open_flamingo
2.0.1
Papier | Blog -Beiträge: 1, 2 | Demo
Willkommen zu unserer Open -Source -Implementierung von DeepMinds Flamingo!
In diesem Repository bieten wir eine Pytorch -Implementierung für die Schulung und Bewertung von OpenFlamingo -Modellen. Wenn Sie Fragen haben, können Sie bitte ein Problem eröffnen. Wir begrüßen auch Beiträge!
Um das Paket in einer vorhandenen Umgebung zu installieren, laufen Sie aus
pip install open-flamingo
Oder um eine Conda -Umgebung für das Ausführen von OpenFlamingo zu schaffen, rennen Sie
conda env create -f environment.yml
Führen Sie einen der ersten beiden Befehle aus, um Schulungen oder Eval -Abhängigkeiten zu installieren. Um alles zu installieren, führen Sie den dritten Befehl aus.
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
Es gibt drei requirements.txt . TXT -Dateien:
requirements.txtrequirements-training.txtrequirements-eval.txt Abhängig von Ihrem Anwendungsfall können Sie alle mit pip install -r <requirements-file.txt> installieren. Die Basisdatei enthält nur die Abhängigkeiten, die zum Ausführen des Modells erforderlich sind.
Wir verwenden Pre-Commit-Hooks, um die Formatierung der Schecks im Repository auszurichten.
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
Jedes Mal, wenn wir Git Commit durchführen, werden die Schecks ausgeführt. Wenn die Dateien von den Hooks neu formatiert werden, führen Sie git add für Ihre geänderten Dateien aus und git commit erneut
OpenFlamingo ist ein multimodales Sprachmodell, das für eine Vielzahl von Aufgaben verwendet werden kann. Es wird auf einem großen multimodalen Datensatz (z. B. multimodaler C4) trainiert und kann verwendet werden, um Text auf verschachtelten Bildern/Text zu generieren. Zum Beispiel kann OpenFlamingo verwendet werden, um eine Bildunterschrift für ein Bild zu generieren oder eine Frage mit einem Bild und einer Textpassage zu erstellen. Der Vorteil dieses Ansatzes besteht darin, dass wir mithilfe von In-Kontext-Lernen schnell an neue Aufgaben anpassen können.
OpenFlamingo kombiniert einen vorbereiteten Visionscodierer und ein Sprachmodell unter Verwendung von Cross -Aufmerksamkeitsschichten. Die Modellarchitektur ist unten gezeigt.
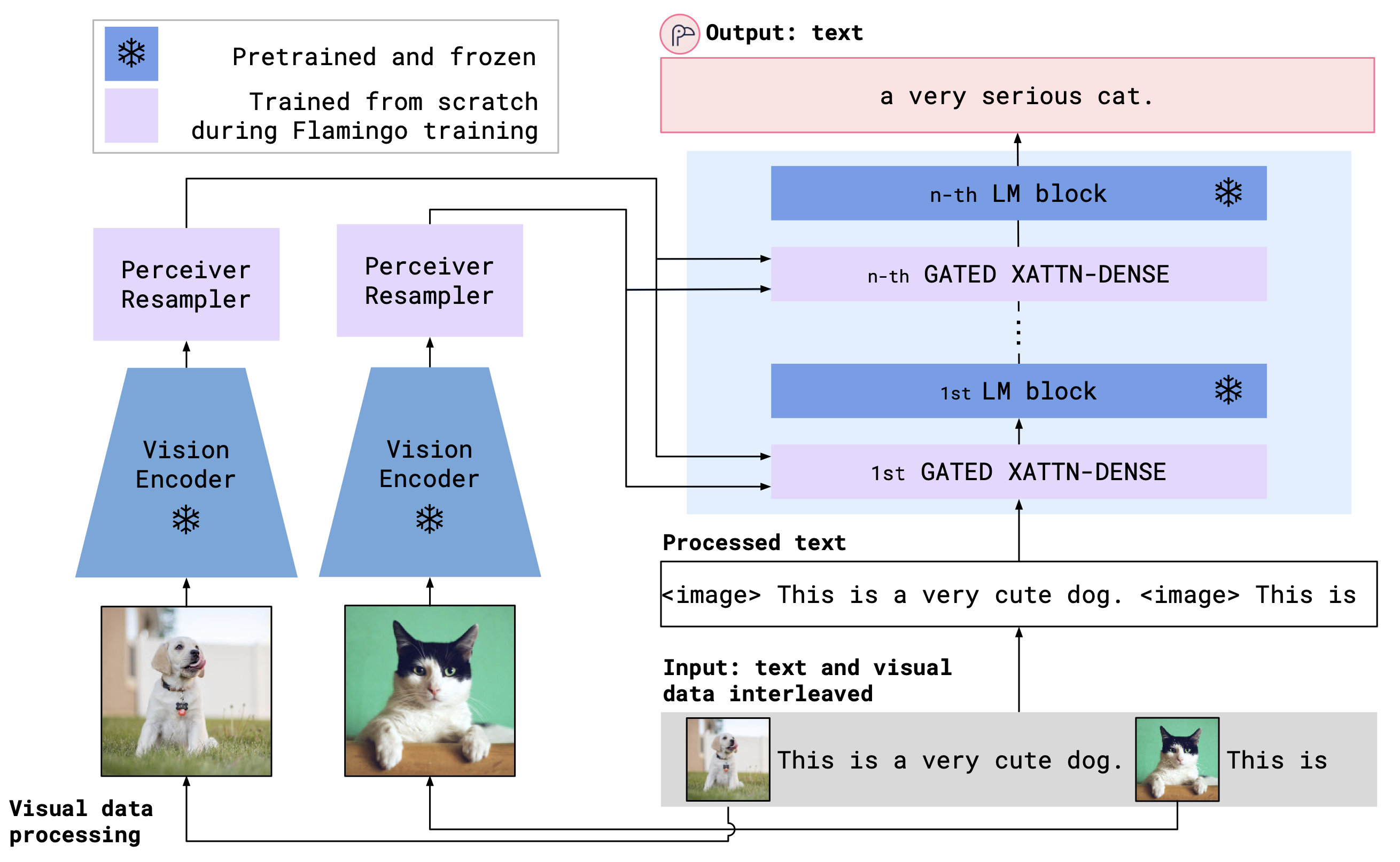 Kredit: Flamingo
Kredit: Flamingo
Wir unterstützen vorbereitete Visionscodierer aus dem OpenClip -Paket, das OpenAIs vorbereitete Modelle enthält. Wir unterstützen auch vorbereitete Sprachmodelle aus dem transformers -Paket wie MPT-, Redpajama-, Lama-, OPT-, GPT-Neo-, GPT-J- und Pythia-Modelle.
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)Wir haben die folgenden OpenFlamingo -Modelle bisher ausgebildet.
| # Parames | Sprachmodell | Vision Encoder | Xattn -Intervall* | Coco 4-Shot-Apfelwein | VQAV2 4-Shot-Genauigkeit | Gewichte |
|---|---|---|---|---|---|---|
| 3b | Anas-Awadalla/MPT-1B-Redpajama-200b | OpenAI Clip Vit-L/14 | 1 | 77,3 | 45,8 | Link |
| 3b | Anas-Awadalla/MPT-1B-Redpajama-200b-Dolly | OpenAI Clip Vit-L/14 | 1 | 82.7 | 45,7 | Link |
| 4b | zusammencomputer/redpajama-incite-base-3b-v1 | OpenAI Clip Vit-L/14 | 2 | 81.8 | 49,0 | Link |
| 4b | zusammencomputer/redpajama-incite-instruct-3b-v1 | OpenAI Clip Vit-L/14 | 2 | 85,8 | 49,0 | Link |
| 9b | Anas-Awadalla/MPT-7b | OpenAI Clip Vit-L/14 | 4 | 89.0 | 54,8 | Link |
* Xattn Intervall bezieht sich auf das Argument --cross_attn_every_n_layers .
Hinweis: Im Rahmen unserer V2-Veröffentlichung haben wir einen früheren Checkpoint in Lama veraltet. Sie können jedoch weiterhin unseren älteren Kontrollpunkt mit der neuen Codebasis verwenden.
Um ein OpenFlamingo -Modell mit einem unserer freigegebenen Gewichte zu instanziieren, initialisieren Sie das Modell wie oben und verwenden Sie den folgenden Code.
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )Nachfolgend finden Sie ein Beispiel für die Erzeugung von Text, die auf verschachtelten Bildern/Text konditioniert sind. Probieren wir insbesondere nur wenige Schuss-Bildunterschriften aus.
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ])) Wir bieten Schulungsskripte in open_flamingo/train . Wir geben ein Beispiel für das Slurm -Skript in open_flamingo/scripts/run_train.py sowie den folgenden Beispielbefehl:
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
Hinweis: Die MPT-1B-Basis- und -Bect-Modellierungscode akzeptiert die labels kwarg nicht oder berechnet den Querentropy-Verlust direkt innerhalb von forward() , wie von unserer Codebasis erwartet. Wir empfehlen, eine modifizierte Version der hier und hier gefundenen MPT-1B-Modelle zu verwenden.
Weitere Informationen finden Sie in unserem Training Readme.
Ein Beispiel -Bewertungsskript finden Sie unter open_flamingo/scripts/run_eval.sh . Weitere Informationen finden Sie in unserer Bewertung Readme.
Um Bewertungen auf OKVQA auszuführen, müssen Sie den folgenden Befehl ausführen:
import nltk
nltk.download('wordnet')
OpenFlamingo wird entwickelt von:
Anas Awadalla*, Irena Gao*, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, Ludwig Schmidt.
Das Team ist in erster Linie von der University of Washington, Stanford, AI2, UCSB und Google.
Dieser Code basiert auf Lucidrains 'Flamingo-Implementierung und dem Flamingo-Mini-Repo von David Hansmair. Vielen Dank, dass Sie Ihren Code öffentlich gemacht haben! Wir danken dem OpenClip -Team auch, da wir ihren Datenladungscode verwenden und sich von ihrem Bibliotheksdesign inspirieren lassen.
Wir möchten auch Jean-Baptiste Alayrac und Antoine Miech für ihre Ratschläge, Rohan Taori, Nicholas Schiefer, Deep Ganguli, Thomas Liao, Tatsunori Hashimoto und Nicholas Carlini danken, die die Sicherheitsrisiken zu bewerten, und um uns zu sorgen, um diese Models zu erledigen.
Wenn Sie dieses Repository als nützlich empfanden, sollten Sie sich angeben:
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


