open_flamingo
2.0.1
紙|博客文章:1、2 |演示
歡迎來到我們對DeepMind Flamingo的開源實施!
在此存儲庫中,我們提供了用於培訓和評估OpenFlamingo模型的Pytorch實現。如果您有任何疑問,請隨時打開問題。我們也歡迎捐款!
要在現有環境中安裝軟件包,請運行
pip install open-flamingo
或為運行OpenFlamingo創建Conda環境,運行
conda env create -f environment.yml
要安裝培訓或評估依賴項,請運行前兩個命令之一。要安裝所有內容,請運行第三個命令。
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
有三個requirements.txt文件:
requirements.txtrequirements-training.txtrequirements-eval.txt根據用例,您可以將其中的任何一個安裝在pip install -r <requirements-file.txt>中。基本文件僅包含運行模型所需的依賴項。
我們使用預加壓掛鉤將格式與存儲庫中的檢查對齊。
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
然後,每次我們運行git提交時,都會運行檢查。如果文件通過掛鉤重新格式化,請為您更改的文件添加git add並再次git commit
OpenFlamingo是一種多模式模型,可用於各種任務。它在大型多模式數據集(例如多模式C4)上進行了訓練,可用於生成在交織的圖像/文本上的文本。例如,OpenFlamingo可用於生成圖像的標題,或者生成給定圖像和文本段落的問題。這種方法的好處是,我們能夠使用內部文化學習快速適應新任務。
OpenFlamingo使用跨注意層結合了預處理的視覺編碼器和語言模型。模型架構如下所示。
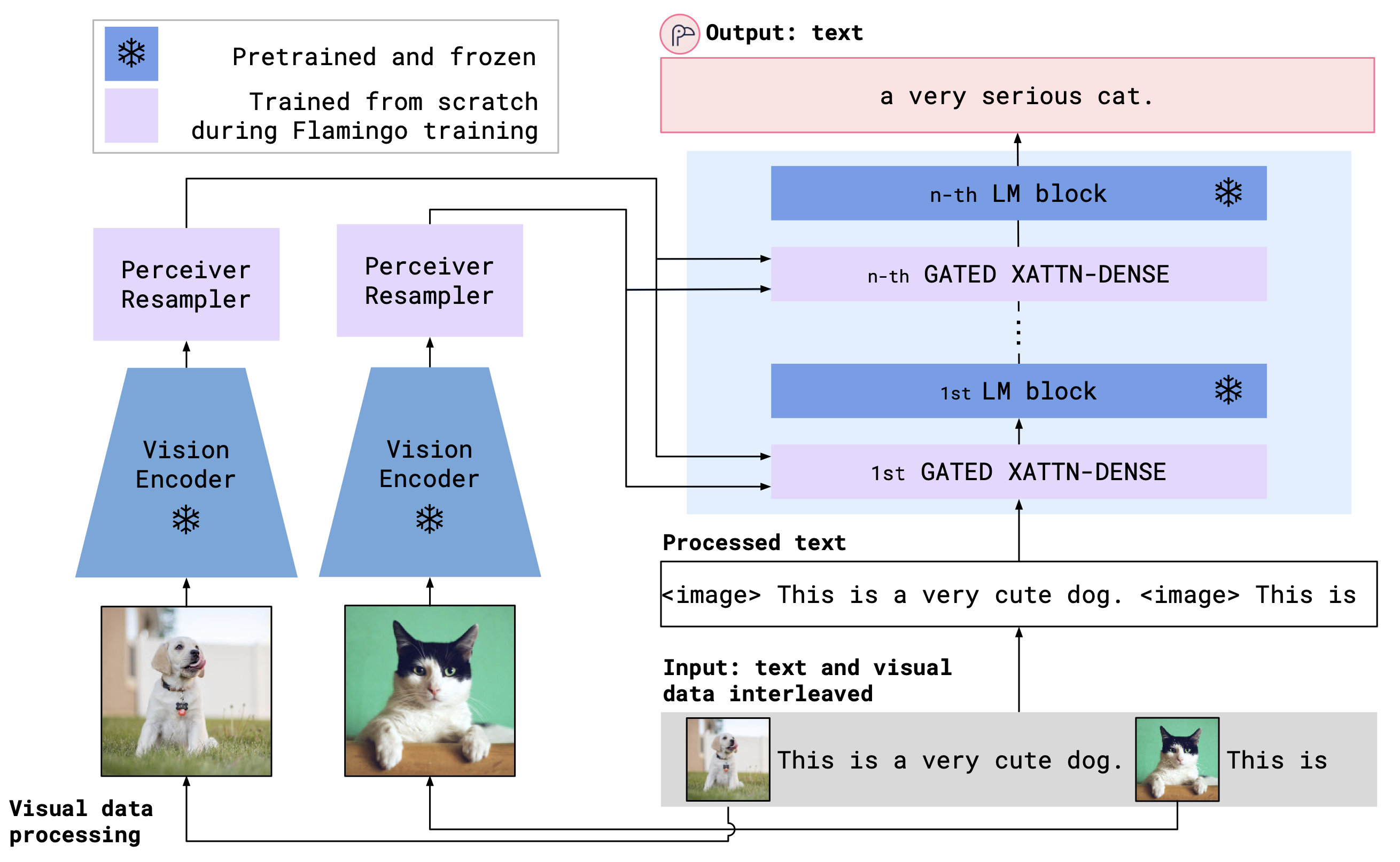 信用:火烈鳥
信用:火烈鳥
我們支持OpenClip軟件包中預驗證的視覺編碼器,其中包括OpenAI驗證的型號。我們還支持來自transformers軟件包的預讀語言模型,例如MPT,Redpajama,Llama,Opt,GPT-Neo,GPT-J,GPT-J和Pythia模型。
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)到目前為止,我們已經培訓了以下OpenFlamingo車型。
| #參數 | 語言模型 | 視覺編碼器 | XATTN間隔* | 可可4射門蘋果酒 | VQAV2 4-shot精度 | 權重 |
|---|---|---|---|---|---|---|
| 3b | Anas-Awadalla/MPT-1B-REDPAJAMA-200B | Openai剪輯VIT-L/14 | 1 | 77.3 | 45.8 | 關聯 |
| 3b | Anas-Awadalla/MPT-1B-REDPAJAMA-200B-DOLLY | Openai剪輯VIT-L/14 | 1 | 82.7 | 45.7 | 關聯 |
| 4b | 共同計算機/redpajama-incite-base-3b-v1 | Openai剪輯VIT-L/14 | 2 | 81.8 | 49.0 | 關聯 |
| 4b | 共同計算機/Redpajama-Incite-Instruct-3B-V1 | Openai剪輯VIT-L/14 | 2 | 85.8 | 49.0 | 關聯 |
| 9b | ANAS-AWADALLA/MPT-7B | Openai剪輯VIT-L/14 | 4 | 89.0 | 54.8 | 關聯 |
* XATTN間隔是指--cross_attn_every_n_layers參數。
注意:作為我們V2版本的一部分,我們已經棄用了以前的基於Llama的檢查點。但是,您可以使用新的代碼庫繼續使用我們的舊檢查點。
要使用我們已發布的權重的OpenFlamingo模型實例化,請按上述初始化該模型並使用以下代碼。
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )下面是生成在交織的圖像/文本中生成文本的示例。特別是,讓我們嘗試幾張圖像字幕。
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ]))我們在open_flamingo/train中提供培訓腳本。我們在open_flamingo/scripts/run_train.py以及以下示例命令中提供了一個示例slurm腳本:
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
注意:MPT-1B基礎和指示建模代碼不接受labels Kwarg或直接在forward()內部計算跨膜片損失,如我們的代碼庫所預期的那樣。我們建議使用此處和此處找到的MPT-1B型號的修改版本。
有關更多詳細信息,請參閱我們的培訓回复。
示例評估腳本位於open_flamingo/scripts/run_eval.sh 。有關更多詳細信息,請參閱我們的評估錄像機。
要在OKVQA上運行評估,您將需要運行以下命令:
import nltk
nltk.download('wordnet')
OpenFlamingo的開發是:
Anas Awadalla*, Irena Gao*, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, Ludwig施密特。
該團隊主要來自華盛頓大學,斯坦福大學,AI2,UCSB和Google。
該代碼基於Lucidrains的Flamingo實施和David Hansmair的Flamingo-Mini Repo。感謝您公開代碼!我們還要感謝OpenClip團隊使用他們的數據加載代碼並從其庫設計中汲取靈感。
我們還要感謝Jean-Baptiste Alayrac和Antoine Miech的建議Rohan Taori,Rohan Taori,Nicholas Schiefer,Deep Ganguli,Thomas Liao,Tatsunori Hashimoto和Nicholas carlini,以評估我們發行的安全風險,以培訓我們的穩定AI,並為我們提供了穩定的資源,以培訓我們的穩定性AI,以培訓AI的安全風險。
如果您發現此存儲庫有用,請考慮引用:
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


