open_flamingo
2.0.1
Papel | Postagens do blog: 1, 2 | Demonstração
Bem -vindo à nossa implementação de código aberto do Flamingo de DeepMind!
Neste repositório, fornecemos uma implementação de Pytorch para treinamento e avaliação de modelos OpenFlamingo. Se você tiver alguma dúvida, não hesite em abrir um problema. Também recebemos contribuições!
Para instalar o pacote em um ambiente existente, execute
pip install open-flamingo
Ou para criar um ambiente de conda para executar o OpenFlamingo, execute
conda env create -f environment.yml
Para instalar dependências de treinamento ou avaliar, execute um dos dois primeiros comandos. Para instalar tudo, execute o terceiro comando.
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
Existem três requirements.txt arquivos:
requirements.txtrequirements-training.txtrequirements-eval.txt Dependendo do seu caso de uso, você pode instalar qualquer um deles com pip install -r <requirements-file.txt> . O arquivo base contém apenas as dependências necessárias para a execução do modelo.
Utilizamos ganchos pré-comprometidos para alinhar a formatação com os cheques no repositório.
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
Então, toda vez que executamos o commit git, os cheques são executados. Se os arquivos forem reformatados pelos ganchos, execute git add para seus arquivos alterados e git commit novamente
OpenFlamingo é um modelo de linguagem multimodal que pode ser usado para uma variedade de tarefas. É treinado em um grande conjunto de dados multimodais (por exemplo, C4 multimodal) e pode ser usado para gerar texto condicionado em imagens/texto intercaladas. Por exemplo, o OpenFlamingo pode ser usado para gerar uma legenda para uma imagem ou para gerar uma pergunta, dada uma imagem e uma passagem de texto. O benefício dessa abordagem é que somos capazes de nos adaptar rapidamente a novas tarefas usando o aprendizado no contexto.
O OpenFlamingo combina um codificador de visão pré -treinamento e um modelo de idioma usando camadas cruzadas de atenção. A arquitetura do modelo é mostrada abaixo.
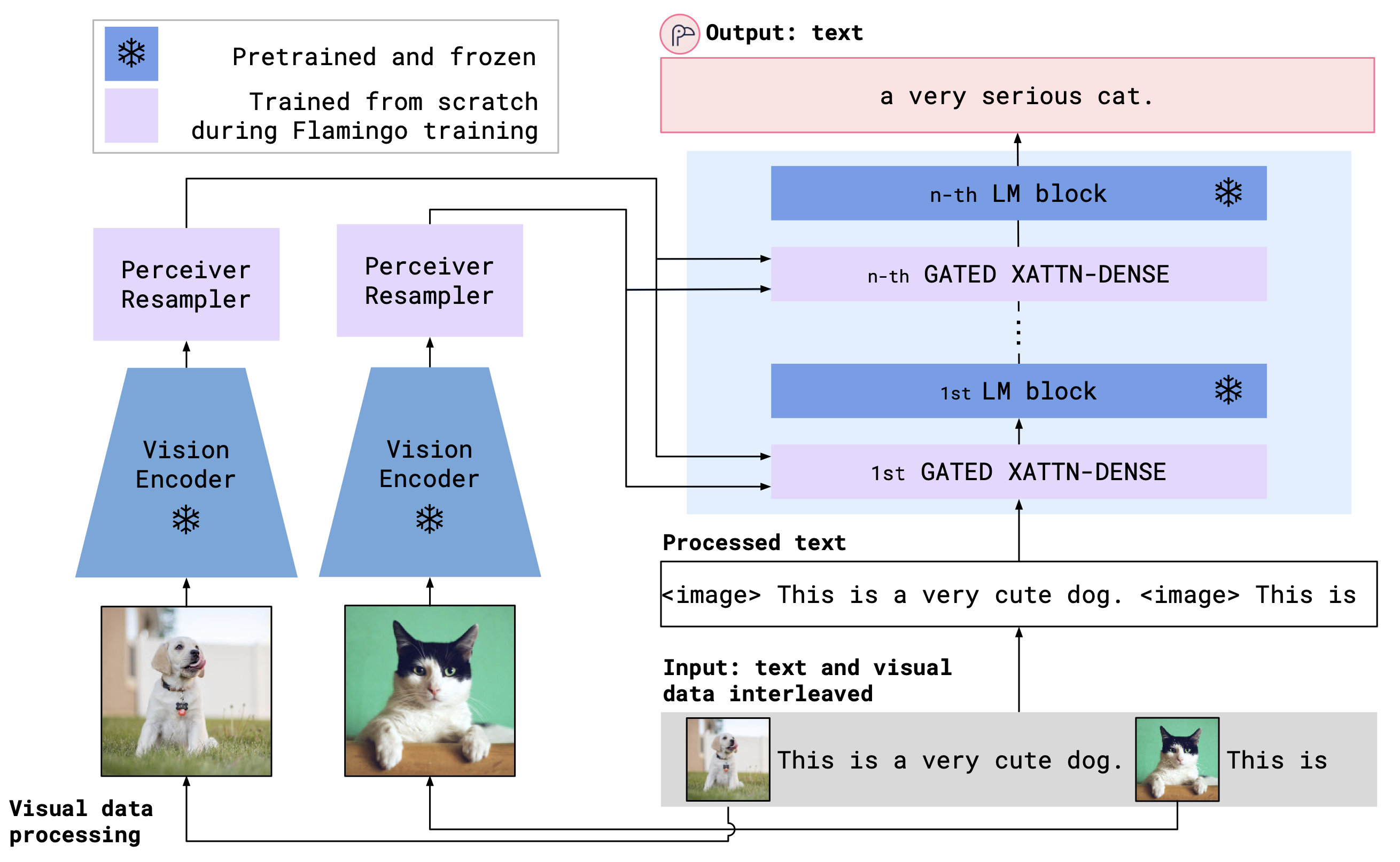 Crédito: Flamingo
Crédito: Flamingo
Apoiamos codificadores de visão pré -treinados do pacote OpenClip, que inclui os modelos pré -treinados do OpenAI. Também apoiamos modelos de idiomas pré-tenhados do pacote transformers , como modelos de MPT, Redpajama, Llama, OPT, GPT-NEO, GPT-J e Pythia.
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)Até agora, treinamos os seguintes modelos OpenFlamingo.
| # params | Modelo de idioma | Encoder de visão | Intervalo xattn* | Cidra de 4 tiros Coco | VQAV2 Precisão de 4 tiros | Pesos |
|---|---|---|---|---|---|---|
| 3b | Anas-Awadalla/MPT-1B-Redpajama-200b | CLIP OPENAI VIT-L/14 | 1 | 77.3 | 45.8 | Link |
| 3b | Anas-Awadalla/MPT-1B-Redpajama-200b-Dolly | CLIP OPENAI VIT-L/14 | 1 | 82.7 | 45.7 | Link |
| 4b | TONASCUMPUTER/REDPAJAMA-INCITE-BASE-3B-V1 | CLIP OPENAI VIT-L/14 | 2 | 81.8 | 49.0 | Link |
| 4b | TogetherComputer/Redpajama-Incite-Instruct-3b-V1 | CLIP OPENAI VIT-L/14 | 2 | 85.8 | 49.0 | Link |
| 9b | Anas-Awadalla/MPT-7b | CLIP OPENAI VIT-L/14 | 4 | 89.0 | 54.8 | Link |
* Intervalo xattn refere -se ao argumento --cross_attn_every_n_layers .
Nota: Como parte do nosso lançamento em V2, depreciamos um ponto de verificação anterior baseado em llama. No entanto, você pode continuar usando nosso ponto de verificação mais antigo usando a nova base de código.
Para instanciar um modelo OpenFlamingo com um de nossos pesos lançados, inicialize o modelo como acima e use o código a seguir.
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )Abaixo está um exemplo de geração de texto condicionado em imagens/texto intercaladas. Em particular, vamos tentar a legenda de poucas imagens.
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ])) Fornecemos scripts de treinamento em open_flamingo/train . Fornecemos um exemplo de script slurm em open_flamingo/scripts/run_train.py , bem como o comando de exemplo a seguir:
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
Nota: A base MPT-1B e o código de modelagem Instruct não aceitam os labels KWARG ou a perda de entropia cruzada diretamente forward() , conforme esperado pela nossa base de código. Sugerimos o uso de uma versão modificada dos modelos MPT-1B encontrados aqui e aqui.
Para mais detalhes, consulte nosso Readme de Treinamento.
Um exemplo de script de avaliação está em open_flamingo/scripts/run_eval.sh . Consulte a nossa avaliação Readme para obter mais detalhes.
Para executar avaliações no OKVQA, você precisará executar o seguinte comando:
import nltk
nltk.download('wordnet')
OpenFlamingo é desenvolvido por:
Anas Awadalla*, Irena Gao*, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, Ludwig Schmidt.
A equipe é principalmente da Universidade de Washington, Stanford, AI2, UCSB e Google.
Este código é baseado na implementação do Flamingo da Lucidrains e no repositório Flamingo-Mini de David Hansmair. Obrigado por tornar seu código público! Agradecemos também à equipe OpenClip, pois usamos o código de carregamento de dados e nos inspiramos no design da biblioteca.
Gostaríamos também de agradecer a Jean-Baptiste Alayrac e Antoine Miech por seus conselhos, Rohan Taori, Nicholas Schiefer, Ganguli Deep, Thomas Liao, Tatsunori Hashimoto, e Nicholas Carlini, para avaliar os riscos de segurança de nossa liberação, e a estabilidade ai ai ai ai para serem transmitidos.
Se você achou esse repositório útil, considere citar:
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


