128 | เลขที่ | 1 | 128.81 |
| 128 | 4 | 3 | 128 | เลขที่ | 1 | 128.81 |
| 128 | 8 | 3 | 128 | เลขที่ | 1 | 141.84 |
| 128 | 4 | 3 | 32 | เลขที่ | 1 | 123.26 |
| 128 | 4 | 3 | 32 | ใช่ | 1 | 112.4 |
| 128 | 4 | 3 | 64 | เลขที่ | 1 | 124.44 |
| 128 | 4 | 3 | 64 | ใช่ | 1 | 110.16 |
| 128 | 4 | 2 | 64 | ใช่ | 1 | 111.67 |
| 64 | 4 | 3 | 64 | ใช่ | 1 | 133.68 |
| 64 | 4 | 3 | 32 | ใช่ | 1 | 135.93 |
| 64 | 4 | 3 | 64 | ใช่ | 4 | 137.93 |
| 192 | 4 | 3 | 64 | ใช่ | 1 | 107.21 |
| 192 | 4 | 3 | 64 | ใช่ | 4 | 114.85 |
| 256 | 4 | 3 | 256 | เลขที่ | 1 | 194.73 |
| 256 | 4 | 3 | 64 | ใช่ | 1 | 126.39 |
กระดาษ RMC ดั้งเดิมนำเสนอผลลัพธ์ Wikitext-103 ที่มีขนาดและขนาดแบทช์ขนาดใหญ่ (6 TESLA P100 แต่ละขนาดมีขนาด 64 ชุดดังนั้นทั้งหมด 384. OUCH)
การใช้ softmax เต็มรูปแบบจะระเบิด VRAM ได้อย่างง่ายดาย ขอแนะนำ -แนะนำ --adaptivesoftmax หากใช้ --adaptivesoftmax -ควรมี --cutoffs อย่างเหมาะสม โปรดดูคำอธิบาย API ดั้งเดิม
ฉันไม่มีฮาร์ดแวร์ดังกล่าวและทรัพยากรของฉัน จำกัด เกินกว่าที่จะทำการทดลอง ผลการวัดประสิทธิภาพหรือการบริจาคอื่น ๆ ยินดีต้อนรับมาก!
วัตถุประสงค์ของงานคือ: ให้ K แบบสุ่ม (จาก 1 ถึง K) เวกเตอร์ D-dimensional ระบุว่าเป็นเวกเตอร์ที่ไกลที่สุดที่ N จากเวกเตอร์ M (คำตอบคือจำนวนเต็มจาก 1 ถึง k)
งานที่เฉพาะเจาะจงในกระดาษคือ: ได้รับ 8 เวกเตอร์ 16 มิติที่มีป้ายกำกับซึ่งเป็นเวกเตอร์ที่ไกลที่สุดจากเวกเตอร์ M? เวกเตอร์มีป้ายกำกับแบบสุ่มดังนั้นแบบจำลองจะต้องรับรู้ว่าเวกเตอร์ MTH เป็นเวกเตอร์ที่มีป้ายกำกับว่าเป็น M เมื่อเทียบกับเวกเตอร์ในตำแหน่ง MTH ในอินพุต
อินพุตไปยังโมเดลประกอบด้วยเวกเตอร์ 40 มิติสำหรับแต่ละตัวอย่าง แต่ละเวกเตอร์ 40 มิติเหล่านี้มีโครงสร้างเช่นนี้:
[(vector 1) (label: which vector is it, from 1 to 8, one-hot encoded) (N, one-hot encoded) (M, one-hot encoded)]
python train_nth_farthest.py --cuda สำหรับการฝึกอบรมและการทดสอบในงานที่ไกลที่สุดด้วย GPU
สิ่งนี้ใช้คลาส RelationalMemory ใน relational_rnn_general.py ซึ่งเป็นเวอร์ชันของ relational_rnn_models.py โดยไม่ต้องใช้รหัสเฉพาะภาษา
โปรดดูที่ train_nth_farthest.py สำหรับรายละเอียดเกี่ยวกับค่า Hyperparameter สิ่งเหล่านี้นำมาจากภาคผนวก A1 ในกระดาษและจากการใช้งาน Sonnet เมื่อไม่ได้รับค่าไฮเปอร์พารามิเตอร์ในกระดาษ
หมายเหตุ: ตัวอย่างใหม่ถูกสร้างขึ้นต่อยุคเช่นเดียวกับในการใช้งาน Sonnet สิ่งนี้ดูเหมือนจะสอดคล้องกับกระดาษซึ่งไม่ได้ระบุจำนวนตัวอย่างที่ใช้
โมเดลได้รับการฝึกฝนด้วย Titan XP GPU เดียวตลอดไปจนกว่าจะถึงความแม่นยำในการทดสอบ 91% ด้านล่างนี้เป็นผลลัพธ์ที่มีการวิ่งอิสระ 3 ครั้ง: 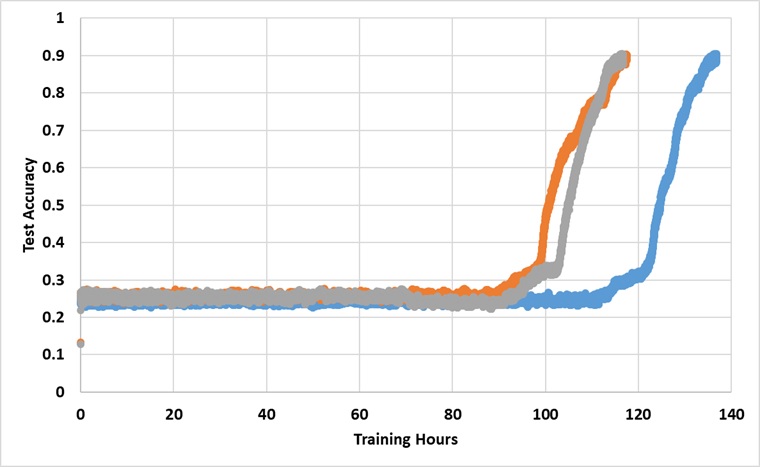
แบบจำลองจะทำลายอุปสรรค 25% หากได้รับการฝึกฝนมานานพอ แต่เวลานาฬิกาแขวนจะยาวกว่า 2 ~ 3x ที่รายงานไว้ในกระดาษ
ทดลองกับพารามิเตอร์ hyperparameters ที่แตกต่างกัน


